 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Interpretability of CNN Models Using Non-Negative Concept Activation Vectors
Paper and Code
Jul 07, 2020
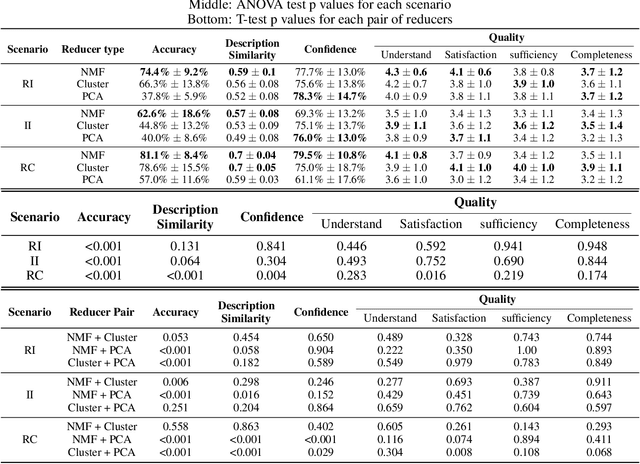
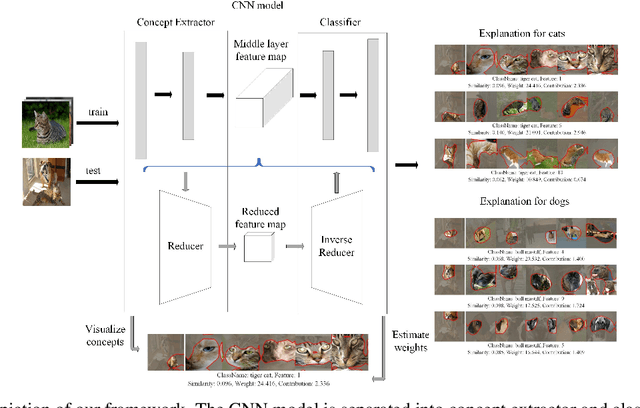
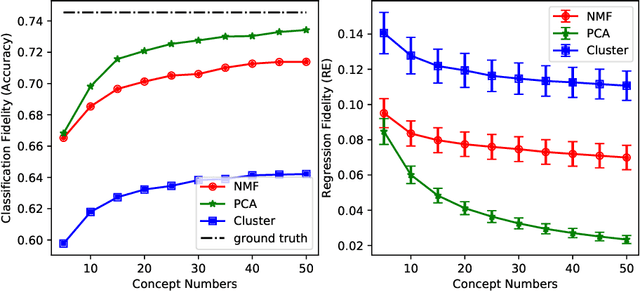
Convolutional neural network (CNN) models for computer vision are powerful but lack explainability in their most basic form. This deficiency remains a key challenge when applying CNNs in important domains. Recent work for explanations through feature importance of approximate linear models has moved from input-level features (pixels or segments) to features from mid-layer feature maps in the guise of concept activation vectors (CAVs). CAVs contain concept-level information and could be learnt via Clustering. In this work, we rethink the ACE algorithm of Ghorbani et~al., proposing an alternative concept-based explanation framework. Based on the requirements of fidelity (approximate models) and interpretability (being meaningful to people), we design measurements and evaluate a range of dimensionality reduction methods for alignment with our framework. We find that non-negative concept activation vectors from non-negative matrix factorization provide superior performance in interpretability and fidelity based on computational and human subject experiments. Our framework provides both local and global concept-level explanations for pre-trained CNN models.