 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRendering Data Unlearnable by Exploiting LLM Alignment Mechanisms
Jan 06, 2026Large language models (LLMs) are increasingly trained on massive, heterogeneous text corpora, raising serious concerns about the unauthorised use of proprietary or personal data during model training. In this work, we address the problem of data protection against unwanted model learning in a realistic black-box setting. We propose Disclaimer Injection, a novel data-level defence that renders text unlearnable to LLMs. Rather than relying on model-side controls or explicit data removal, our approach exploits the models' own alignment mechanisms: by injecting carefully designed alignment-triggering disclaimers to prevent effective learning. Through layer-wise analysis, we find that fine-tuning on such protected data induces persistent activation of alignment-related layers, causing alignment constraints to override task learning even on common inputs. Consequently, models trained on such data exhibit substantial and systematic performance degradation compared to standard fine-tuning. Our results identify alignment behaviour as a previously unexplored lever for data protection and, to our knowledge, present the first practical method for restricting data learnability at LLM scale without requiring access to or modification of the training pipeline.
Towards Provably Unlearnable Examples via Bayes Error Optimisation
Nov 11, 2025



The recent success of machine learning models, especially large-scale classifiers and language models, relies heavily on training with massive data. These data are often collected from online sources. This raises serious concerns about the protection of user data, as individuals may not have given consent for their data to be used in training. To address this concern, recent studies introduce the concept of unlearnable examples, i.e., data instances that appear natural but are intentionally altered to prevent models from effectively learning from them. While existing methods demonstrate empirical effectiveness, they typically rely on heuristic trials and lack formal guarantees. Besides, when unlearnable examples are mixed with clean data, as is often the case in practice, their unlearnability disappears. In this work, we propose a novel approach to constructing unlearnable examples by systematically maximising the Bayes error, a measurement of irreducible classification error. We develop an optimisation-based approach and provide an efficient solution using projected gradient ascent. Our method provably increases the Bayes error and remains effective when the unlearning examples are mixed with clean samples. Experimental results across multiple datasets and model architectures are consistent with our theoretical analysis and show that our approach can restrict data learnability, effectively in practice.
Generative AI for Film Creation: A Survey of Recent Advances
Apr 11, 2025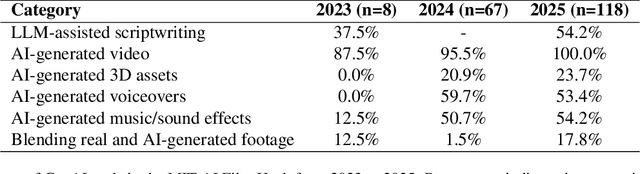


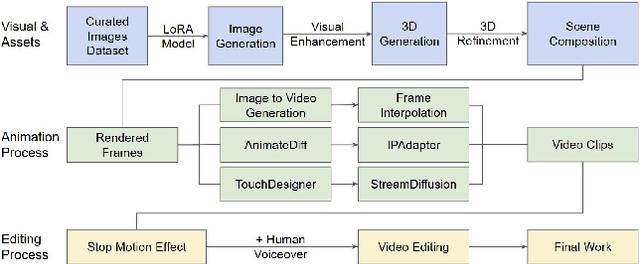
Generative AI (GenAI) is transforming filmmaking, equipping artists with tools like text-to-image and image-to-video diffusion, neural radiance fields, avatar generation, and 3D synthesis. This paper examines the adoption of these technologies in filmmaking, analyzing workflows from recent AI-driven films to understand how GenAI contributes to character creation, aesthetic styling, and narration. We explore key strategies for maintaining character consistency, achieving stylistic coherence, and ensuring motion continuity. Additionally, we highlight emerging trends such as the growing use of 3D generation and the integration of real footage with AI-generated elements. Beyond technical advancements, we examine how GenAI is enabling new artistic expressions, from generating hard-to-shoot footage to dreamlike diffusion-based morphing effects, abstract visuals, and unworldly objects. We also gather artists' feedback on challenges and desired improvements, including consistency, controllability, fine-grained editing, and motion refinement. Our study provides insights into the evolving intersection of AI and filmmaking, offering a roadmap for researchers and artists navigating this rapidly expanding field.
