 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch-in-Latents: Eliciting Unified Reasoning in MLLMs
Dec 18, 2025While Multimodal Large Language Models (MLLMs) excel at visual understanding tasks through text reasoning, they often fall short in scenarios requiring visual imagination. Unlike current works that take predefined external toolkits or generate images during thinking, however, humans can form flexible visual-text imagination and interactions during thinking without predefined toolkits, where one important reason is that humans construct the visual-text thinking process in a unified space inside the brain. Inspired by this capability, given that current MLLMs already encode visual and text information in the same feature space, we hold that visual tokens can be seamlessly inserted into the reasoning process carried by text tokens, where ideally, all visual imagination processes can be encoded by the latent features. To achieve this goal, we propose Sketch-in-Latents (SkiLa), a novel paradigm for unified multi-modal reasoning that expands the auto-regressive capabilities of MLLMs to natively generate continuous visual embeddings, termed latent sketch tokens, as visual thoughts. During multi-step reasoning, the model dynamically alternates between textual thinking mode for generating textual think tokens and visual sketching mode for generating latent sketch tokens. A latent visual semantics reconstruction mechanism is proposed to ensure these latent sketch tokens are semantically grounded. Extensive experiments demonstrate that SkiLa achieves superior performance on vision-centric tasks while exhibiting strong generalization to diverse general multi-modal benchmarks. Codes will be released at https://github.com/TungChintao/SkiLa.
HybridGS: Decoupling Transients and Statics with 2D and 3D Gaussian Splatting
Dec 05, 2024



Generating high-quality novel view renderings of 3D Gaussian Splatting (3DGS) in scenes featuring transient objects is challenging. We propose a novel hybrid representation, termed as HybridGS, using 2D Gaussians for transient objects per image and maintaining traditional 3D Gaussians for the whole static scenes. Note that, the 3DGS itself is better suited for modeling static scenes that assume multi-view consistency, but the transient objects appear occasionally and do not adhere to the assumption, thus we model them as planar objects from a single view, represented with 2D Gaussians. Our novel representation decomposes the scene from the perspective of fundamental viewpoint consistency, making it more reasonable. Additionally, we present a novel multi-view regulated supervision method for 3DGS that leverages information from co-visible regions, further enhancing the distinctions between the transients and statics. Then, we propose a straightforward yet effective multi-stage training strategy to ensure robust training and high-quality view synthesis across various settings. Experiments on benchmark datasets show our state-of-the-art performance of novel view synthesis in both indoor and outdoor scenes, even in the presence of distracting elements.
CRIN: Rotation-Invariant Point Cloud Analysis and Rotation Estimation via Centrifugal Reference Frame
Mar 06, 2023Various recent methods attempt to implement rotation-invariant 3D deep learning by replacing the input coordinates of points with relative distances and angles. Due to the incompleteness of these low-level features, they have to undertake the expense of losing global information. In this paper, we propose the CRIN, namely Centrifugal Rotation-Invariant Network. CRIN directly takes the coordinates of points as input and transforms local points into rotation-invariant representations via centrifugal reference frames. Aided by centrifugal reference frames, each point corresponds to a discrete rotation so that the information of rotations can be implicitly stored in point features. Unfortunately, discrete points are far from describing the whole rotation space. We further introduce a continuous distribution for 3D rotations based on points. Furthermore, we propose an attention-based down-sampling strategy to sample points invariant to rotations. A relation module is adopted at last for reinforcing the long-range dependencies between sampled points and predicts the anchor point for unsupervised rotation estimation. Extensive experiments show that our method achieves rotation invariance, accurately estimates the object rotation, and obtains state-of-the-art results on rotation-augmented classification and part segmentation. Ablation studies validate the effectiveness of the network design.
