 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart2Word: Learning Joint Embedding of Point Clouds and Text by Matching Parts to Words
Paper and Code
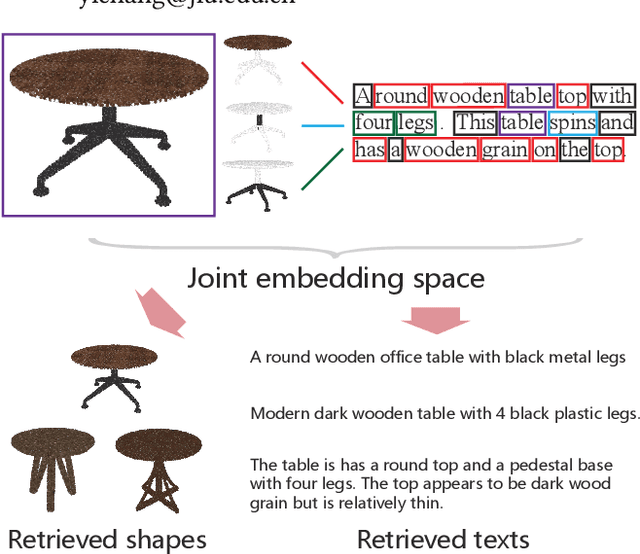
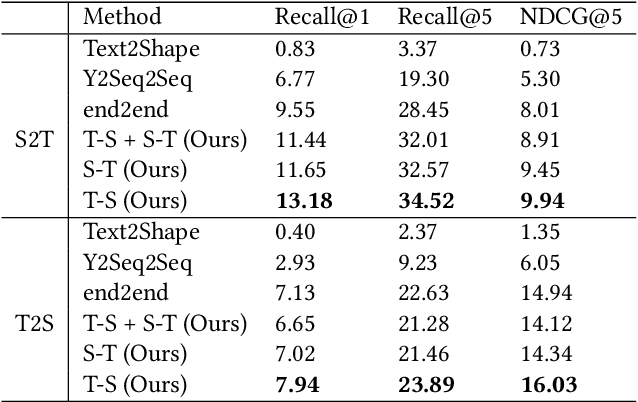
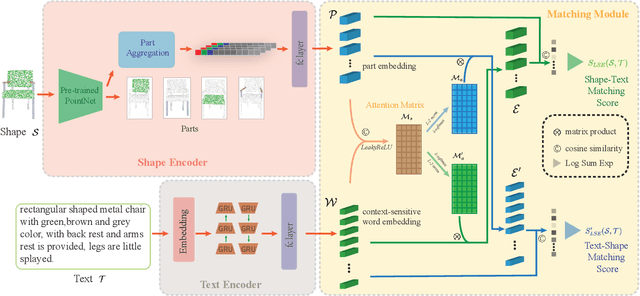
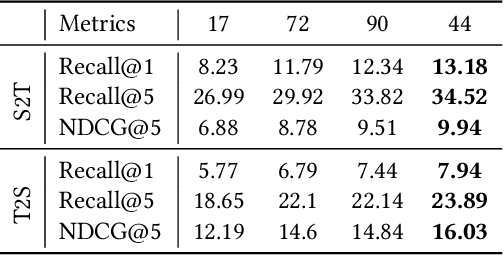
It is important to learn joint embedding for 3D shapes and text in different shape understanding tasks, such as shape-text matching, retrieval, and shape captioning. Current multi-view based methods learn a mapping from multiple rendered views to text. However, these methods can not analyze 3D shapes well due to the self-occlusion and limitation of learning manifolds. To resolve this issue, we propose a method to learn joint embedding of point clouds and text by matching parts from shapes to words from sentences in a common space. Specifically, we first learn segmentation prior to segment point clouds into parts. Then, we map parts and words into an optimized space, where the parts and words can be matched with each other. In the optimized space, we represent a part by aggregating features of all points within the part, while representing each word with its context information, where we train our network to minimize the triplet ranking loss. Moreover, we also introduce cross-modal attention to capture the relationship of part-word in this matching procedure, which enhances joint embedding learning. Our experimental results outperform the state-of-the-art in multi-modal retrieval under the widely used benchmark.