 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Compact Latent Space for Representing Neural Signed Distance Functions with High-fidelity Geometry Details
Nov 18, 2025Neural signed distance functions (SDFs) have been a vital representation to represent 3D shapes or scenes with neural networks. An SDF is an implicit function that can query signed distances at specific coordinates for recovering a 3D surface. Although implicit functions work well on a single shape or scene, they pose obstacles when analyzing multiple SDFs with high-fidelity geometry details, due to the limited information encoded in the latent space for SDFs and the loss of geometry details. To overcome these obstacles, we introduce a method to represent multiple SDFs in a common space, aiming to recover more high-fidelity geometry details with more compact latent representations. Our key idea is to take full advantage of the benefits of generalization-based and overfitting-based learning strategies, which manage to preserve high-fidelity geometry details with compact latent codes. Based on this framework, we also introduce a novel sampling strategy to sample training queries. The sampling can improve the training efficiency and eliminate artifacts caused by the influence of other SDFs. We report numerical and visual evaluations on widely used benchmarks to validate our designs and show advantages over the latest methods in terms of the representative ability and compactness.
CAGE: Continuity-Aware edGE Network Unlocks Robust Floorplan Reconstruction
Sep 18, 2025We present \textbf{CAGE} (\textit{Continuity-Aware edGE}) network, a \textcolor{red}{robust} framework for reconstructing vector floorplans directly from point-cloud density maps. Traditional corner-based polygon representations are highly sensitive to noise and incomplete observations, often resulting in fragmented or implausible layouts. Recent line grouping methods leverage structural cues to improve robustness but still struggle to recover fine geometric details. To address these limitations, we propose a \textit{native} edge-centric formulation, modeling each wall segment as a directed, geometrically continuous edge. This representation enables inference of coherent floorplan structures, ensuring watertight, topologically valid room boundaries while improving robustness and reducing artifacts. Towards this design, we develop a dual-query transformer decoder that integrates perturbed and latent queries within a denoising framework, which not only stabilizes optimization but also accelerates convergence. Extensive experiments on Structured3D and SceneCAD show that \textbf{CAGE} achieves state-of-the-art performance, with F1 scores of 99.1\% (rooms), 91.7\% (corners), and 89.3\% (angles). The method also demonstrates strong cross-dataset generalization, underscoring the efficacy of our architectural innovations. Code and pretrained models will be released upon acceptance.
Glossy Object Reconstruction with Cost-effective Polarized Acquisition
Apr 09, 2025



The challenge of image-based 3D reconstruction for glossy objects lies in separating diffuse and specular components on glossy surfaces from captured images, a task complicated by the ambiguity in discerning lighting conditions and material properties using RGB data alone. While state-of-the-art methods rely on tailored and/or high-end equipment for data acquisition, which can be cumbersome and time-consuming, this work introduces a scalable polarization-aided approach that employs cost-effective acquisition tools. By attaching a linear polarizer to readily available RGB cameras, multi-view polarization images can be captured without the need for advance calibration or precise measurements of the polarizer angle, substantially reducing system construction costs. The proposed approach represents polarimetric BRDF, Stokes vectors, and polarization states of object surfaces as neural implicit fields. These fields, combined with the polarizer angle, are retrieved by optimizing the rendering loss of input polarized images. By leveraging fundamental physical principles for the implicit representation of polarization rendering, our method demonstrates superiority over existing techniques through experiments in public datasets and real captured images on both reconstruction and novel view synthesis.