How Does Bayes Error Limit Probabilistic Robust Accuracy
May 23, 2024Adversarial examples pose a security threat to many critical systems built on neural networks. Given that deterministic robustness often comes with significantly reduced accuracy, probabilistic robustness (i.e., the probability of having the same label with a vicinity is $\ge 1-\kappa$) has been proposed as a promising way of achieving robustness whilst maintaining accuracy. However, existing training methods for probabilistic robustness still experience non-trivial accuracy loss. It is unclear whether there is an upper bound on the accuracy when optimising towards probabilistic robustness, and whether there is a certain relationship between $\kappa$ and this bound. This work studies these problems from a Bayes error perspective. We find that while Bayes uncertainty does affect probabilistic robustness, its impact is smaller than that on deterministic robustness. This reduced Bayes uncertainty allows a higher upper bound on probabilistic robust accuracy than that on deterministic robust accuracy. Further, we prove that with optimal probabilistic robustness, each probabilistically robust input is also deterministically robust in a smaller vicinity. We also show that voting within the vicinity always improves probabilistic robust accuracy and the upper bound of probabilistic robust accuracy monotonically increases as $\kappa$ grows. Our empirical findings also align with our results.
Certified Robust Accuracy of Neural Networks Are Bounded due to Bayes Errors
May 19, 2024Adversarial examples pose a security threat to many critical systems built on neural networks. While certified training improves robustness, it also decreases accuracy noticeably. Despite various proposals for addressing this issue, the significant accuracy drop remains. More importantly, it is not clear whether there is a certain fundamental limit on achieving robustness whilst maintaining accuracy. In this work, we offer a novel perspective based on Bayes errors. By adopting Bayes error to robustness analysis, we investigate the limit of certified robust accuracy, taking into account data distribution uncertainties. We first show that the accuracy inevitably decreases in the pursuit of robustness due to changed Bayes error in the altered data distribution. Subsequently, we establish an upper bound for certified robust accuracy, considering the distribution of individual classes and their boundaries. Our theoretical results are empirically evaluated on real-world datasets and are shown to be consistent with the limited success of existing certified training results, \emph{e.g.}, for CIFAR10, our analysis results in an upper bound (of certified robust accuracy) of 67.49\%, meanwhile existing approaches are only able to increase it from 53.89\% in 2017 to 62.84\% in 2023.
Towards Certified Probabilistic Robustness with High Accuracy
Sep 02, 2023Adversarial examples pose a security threat to many critical systems built on neural networks (such as face recognition systems, and self-driving cars). While many methods have been proposed to build robust models, how to build certifiably robust yet accurate neural network models remains an open problem. For example, adversarial training improves empirical robustness, but they do not provide certification of the model's robustness. On the other hand, certified training provides certified robustness but at the cost of a significant accuracy drop. In this work, we propose a novel approach that aims to achieve both high accuracy and certified probabilistic robustness. Our method has two parts, i.e., a probabilistic robust training method with an additional goal of minimizing variance in terms of divergence and a runtime inference method for certified probabilistic robustness of the prediction. The latter enables efficient certification of the model's probabilistic robustness at runtime with statistical guarantees. This is supported by our training objective, which minimizes the variance of the model's predictions in a given vicinity, derived from a general definition of model robustness. Our approach works for a variety of perturbations and is reasonably efficient. Our experiments on multiple models trained on different datasets demonstrate that our approach significantly outperforms existing approaches in terms of both certification rate and accuracy.
HCL-TAT: A Hybrid Contrastive Learning Method for Few-shot Event Detection with Task-Adaptive Threshold
Oct 17, 2022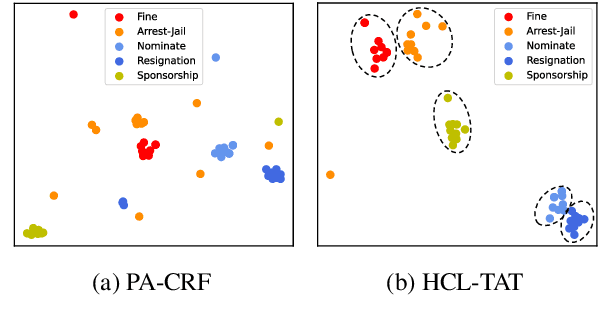
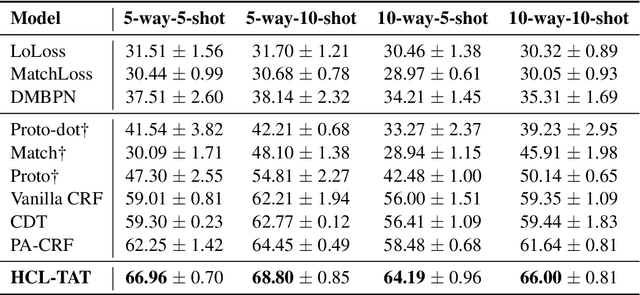
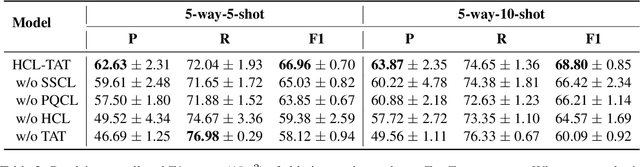
Conventional event detection models under supervised learning settings suffer from the inability of transfer to newly-emerged event types owing to lack of sufficient annotations. A commonly-adapted solution is to follow a identify-then-classify manner, which first identifies the triggers and then converts the classification task via a few-shot learning paradigm. However, these methods still fall far short of expectations due to: (i) insufficient learning of discriminative representations in low-resource scenarios, and (ii) trigger misidentification caused by the overlap of the learned representations of triggers and non-triggers. To address the problems, in this paper, we propose a novel Hybrid Contrastive Learning method with a Task-Adaptive Threshold (abbreviated as HCLTAT), which enables discriminative representation learning with a two-view contrastive loss (support-support and prototype-query), and devises a easily-adapted threshold to alleviate misidentification of triggers. Extensive experiments on the benchmark dataset FewEvent demonstrate the superiority of our method to achieve better results compared to the state-of-the-arts. All the code and data of this paper will be available for online public access.