Understanding Pixel-level 2D Image Semantics with 3D Keypoint Knowledge Engine
Nov 21, 2021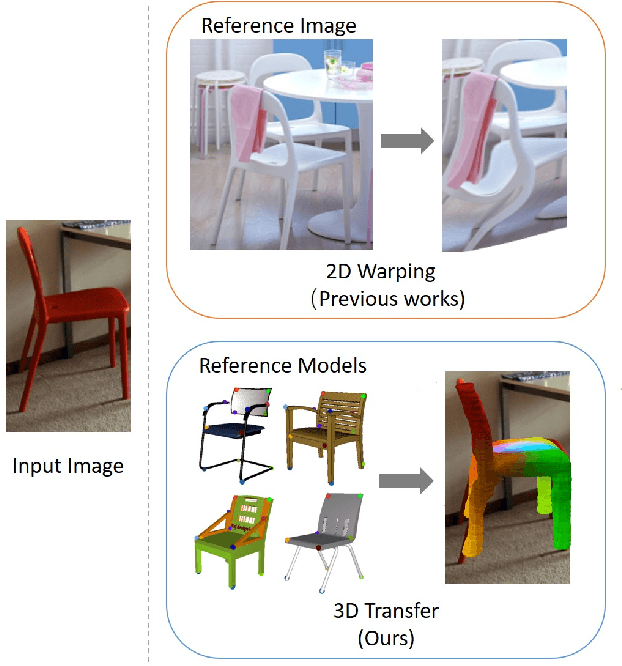

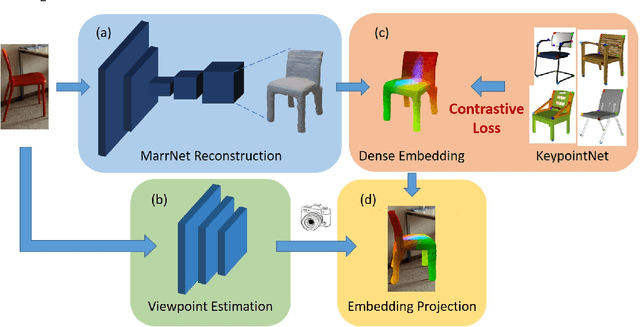

Pixel-level 2D object semantic understanding is an important topic in computer vision and could help machine deeply understand objects (e.g. functionality and affordance) in our daily life. However, most previous methods directly train on correspondences in 2D images, which is end-to-end but loses plenty of information in 3D spaces. In this paper, we propose a new method on predicting image corresponding semantics in 3D domain and then projecting them back onto 2D images to achieve pixel-level understanding. In order to obtain reliable 3D semantic labels that are absent in current image datasets, we build a large scale keypoint knowledge engine called KeypointNet, which contains 103,450 keypoints and 8,234 3D models from 16 object categories. Our method leverages the advantages in 3D vision and can explicitly reason about objects self-occlusion and visibility. We show that our method gives comparative and even superior results on standard semantic benchmarks.
Localization with Sampling-Argmax
Oct 17, 2021
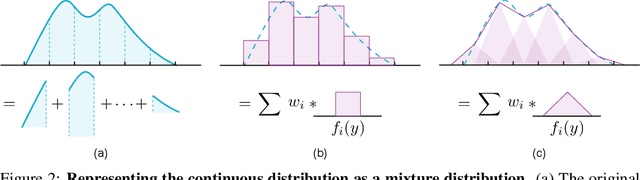
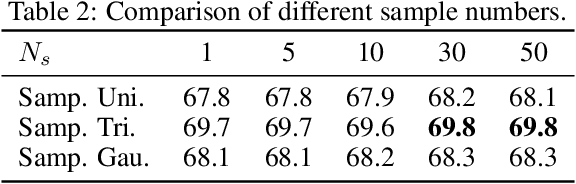

Soft-argmax operation is commonly adopted in detection-based methods to localize the target position in a differentiable manner. However, training the neural network with soft-argmax makes the shape of the probability map unconstrained. Consequently, the model lacks pixel-wise supervision through the map during training, leading to performance degradation. In this work, we propose sampling-argmax, a differentiable training method that imposes implicit constraints to the shape of the probability map by minimizing the expectation of the localization error. To approximate the expectation, we introduce a continuous formulation of the output distribution and develop a differentiable sampling process. The expectation can be approximated by calculating the average error of all samples drawn from the output distribution. We show that sampling-argmax can seamlessly replace the conventional soft-argmax operation on various localization tasks. Comprehensive experiments demonstrate the effectiveness and flexibility of the proposed method. Code is available at https://github.com/Jeff-sjtu/sampling-argmax
PRIN/SPRIN: On Extracting Point-wise Rotation Invariant Features
Feb 24, 2021