No Parameters, No Problem: 3D Gaussian Splatting without Camera Intrinsics and Extrinsics
Feb 27, 2025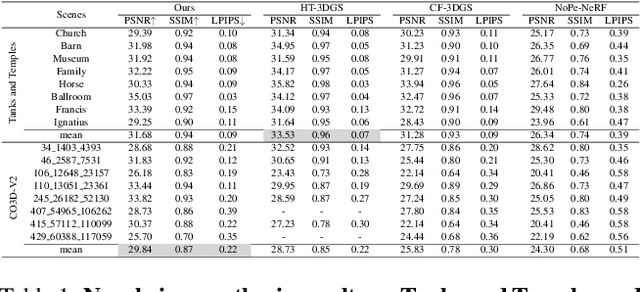
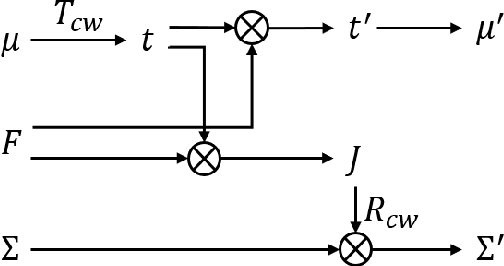
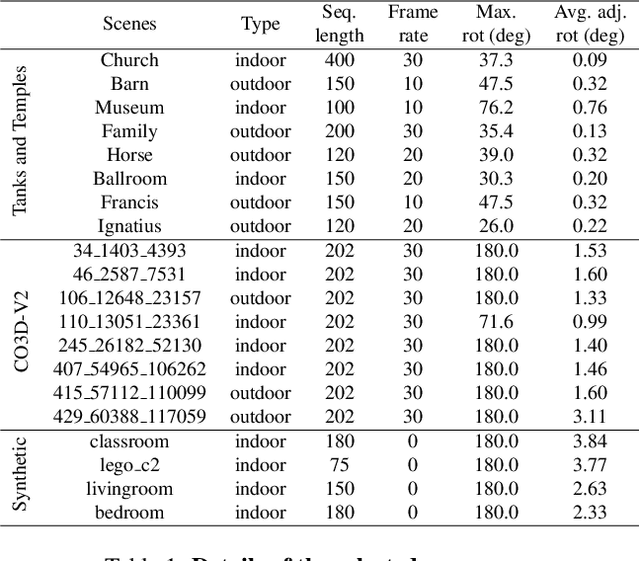
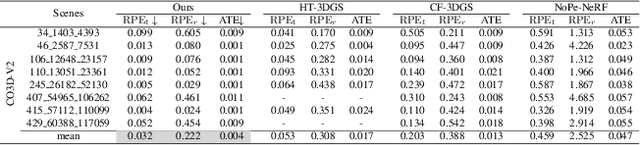
While 3D Gaussian Splatting (3DGS) has made significant progress in scene reconstruction and novel view synthesis, it still heavily relies on accurately pre-computed camera intrinsics and extrinsics, such as focal length and camera poses. In order to mitigate this dependency, the previous efforts have focused on optimizing 3DGS without the need for camera poses, yet camera intrinsics remain necessary. To further loose the requirement, we propose a joint optimization method to train 3DGS from an image collection without requiring either camera intrinsics or extrinsics. To achieve this goal, we introduce several key improvements during the joint training of 3DGS. We theoretically derive the gradient of the camera intrinsics, allowing the camera intrinsics to be optimized simultaneously during training. Moreover, we integrate global track information and select the Gaussian kernels associated with each track, which will be trained and automatically rescaled to an infinitesimally small size, closely approximating surface points, and focusing on enforcing multi-view consistency and minimizing reprojection errors, while the remaining kernels continue to serve their original roles. This hybrid training strategy nicely unifies the camera parameters estimation and 3DGS training. Extensive evaluations demonstrate that the proposed method achieves state-of-the-art (SOTA) performance on both public and synthetic datasets.
PTZ-Calib: Robust Pan-Tilt-Zoom Camera Calibration
Feb 13, 2025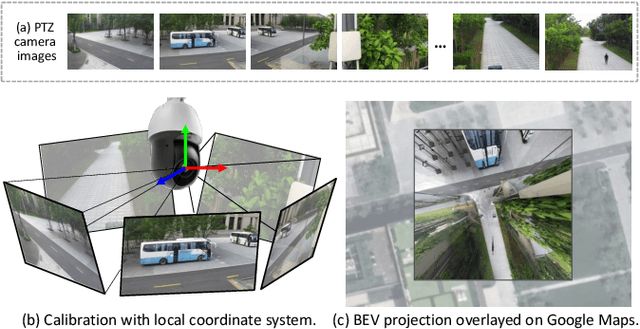
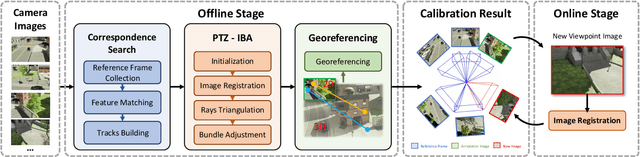
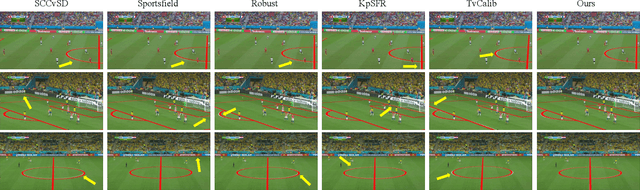
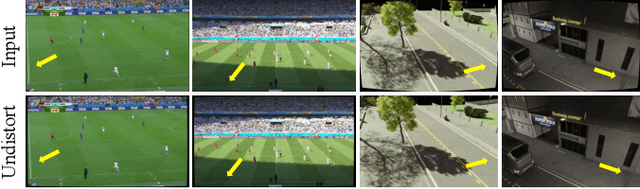
In this paper, we present PTZ-Calib, a robust two-stage PTZ camera calibration method, that efficiently and accurately estimates camera parameters for arbitrary viewpoints. Our method includes an offline and an online stage. In the offline stage, we first uniformly select a set of reference images that sufficiently overlap to encompass a complete 360{\deg} view. We then utilize the novel PTZ-IBA (PTZ Incremental Bundle Adjustment) algorithm to automatically calibrate the