Representing Affect Information in Word Embeddings
Sep 21, 2022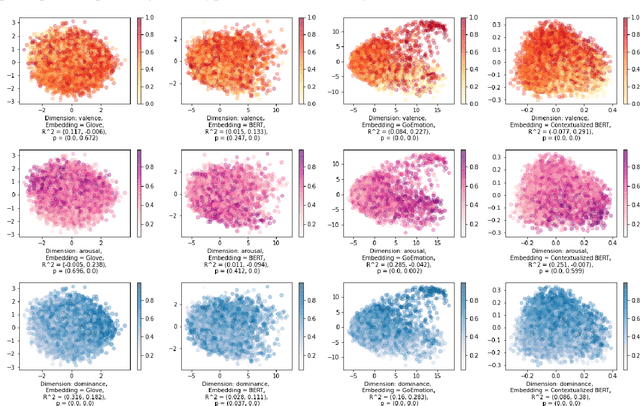
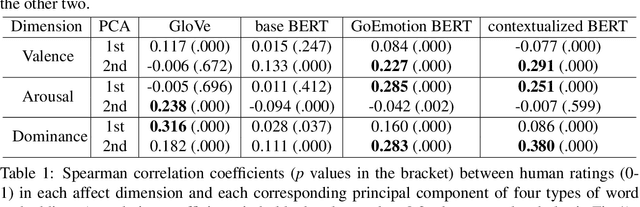

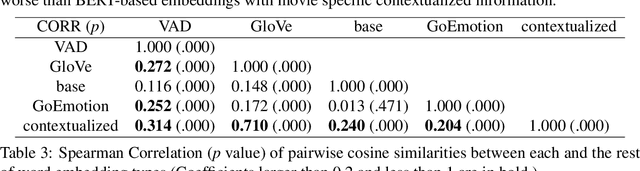
A growing body of research in natural language processing (NLP) and natural language understanding (NLU) is investigating human-like knowledge learned or encoded in the word embeddings from large language models. This is a step towards understanding what knowledge language models capture that resembles human understanding of language and communication. Here, we investigated whether and how the affect meaning of a word (i.e., valence, arousal, dominance) is encoded in word embeddings pre-trained in large neural networks. We used the human-labeled dataset as the ground truth and performed various correlational and classification tests on four types of word embeddings. The embeddings varied in being static or contextualized, and how much affect specific information was prioritized during the pre-training and fine-tuning phase. Our analyses show that word embedding from the vanilla BERT model did not saliently encode the affect information of English words. Only when the BERT model was fine-tuned on emotion-related tasks or contained extra contextualized information from emotion-rich contexts could the corresponding embedding encode more relevant affect information.
