 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI for Film Creation: A Survey of Recent Advances
Apr 11, 2025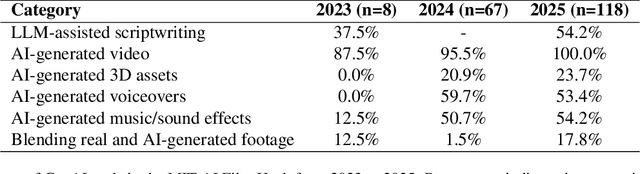


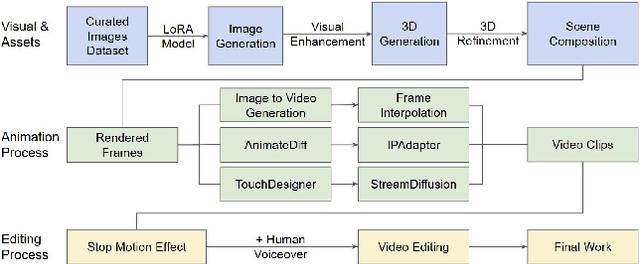
Generative AI (GenAI) is transforming filmmaking, equipping artists with tools like text-to-image and image-to-video diffusion, neural radiance fields, avatar generation, and 3D synthesis. This paper examines the adoption of these technologies in filmmaking, analyzing workflows from recent AI-driven films to understand how GenAI contributes to character creation, aesthetic styling, and narration. We explore key strategies for maintaining character consistency, achieving stylistic coherence, and ensuring motion continuity. Additionally, we highlight emerging trends such as the growing use of 3D generation and the integration of real footage with AI-generated elements. Beyond technical advancements, we examine how GenAI is enabling new artistic expressions, from generating hard-to-shoot footage to dreamlike diffusion-based morphing effects, abstract visuals, and unworldly objects. We also gather artists' feedback on challenges and desired improvements, including consistency, controllability, fine-grained editing, and motion refinement. Our study provides insights into the evolving intersection of AI and filmmaking, offering a roadmap for researchers and artists navigating this rapidly expanding field.
Sensing Surface Patches in Volume Rendering for Inferring Signed Distance Functions
Dec 21, 2024


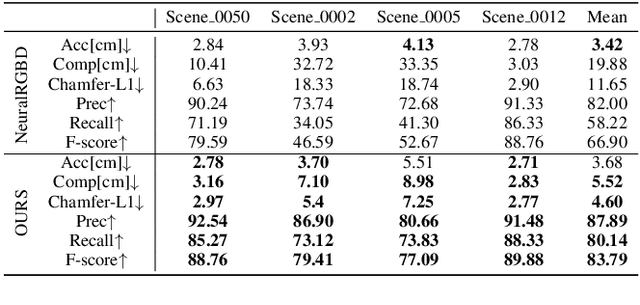
It is vital to recover 3D geometry from multi-view RGB images in many 3D computer vision tasks. The latest methods infer the geometry represented as a signed distance field by minimizing the rendering error on the field through volume rendering. However, it is still challenging to explicitly impose constraints on surfaces for inferring more geometry details due to the limited ability of sensing surfaces in volume rendering. To resolve this problem, we introduce a method to infer signed distance functions (SDFs) with a better sense of surfaces through volume rendering. Using the gradients and signed distances, we establish a small surface patch centered at the estimated intersection along a ray by pulling points randomly sampled nearby. Hence, we are able to explicitly impose surface constraints on the sensed surface patch, such as multi-view photo consistency and supervision from depth or normal priors, through volume rendering. We evaluate our method by numerical and visual comparisons on scene benchmarks. Our superiority over the latest methods justifies our effectiveness.
Query Quantized Neural SLAM
Dec 21, 2024



Neural implicit representations have shown remarkable abilities in jointly modeling geometry, color, and camera poses in simultaneous localization and mapping (SLAM). Current methods use coordinates, positional encodings, or other geometry features as input to query neural implicit functions for signed distances and color which produce rendering errors to drive the optimization in overfitting image observations. However, due to the run time efficiency requirement in SLAM systems, we are merely allowed to conduct optimization on each frame in few iterations, which is far from enough for neural networks to overfit these queries. The underfitting usually results in severe drifts in camera tracking and artifacts in reconstruction. To resolve this issue, we propose query quantized neural SLAM which uses quantized queries to reduce variations of input for much easier and faster overfitting a frame. To this end, we quantize a query into a discrete representation with a set of codes, and only allow neural networks to observe a finite number of variations. This allows neural networks to become increasingly familiar with these codes after overfitting more and more previous frames. Moreover, we also introduce novel initialization, losses, and argumentation to stabilize the optimization with significant uncertainty in the early optimization stage, constrain the optimization space, and estimate camera poses more accurately. We justify the effectiveness of each design and report visual and numerical comparisons on widely used benchmarks to show our superiority over the latest methods in both reconstruction and camera tracking.
Coordinate Quantized Neural Implicit Representations for Multi-view Reconstruction
Aug 21, 2023



In recent years, huge progress has been made on learning neural implicit representations from multi-view images for 3D reconstruction. As an additional input complementing coordinates, using sinusoidal functions as positional encodings plays a key role in revealing high frequency details with coordinate-based neural networks. However, high frequency positional encodings make the optimization unstable, which results in noisy reconstructions and artifacts in empty space. To resolve this issue in a general sense, we introduce to learn neural implicit representations with quantized coordinates, which reduces the uncertainty and ambiguity in the field during optimization. Instead of continuous coordinates, we discretize continuous coordinates into discrete coordinates using nearest interpolation among quantized coordinates which are obtained by discretizing the field in an extremely high resolution. We use discrete coordinates and their positional encodings to learn implicit functions through volume rendering. This significantly reduces the variations in the sample space, and triggers more multi-view consistency constraints on intersections of rays from different views, which enables to infer implicit function in a more effective way. Our quantized coordinates do not bring any computational burden, and can seamlessly work upon the latest methods. Our evaluations under the widely used benchmarks show our superiority over the state-of-the-art. Our code is available at https://github.com/MachinePerceptionLab/CQ-NIR.