cameras within a local coordinate system. Additionally, for practical application, we can further optimize camera parameters and align them with the geographic coordinate system using extra global reference 3D information. In the online stage, we formulate the calibration of any new viewpoints as a relocalization problem. Our approach balances the accuracy and computational efficiency to meet real-world demands. Extensive evaluations demonstrate our robustness and superior performance over state-of-the-art methods on various real and synthetic datasets. Datasets and source code can be accessed online at https://github.com/gjgjh/PTZ-Calib
CoL3D: Collaborative Learning of Single-view Depth and Camera Intrinsics for Metric 3D Shape Recovery
Feb 13, 2025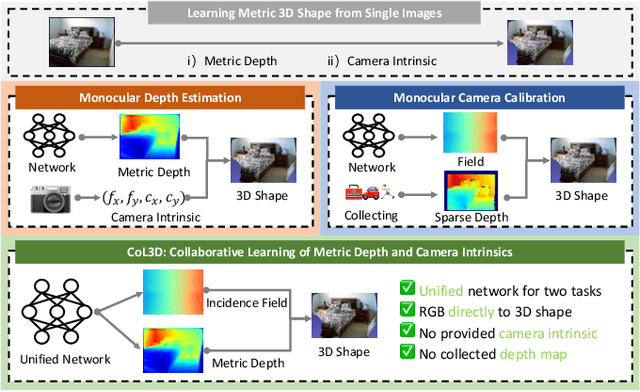
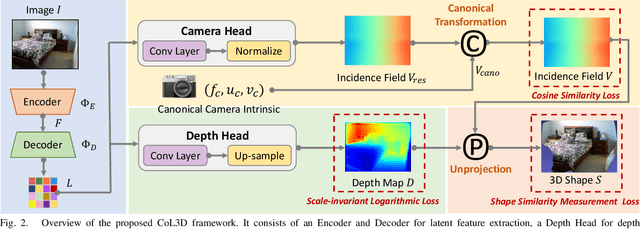


Recovering the metric 3D shape from a single image is particularly relevant for robotics and embodied intelligence applications, where accurate spatial understanding is crucial for navigation and interaction with environments. Usually, the mainstream approaches achieve it through monocular depth estimation. However, without camera intrinsics, the 3D metric shape can not be recovered from depth alone. In this study, we theoretically demonstrate that depth serves as a 3D prior constraint for estimating camera intrinsics and uncover the reciprocal relations between these two elements. Motivated by this, we propose a collaborative learning framework for jointly estimating depth and camera intrinsics, named CoL3D, to learn metric 3D shapes from single images. Specifically, CoL3D adopts a unified network and performs collaborative optimization at three levels: depth, camera intrinsics, and 3D point clouds. For camera intrinsics, we design a canonical incidence field mechanism as a prior that enables the model to learn the residual incident field for enhanced calibration. Additionally, we incorporate a shape similarity measurement loss in the point cloud space, which improves the quality of 3D shapes essential for robotic applications. As a result, when training and testing on a single dataset with in-domain settings, CoL3D delivers outstanding performance in both depth estimation and camera calibration across several indoor and outdoor benchmark datasets, which leads to remarkable 3D shape quality for the perception capabilities of robots.