MIPR:Automatic Annotation of Medical Images with Pixel Rearrangement
Apr 22, 2022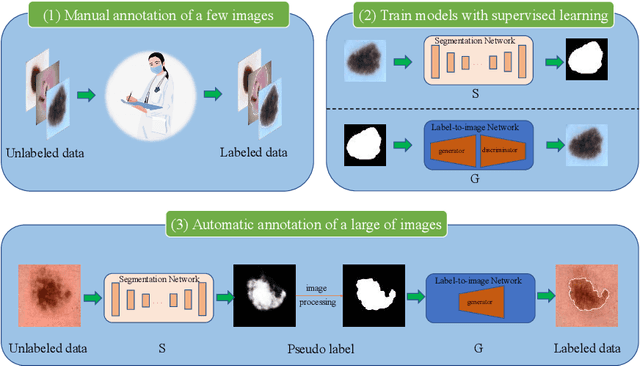
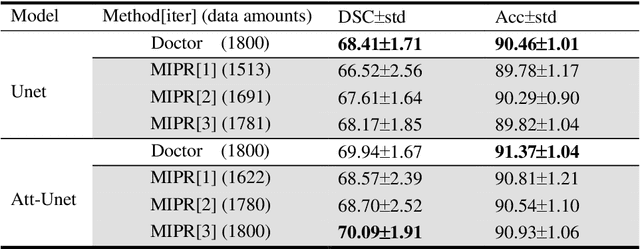
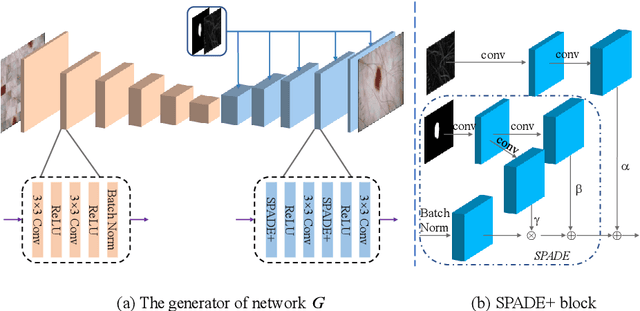

Most of the state-of-the-art semantic segmentation reported in recent years is based on fully supervised deep learning in the medical domain. How?ever, the high-quality annotated datasets require intense labor and domain knowledge, consuming enormous time and cost. Previous works that adopt semi?supervised and unsupervised learning are proposed to address the lack of anno?tated data through assisted training with unlabeled data and achieve good perfor?mance. Still, these methods can not directly get the image annotation as doctors do. In this paper, inspired by self-training of semi-supervised learning, we pro?pose a novel approach to solve the lack of annotated data from another angle, called medical image pixel rearrangement (short in MIPR). The MIPR combines image-editing and pseudo-label technology to obtain labeled data. As the number of iterations increases, the edited image is similar to the original image, and the labeled result is similar to the doctor annotation. Therefore, the MIPR is to get labeled pairs of data directly from amounts of unlabled data with pixel rearrange?ment, which is implemented with a designed conditional Generative Adversarial Networks and a segmentation network. Experiments on the ISIC18 show that the effect of the data annotated by our method for segmentation task is is equal to or even better than that of doctors annotations
Instance Segmentation of Unlabeled Modalities via Cyclic Segmentation GAN
Apr 06, 2022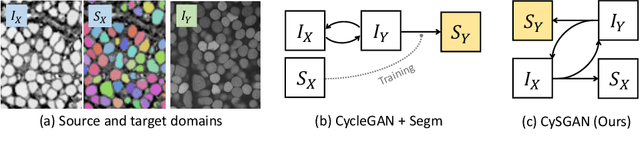

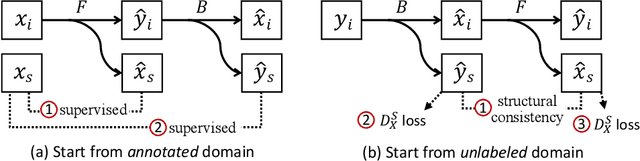
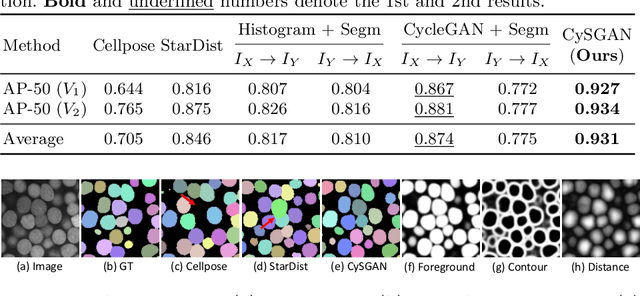
Instance segmentation for unlabeled imaging modalities is a challenging but essential task as collecting expert annotation can be expensive and time-consuming. Existing works segment a new modality by either deploying a pre-trained model optimized on diverse training data or conducting domain translation and image segmentation as two independent steps. In this work, we propose a novel Cyclic Segmentation Generative Adversarial Network (CySGAN) that conducts image translation and instance segmentation jointly using a unified framework. Besides the CycleGAN losses for image translation and supervised losses for the annotated source domain, we introduce additional self-supervised and segmentation-based adversarial objectives to improve the model performance by leveraging unlabeled target domain images. We benchmark our approach on the task of 3D neuronal nuclei segmentation with annotated electron microscopy (EM) images and unlabeled expansion microscopy (ExM) data. Our CySGAN outperforms both pretrained generalist models and the baselines that sequentially conduct image translation and segmentation. Our implementation and the newly collected, densely annotated ExM nuclei dataset, named NucExM, are available at https://connectomics-bazaar.github.io/proj/CySGAN/index.html.