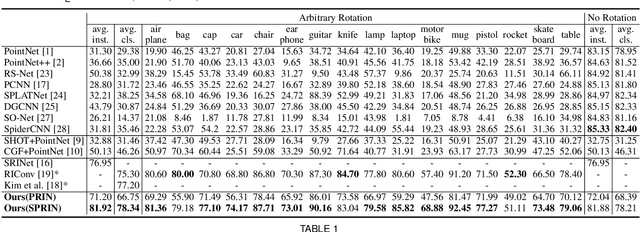


Point cloud analysis without pose priors is very challenging in real applications, as the orientations of point clouds are often unknown. In this paper, we propose a brand new point-set learning framework PRIN, namely, Point-wise Rotation Invariant Network, focusing on rotation invariant feature extraction in point clouds analysis. We construct spherical signals by Density Aware Adaptive Sampling to deal with distorted point distributions in spherical space. Spherical Voxel Convolution and Point Re-sampling are proposed to extract rotation invariant features for each point. In addition, we extend PRIN to a sparse version called SPRIN, which directly operates on sparse point clouds. Both PRIN and SPRIN can be applied to tasks ranging from object classification, part segmentation, to 3D feature matching and label alignment. Results show that, on the dataset with randomly rotated point clouds, SPRIN demonstrates better performance than state-of-the-art methods without any data augmentation. We also provide thorough theoretical proof and analysis for point-wise rotation invariance achieved by our methods. Our code is available on https://github.com/qq456cvb/SPRIN.
Canonical Voting: Towards Robust Oriented Bounding Box Detection in 3D Scenes
Nov 24, 2020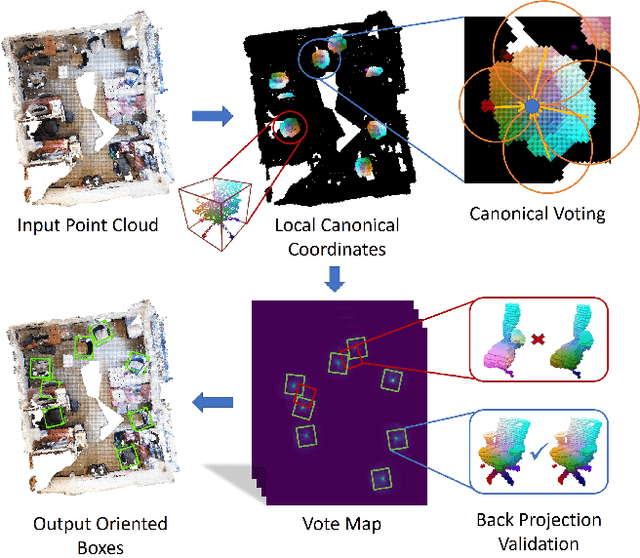

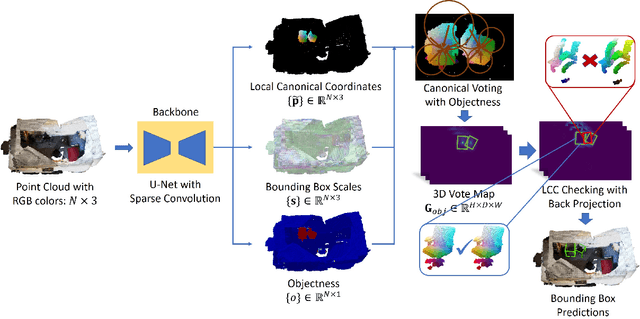
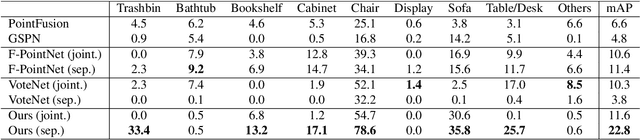
3D object detection has attracted much attention thanks to the advances in sensors and deep learning methods for point clouds. Current state-of-the-art methods like VoteNet regress direct offset towards object centers and box orientations with an additional Multi-Layer-Perceptron network. Both their offset and orientation predictions are not accurate due to the fundamental difficulty in rotation classification. In the work, we disentangle the direct offset into Local Canonical Coordinates (LCC), box scales and box orientations. Only LCC and box scales are regressed while box orientations are generated by a canonical voting scheme. Finally, a LCC-aware back-projection checking algorithm iteratively cuts out bounding boxes from the generated vote maps, with the elimination of false positives. Our model achieves state-of-the-art performance on challenging large-scale datasets of real point cloud scans: ScanNet, SceneNN with 11.4 and 5.3 mAP improvement respectively. Code is available on https://github.com/qq456cvb/CanonicalVoting.