HybridGS: Decoupling Transients and Statics with 2D and 3D Gaussian Splatting
Dec 05, 2024



Generating high-quality novel view renderings of 3D Gaussian Splatting (3DGS) in scenes featuring transient objects is challenging. We propose a novel hybrid representation, termed as HybridGS, using 2D Gaussians for transient objects per image and maintaining traditional 3D Gaussians for the whole static scenes. Note that, the 3DGS itself is better suited for modeling static scenes that assume multi-view consistency, but the transient objects appear occasionally and do not adhere to the assumption, thus we model them as planar objects from a single view, represented with 2D Gaussians. Our novel representation decomposes the scene from the perspective of fundamental viewpoint consistency, making it more reasonable. Additionally, we present a novel multi-view regulated supervision method for 3DGS that leverages information from co-visible regions, further enhancing the distinctions between the transients and statics. Then, we propose a straightforward yet effective multi-stage training strategy to ensure robust training and high-quality view synthesis across various settings. Experiments on benchmark datasets show our state-of-the-art performance of novel view synthesis in both indoor and outdoor scenes, even in the presence of distracting elements.
Learning Neural Volumetric Pose Features for Camera Localization
Mar 19, 2024



We introduce a novel neural volumetric pose feature, termed PoseMap, designed to enhance camera localization by encapsulating the information between images and the associated camera poses. Our framework leverages an Absolute Pose Regression (APR) architecture, together with an augmented NeRF module. This integration not only facilitates the generation of novel views to enrich the training dataset but also enables the learning of effective pose features. Additionally, we extend our architecture for self-supervised online alignment, allowing our method to be used and fine-tuned for unlabelled images within a unified framework. Experiments demonstrate that our method achieves 14.28% and 20.51% performance gain on average in indoor and outdoor benchmark scenes, outperforming existing APR methods with state-of-the-art accuracy.
Homography Loss for Monocular 3D Object Detection
Apr 02, 2022
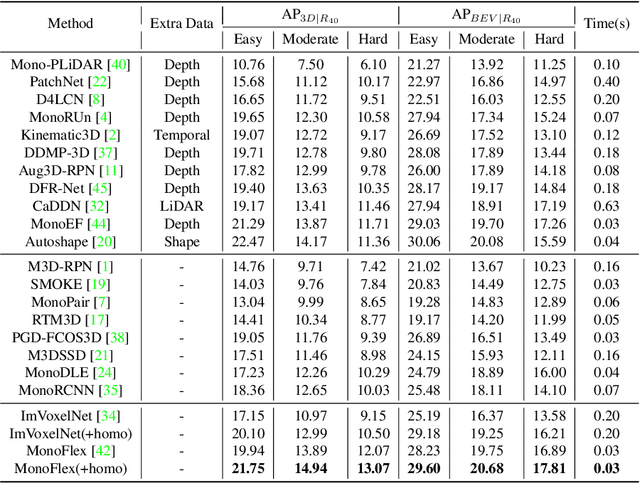
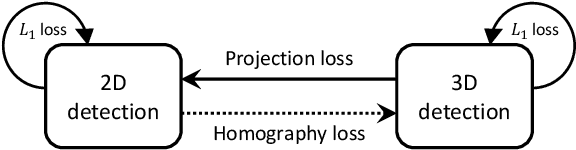
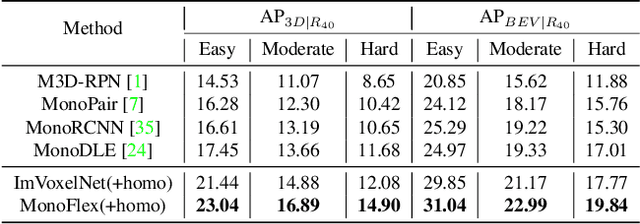
Monocular 3D object detection is an essential task in autonomous driving. However, most current methods consider each 3D object in the scene as an independent training sample, while ignoring their inherent geometric relations, thus inevitably resulting in a lack of leveraging spatial constraints. In this paper, we propose a novel method that takes all the objects into consideration and explores their mutual relationships to help better estimate the 3D boxes. Moreover, since 2D detection is more reliable currently, we also investigate how to use the detected 2D boxes as guidance to globally constrain the optimization of the corresponding predicted 3D boxes. To this end, a differentiable loss function, termed as Homography Loss, is proposed to achieve the goal, which exploits both 2D and 3D information, aiming at balancing the positional relationships between different objects by global constraints, so as to obtain more accurately predicted 3D boxes. Thanks to the concise design, our loss function is universal and can be plugged into any mature monocular 3D detector, while significantly boosting the performance over their baseline. Experiments demonstrate that our method yields the best performance (Nov. 2021) compared with the other state-of-the-arts by a large margin on KITTI 3D datasets.
