 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGAD-SLAM: Splatting Gaussians at Adjusted Depth for Better Radiance Fields in RGBD SLAM
Mar 22, 20263D Gaussian Splatting (3DGS) has made remarkable progress in RGBD SLAM. Current methods usually use 3D Gaussians or view-tied 3D Gaussians to represent radiance fields in tracking and mapping. However, these Gaussians are either too flexible or too limited in movements, resulting in slow convergence or limited rendering quality. To resolve this issue, we adopt pixel-aligned Gaussians but allow each Gaussian to adjust its position along its ray to maximize the rendering quality, even if Gaussians are simplified to improve system scalability. To speed up the tracking, we model the depth distribution around each pixel as a Gaussian distribution, and then use these distributions to align each frame to the 3D scene quickly. We report our evaluations on widely used benchmarks, justify our designs, and show advantages over the latest methods in view rendering, camera tracking, runtime, and storage complexity. Please see our project page for code and videos at https://machineperceptionlab.github.io/SGAD-SLAM-Project .
3D Gaussian Splatting with Self-Constrained Priors for High Fidelity Surface Reconstruction
Mar 20, 2026Rendering 3D surfaces has been revolutionized within the modeling of radiance fields through either 3DGS or NeRF. Although 3DGS has shown advantages over NeRF in terms of rendering quality or speed, there is still room for improvement in recovering high fidelity surfaces through 3DGS. To resolve this issue, we propose a self-constrained prior to constrain the learning of 3D Gaussians, aiming for more accurate depth rendering. Our self-constrained prior is derived from a TSDF grid that is obtained by fusing the depth maps rendered with current 3D Gaussians. The prior measures a distance field around the estimated surface, offering a band centered at the surface for imposing more specific constraints on 3D Gaussians, such as removing Gaussians outside the band, moving Gaussians closer to the surface, and encouraging larger or smaller opacity in a geometry-aware manner. More importantly, our prior can be regularly updated by the most recent depth images which are usually more accurate and complete. In addition, the prior can also progressively narrow the band to tighten the imposed constraints. We justify our idea and report our superiority over the state-of-the-art methods in evaluations on widely used benchmarks.
Speeding Up the Learning of 3D Gaussians with Much Shorter Gaussian Lists
Mar 10, 20263D Gaussian splatting (3DGS) has become a vital tool for learning a radiance field from multiple posed images. Although 3DGS shows great advantages over NeRF in terms of rendering quality and efficiency, it remains a research challenge to further improve the efficiency of learning 3D Gaussians. To overcome this challenge, we propose novel training strategies and losses to shorten each Gaussian list used to render a pixel, which speeds up the splatting by involving fewer Gaussians along a ray. Specifically, we shrink the size of each Gaussian by resetting their scales regularly, encouraging smaller Gaussians to cover fewer nearby pixels, which shortens the Gaussian lists of pixels. Additionally, we introduce an entropy constraint on the alpha blending procedure to sharpen the weight distribution of Gaussians along each ray, which drives dominant weights larger while making minor weights smaller. As a result, each Gaussian becomes more focused on the pixels where it is dominant, which reduces its impact on nearby pixels, leading to even shorter Gaussian lists. Eventually, we integrate our method into a rendering resolution scheduler which further improves efficiency through progressive resolution increase. We evaluate our method by comparing it with state-of-the-art methods on widely used benchmarks. Our results show significant advantages over others in efficiency without sacrificing rendering quality.
Learning Compact Latent Space for Representing Neural Signed Distance Functions with High-fidelity Geometry Details
Nov 18, 2025Neural signed distance functions (SDFs) have been a vital representation to represent 3D shapes or scenes with neural networks. An SDF is an implicit function that can query signed distances at specific coordinates for recovering a 3D surface. Although implicit functions work well on a single shape or scene, they pose obstacles when analyzing multiple SDFs with high-fidelity geometry details, due to the limited information encoded in the latent space for SDFs and the loss of geometry details. To overcome these obstacles, we introduce a method to represent multiple SDFs in a common space, aiming to recover more high-fidelity geometry details with more compact latent representations. Our key idea is to take full advantage of the benefits of generalization-based and overfitting-based learning strategies, which manage to preserve high-fidelity geometry details with compact latent codes. Based on this framework, we also introduce a novel sampling strategy to sample training queries. The sampling can improve the training efficiency and eliminate artifacts caused by the influence of other SDFs. We report numerical and visual evaluations on widely used benchmarks to validate our designs and show advantages over the latest methods in terms of the representative ability and compactness.