Semantic Correspondence via 2D-3D-2D Cycle
Apr 20, 2020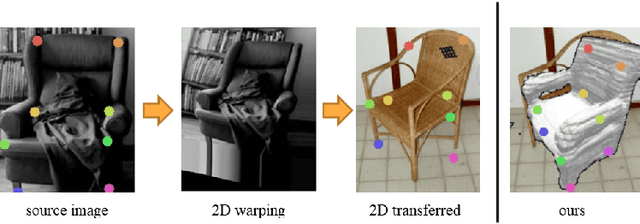
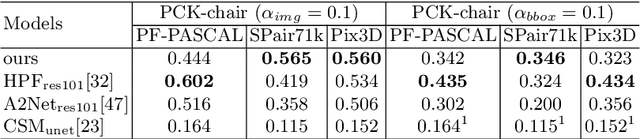
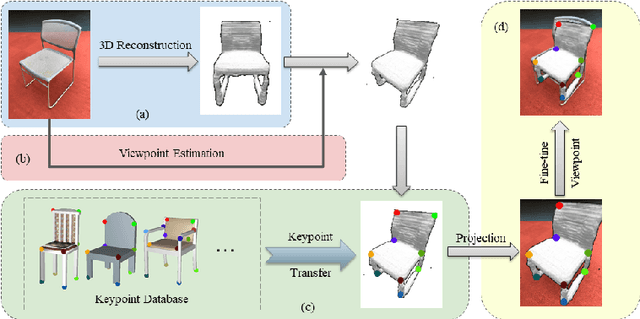

Visual semantic correspondence is an important topic in computer vision and could help machine understand objects in our daily life. However, most previous methods directly train on correspondences in 2D images, which is end-to-end but loses plenty of information in 3D spaces. In this paper, we propose a new method on predicting semantic correspondences by leveraging it to 3D domain and then project corresponding 3D models back to 2D domain, with their semantic labels. Our method leverages the advantages in 3D vision and can explicitly reason about objects self-occlusion and visibility. We show that our method gives comparative and even superior results on standard semantic benchmarks. We also conduct thorough and detailed experiments to analyze our network components. The code and experiments are publicly available at https://github.com/qq456cvb/SemanticTransfer.
KeypointNet: A Large-scale 3D Keypoint Dataset Aggregated from Numerous Human Annotations
Mar 21, 2020

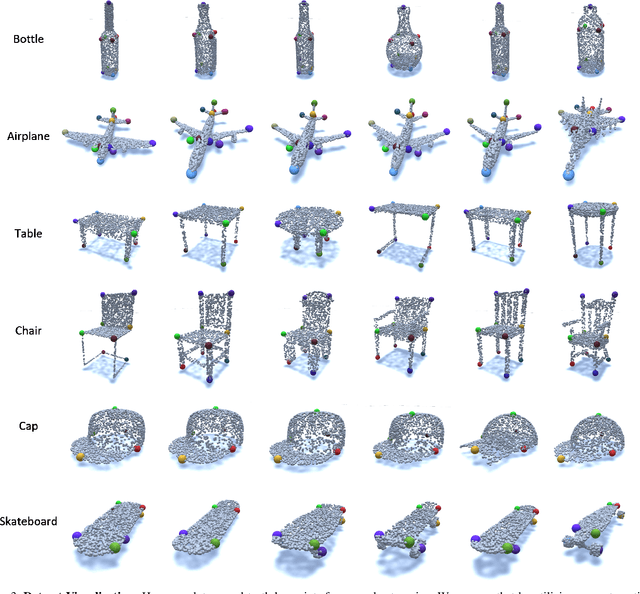
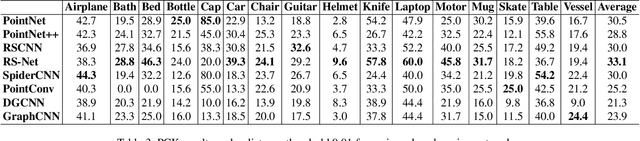
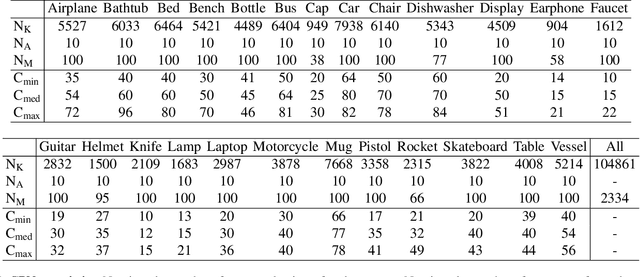
Detecting 3D objects keypoints is of great interest to the areas of both graphics and computer vision. There have been several 2D and 3D keypoint datasets aiming to address this problem in a data-driven way. These datasets, however, either lack scalability or bring ambiguity to the definition of keypoints. Therefore, we present KeypointNet: the first large-scale and diverse 3D keypoint dataset that contains 83,231 keypoints and 8,329 3D models from 16 object categories, by leveraging numerous human annotations. To handle the inconsistency between annotations from different people, we propose a novel method to aggregate these keypoints automatically, through minimization of a fidelity loss. Finally, ten state-of-the-art methods are benchmarked on our proposed dataset.