Part2Word: Learning Joint Embedding of Point Clouds and Text by Matching Parts to Words
Jul 05, 2021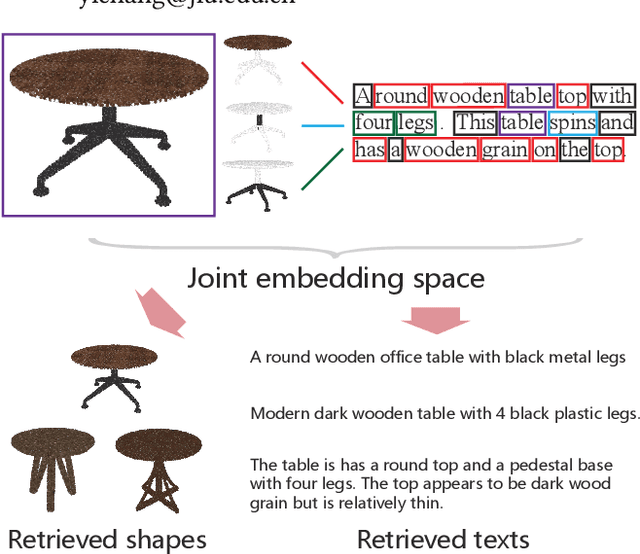
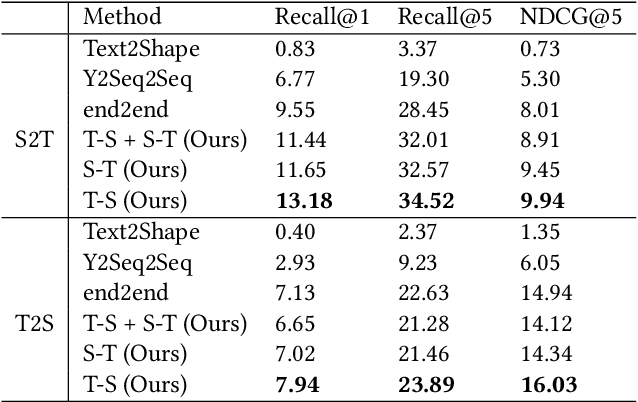
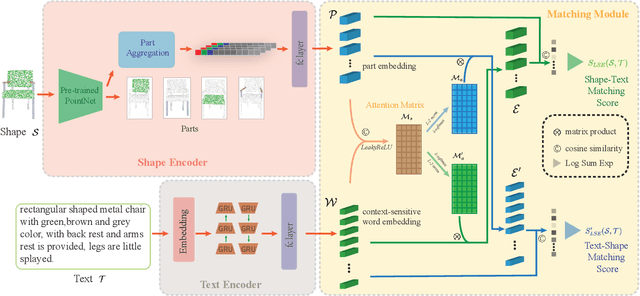
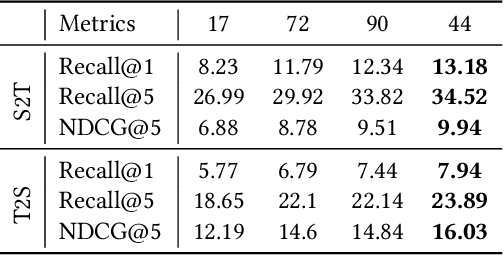
It is important to learn joint embedding for 3D shapes and text in different shape understanding tasks, such as shape-text matching, retrieval, and shape captioning. Current multi-view based methods learn a mapping from multiple rendered views to text. However, these methods can not analyze 3D shapes well due to the self-occlusion and limitation of learning manifolds. To resolve this issue, we propose a method to learn joint embedding of point clouds and text by matching parts from shapes to words from sentences in a common space. Specifically, we first learn segmentation prior to segment point clouds into parts. Then, we map parts and words into an optimized space, where the parts and words can be matched with each other. In the optimized space, we represent a part by aggregating features of all points within the part, while representing each word with its context information, where we train our network to minimize the triplet ranking loss. Moreover, we also introduce cross-modal attention to capture the relationship of part-word in this matching procedure, which enhances joint embedding learning. Our experimental results outperform the state-of-the-art in multi-modal retrieval under the widely used benchmark.