 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSIS: Efficient One-stage Network for 3D Instance Segmentation
Mar 13, 2023



Current 3D instance segmentation models generally use multi-stage methods to extract instance objects, including clustering, feature extraction, and post-processing processes. However, these multi-stage approaches rely on hyperparameter settings and hand-crafted processes, which restrict the inference speed of the model. In this paper, we propose a new 3D point cloud instance segmentation network, named OSIS. OSIS is a one-stage network, which directly segments instances from 3D point cloud data using neural network. To segment instances directly from the network, we propose an instance decoder, which decodes instance features from the network into instance segments. Our proposed OSIS realizes the end-to-end training by bipartite matching, therefore, our network does not require computationally expensive post-processing steps such as non maximum suppression (NMS) and clustering during inference. The results show that our network finally achieves excellent performance in the commonly used indoor scene instance segmentation dataset, and the inference speed of our network is only an average of 138ms per scene, which substantially exceeds the previous fastest method.
Part2Word: Learning Joint Embedding of Point Clouds and Text by Matching Parts to Words
Jul 05, 2021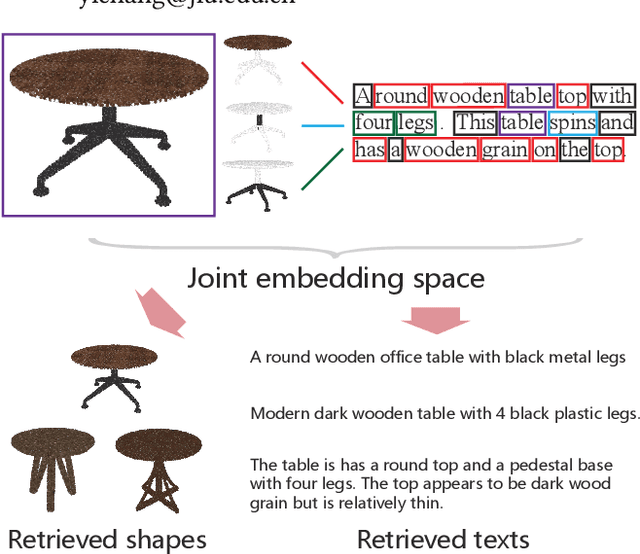
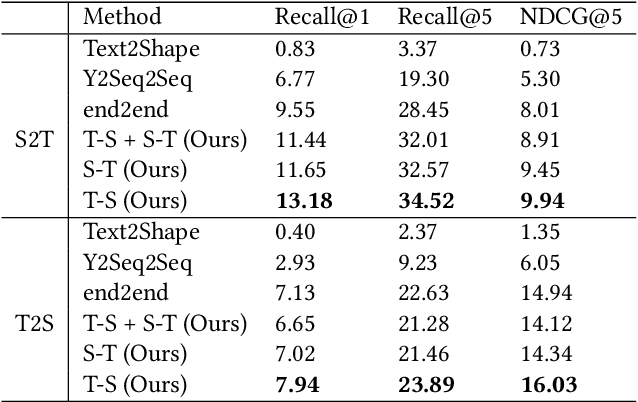
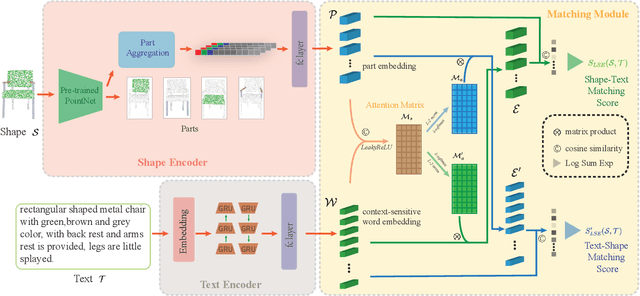
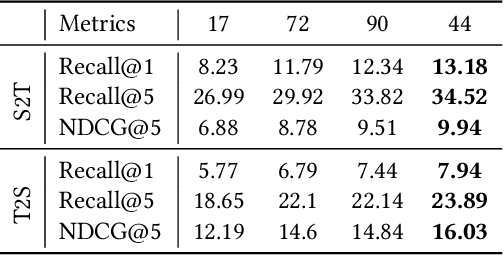
It is important to learn joint embedding for 3D shapes and text in different shape understanding tasks, such as shape-text matching, retrieval, and shape captioning. Current multi-view based methods learn a mapping from multiple rendered views to text. However, these methods can not analyze 3D shapes well due to the self-occlusion and limitation of learning manifolds. To resolve this issue, we propose a method to learn joint embedding of point clouds and text by matching parts from shapes to words from sentences in a common space. Specifically, we first learn segmentation prior to segment point clouds into parts. Then, we map parts and words into an optimized space, where the parts and words can be matched with each other. In the optimized space, we represent a part by aggregating features of all points within the part, while representing each word with its context information, where we train our network to minimize the triplet ranking loss. Moreover, we also introduce cross-modal attention to capture the relationship of part-word in this matching procedure, which enhances joint embedding learning. Our experimental results outperform the state-of-the-art in multi-modal retrieval under the widely used benchmark.