Fine-grained Object Semantic Understanding from Correspondences
Dec 29, 2019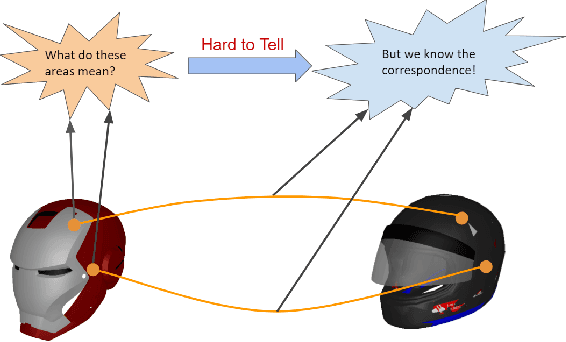
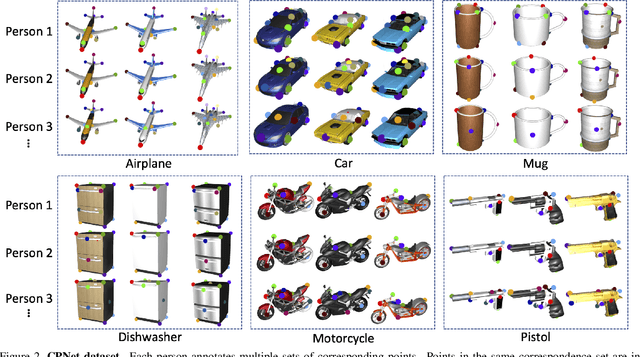
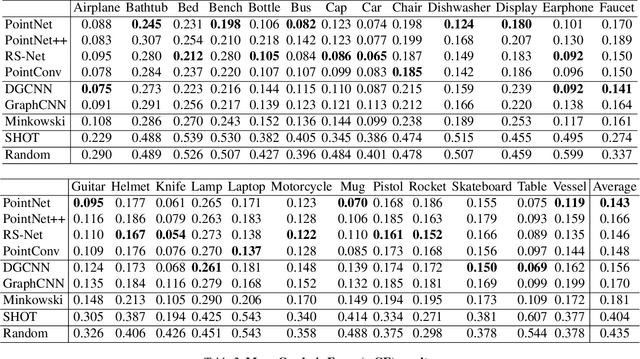
Fine-grained semantic understanding of 3D objects is crucial in many applications such as object manipulation. However, it is hard to give a universal definition of point-level semantics that everyone would agree on. We observe that people are pretty sure about semantic correspondences between two areas from different objects, but less certain about what each area means in semantics. Therefore, we argue that by providing human labeled correspondences between different objects from the same category, one can recover rich semantic information of an object. In this paper, we propose a method that outputs dense semantic embeddings based on a novel geodesic consistency loss. Accordingly, a new dataset named CorresPondenceNet and its corresponding benchmark are designed. Several state-of-the-art networks are evaluated based on our proposed method. We show that our method could boost the fine-grained understanding of heterogeneous objects and the inference of dense semantic information is possible.