Learning Bijective Surface Parameterization for Inferring Signed Distance Functions from Sparse Point Clouds with Grid Deformation
Mar 31, 2025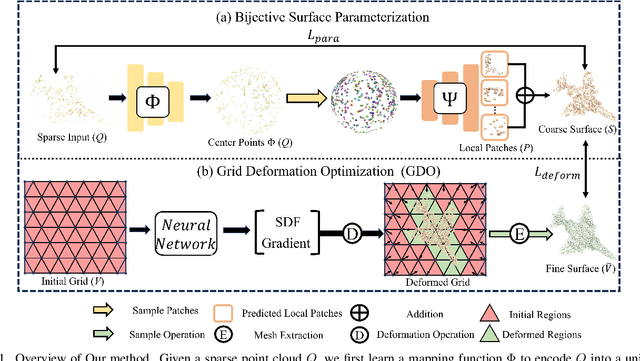
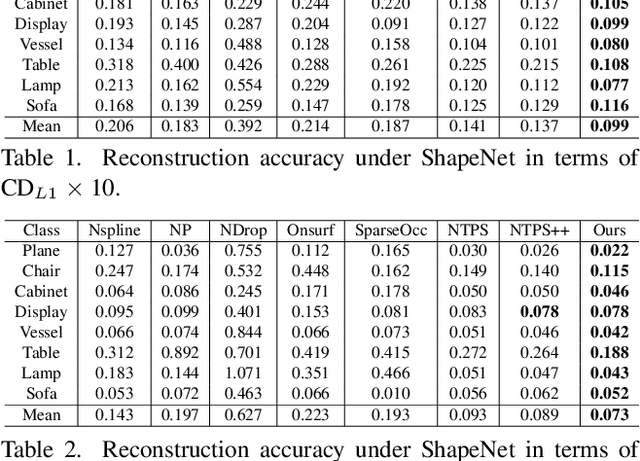
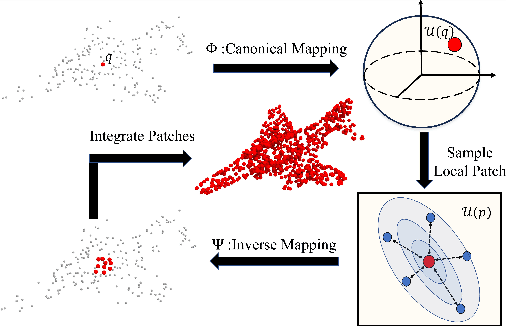
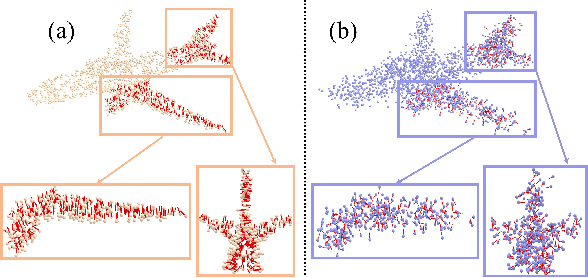
Inferring signed distance functions (SDFs) from sparse point clouds remains a challenge in surface reconstruction. The key lies in the lack of detailed geometric information in sparse point clouds, which is essential for learning a continuous field. To resolve this issue, we present a novel approach that learns a dynamic deformation network to predict SDFs in an end-to-end manner. To parameterize a continuous surface from sparse points, we propose a bijective surface parameterization (BSP) that learns the global shape from local patches. Specifically, we construct a bijective mapping for sparse points from the parametric domain to 3D local patches, integrating patches into the global surface. Meanwhile, we introduce grid deformation optimization (GDO) into the surface approximation to optimize the deformation of grid points and further refine the parametric surfaces. Experimental results on synthetic and real scanned datasets demonstrate that our method significantly outperforms the current state-of-the-art methods. Project page: https://takeshie.github.io/Bijective-SDF
GaussianUDF: Inferring Unsigned Distance Functions through 3D Gaussian Splatting
Mar 25, 2025Reconstructing open surfaces from multi-view images is vital in digitalizing complex objects in daily life. A widely used strategy is to learn unsigned distance functions (UDFs) by checking if their appearance conforms to the image observations through neural rendering. However, it is still hard to learn continuous and implicit UDF representations through 3D Gaussians splatting (3DGS) due to the discrete and explicit scene representation, i.e., 3D Gaussians. To resolve this issue, we propose a novel approach to bridge the gap between 3D Gaussians and UDFs. Our key idea is to overfit thin and flat 2D Gaussian planes on surfaces, and then, leverage the self-supervision and gradient-based inference to supervise unsigned distances in both near and far area to surfaces. To this end, we introduce novel constraints and strategies to constrain the learning of 2D Gaussians to pursue more stable optimization and more reliable self-supervision, addressing the challenges brought by complicated gradient field on or near the zero level set of UDFs. We report numerical and visual comparisons with the state-of-the-art on widely used benchmarks and real data to show our advantages in terms of accuracy, efficiency, completeness, and sharpness of reconstructed open surfaces with boundaries. Project page: https://lisj575.github.io/GaussianUDF/
Sharpening Neural Implicit Functions with Frequency Consolidation Priors
Dec 27, 2024



Signed Distance Functions (SDFs) are vital implicit representations to represent high fidelity 3D surfaces. Current methods mainly leverage a neural network to learn an SDF from various supervisions including signed distances, 3D point clouds, or multi-view images. However, due to various reasons including the bias of neural network on low frequency content, 3D unaware sampling, sparsity in point clouds, or low resolutions of images, neural implicit representations still struggle to represent geometries with high frequency components like sharp structures, especially for the ones learned from images or point clouds. To overcome this challenge, we introduce a method to sharpen a low frequency SDF observation by recovering its high frequency components, pursuing a sharper and more complete surface. Our key idea is to learn a mapping from a low frequency observation to a full frequency coverage in a data-driven manner, leading to a prior knowledge of shape consolidation in the frequency domain, dubbed frequency consolidation priors. To better generalize a learned prior to unseen shapes, we introduce to represent frequency components as embeddings and disentangle the embedding of the low frequency component from the embedding of the full frequency component. This disentanglement allows the prior to generalize on an unseen low frequency observation by simply recovering its full frequency embedding through a test-time self-reconstruction. Our evaluations under widely used benchmarks or real scenes show that our method can recover high frequency component and produce more accurate surfaces than the latest methods. The code, data, and pre-trained models are available at \url{https://github.com/chenchao15/FCP}.
Sensing Surface Patches in Volume Rendering for Inferring Signed Distance Functions
Dec 21, 2024


It is vital to recover 3D geometry from multi-view RGB images in many 3D computer vision tasks. The latest methods infer the geometry represented as a signed distance field by minimizing the rendering error on the field through volume rendering. However, it is still challenging to explicitly impose constraints on surfaces for inferring more geometry details due to the limited ability of sensing surfaces in volume rendering. To resolve this problem, we introduce a method to infer signed distance functions (SDFs) with a better sense of surfaces through volume rendering. Using the gradients and signed distances, we establish a small surface patch centered at the estimated intersection along a ray by pulling points randomly sampled nearby. Hence, we are able to explicitly impose surface constraints on the sensed surface patch, such as multi-view photo consistency and supervision from depth or normal priors, through volume rendering. We evaluate our method by numerical and visual comparisons on scene benchmarks. Our superiority over the latest methods justifies our effectiveness.
Query Quantized Neural SLAM
Dec 21, 2024



Neural implicit representations have shown remarkable abilities in jointly modeling geometry, color, and camera poses in simultaneous localization and mapping (SLAM). Current methods use coordinates, positional encodings, or other geometry features as input to query neural implicit functions for signed distances and color which produce rendering errors to drive the optimization in overfitting image observations. However, due to the run time efficiency requirement in SLAM systems, we are merely allowed to conduct optimization on each frame in few iterations, which is far from enough for neural networks to overfit these queries. The underfitting usually results in severe drifts in camera tracking and artifacts in reconstruction. To resolve this issue, we propose query quantized neural SLAM which uses quantized queries to reduce variations of input for much easier and faster overfitting a frame. To this end, we quantize a query into a discrete representation with a set of codes, and only allow neural networks to observe a finite number of variations. This allows neural networks to become increasingly familiar with these codes after overfitting more and more previous frames. Moreover, we also introduce novel initialization, losses, and argumentation to stabilize the optimization with significant uncertainty in the early optimization stage, constrain the optimization space, and estimate camera poses more accurately. We justify the effectiveness of each design and report visual and numerical comparisons on widely used benchmarks to show our superiority over the latest methods in both reconstruction and camera tracking.
MultiPull: Detailing Signed Distance Functions by Pulling Multi-Level Queries at Multi-Step
Nov 02, 2024



Reconstructing a continuous surface from a raw 3D point cloud is a challenging task. Recent methods usually train neural networks to overfit on single point clouds to infer signed distance functions (SDFs). However, neural networks tend to smooth local details due to the lack of ground truth signed distances or normals, which limits the performance of overfitting-based methods in reconstruction tasks. To resolve this issue, we propose a novel method, named MultiPull, to learn multi-scale implicit fields from raw point clouds by optimizing accurate SDFs from coarse to fine. We achieve this by mapping 3D query points into a set of frequency features, which makes it possible to leverage multi-level features during optimization. Meanwhile, we introduce optimization constraints from the perspective of spatial distance and normal consistency, which play a key role in point cloud reconstruction based on multi-scale optimization strategies. Our experiments on widely used object and scene benchmarks demonstrate that our method outperforms the state-of-the-art methods in surface reconstruction.