 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Radiomics into Vision Transformers for Multimodal Medical Image Classification
Apr 15, 2025Background: Deep learning has significantly advanced medical image analysis, with Vision Transformers (ViTs) offering a powerful alternative to convolutional models by modeling long-range dependencies through self-attention. However, ViTs are inherently data-intensive and lack domain-specific inductive biases, limiting their applicability in medical imaging. In contrast, radiomics provides interpretable, handcrafted descriptors of tissue heterogeneity but suffers from limited scalability and integration into end-to-end learning frameworks. In this work, we propose the Radiomics-Embedded Vision Transformer (RE-ViT) that combines radiomic features with data-driven visual embeddings within a ViT backbone. Purpose: To develop a hybrid RE-ViT framework that integrates radiomics and patch-wise ViT embeddings through early fusion, enhancing robustness and performance in medical image classification. Methods: Following the standard ViT pipeline, images were divided into patches. For each patch, handcrafted radiomic features were extracted and fused with linearly projected pixel embeddings. The fused representations were normalized, positionally encoded, and passed to the ViT encoder. A learnable [CLS] token aggregated patch-level information for classification. We evaluated RE-ViT on three public datasets (including BUSI, ChestXray2017, and Retinal OCT) using accuracy, macro AUC, sensitivity, and specificity. RE-ViT was benchmarked against CNN-based (VGG-16, ResNet) and hybrid (TransMed) models. Results: RE-ViT achieved state-of-the-art results: on BUSI, AUC=0.950+/-0.011; on ChestXray2017, AUC=0.989+/-0.004; on Retinal OCT, AUC=0.986+/-0.001, which outperforms other comparison models. Conclusions: The RE-ViT framework effectively integrates radiomics with ViT architectures, demonstrating improved performance and generalizability across multimodal medical image classification tasks.
An Explainable Neural Radiomic Sequence Model with Spatiotemporal Continuity for Quantifying 4DCT-based Pulmonary Ventilation
Mar 31, 2025Accurate evaluation of regional lung ventilation is essential for the management and treatment of lung cancer patients, supporting assessments of pulmonary function, optimization of therapeutic strategies, and monitoring of treatment response. Currently, ventilation scintigraphy using nuclear medicine techniques is widely employed in clinical practice; however, it is often time-consuming, costly, and entails additional radiation exposure. In this study, we propose an explainable neural radiomic sequence model to identify regions of compromised pulmonary ventilation based on four-dimensional computed tomography (4DCT). A cohort of 45 lung cancer patients from the VAMPIRE dataset was analyzed. For each patient, lung volumes were segmented from 4DCT, and voxel-wise radiomic features (56-dimensional) were extracted across the respiratory cycle to capture local intensity and texture dynamics, forming temporal radiomic sequences. Ground truth ventilation defects were delineated voxel-wise using Galligas-PET and DTPA-SPECT. To identify compromised regions, we developed a temporal saliency-enhanced explainable long short-term memory (LSTM) network trained on the radiomic sequences. Temporal saliency maps were generated to highlight key features contributing to the model's predictions. The proposed model demonstrated robust performance, achieving average (range) Dice similarity coefficients of 0.78 (0.74-0.79) for 25 PET cases and 0.78 (0.74-0.82) for 20 SPECT cases. The temporal saliency map explained three key radiomic sequences in ventilation quantification: during lung exhalation, compromised pulmonary function region typically exhibits (1) an increasing trend of intensity and (2) a decreasing trend of homogeneity, in contrast to healthy lung tissue.
Task-Oriented Diffusion Inversion for High-Fidelity Text-based Editing
Aug 23, 2024Recent advancements in text-guided diffusion models have unlocked powerful image manipulation capabilities, yet balancing reconstruction fidelity and editability for real images remains a significant challenge. In this work, we introduce \textbf{T}ask-\textbf{O}riented \textbf{D}iffusion \textbf{I}nversion (\textbf{TODInv}), a novel framework that inverts and edits real images tailored to specific editing tasks by optimizing prompt embeddings within the extended \(\mathcal{P}^*\) space. By leveraging distinct embeddings across different U-Net layers and time steps, TODInv seamlessly integrates inversion and editing through reciprocal optimization, ensuring both high fidelity and precise editability. This hierarchical editing mechanism categorizes tasks into structure, appearance, and global edits, optimizing only those embeddings unaffected by the current editing task. Extensive experiments on benchmark dataset reveal TODInv's superior performance over existing methods, delivering both quantitative and qualitative enhancements while showcasing its versatility with few-step diffusion model.
Human Video Translation via Query Warping
Feb 19, 2024In this paper, we present QueryWarp, a novel framework for temporally coherent human motion video translation. Existing diffusion-based video editing approaches that rely solely on key and value tokens to ensure temporal consistency, which scarifies the preservation of local and structural regions. In contrast, we aim to consider complementary query priors by constructing the temporal correlations among query tokens from different frames. Initially, we extract appearance flows from source poses to capture continuous human foreground motion. Subsequently, during the denoising process of the diffusion model, we employ appearance flows to warp the previous frame's query token, aligning it with the current frame's query. This query warping imposes explicit constraints on the outputs of self-attention layers, effectively guaranteeing temporally coherent translation. We perform experiments on various human motion video translation tasks, and the results demonstrate that our QueryWarp framework surpasses state-of-the-art methods both qualitatively and quantitatively.
MIPR:Automatic Annotation of Medical Images with Pixel Rearrangement
Apr 22, 2022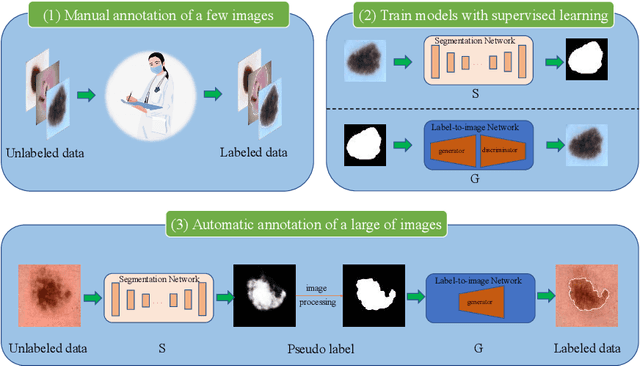
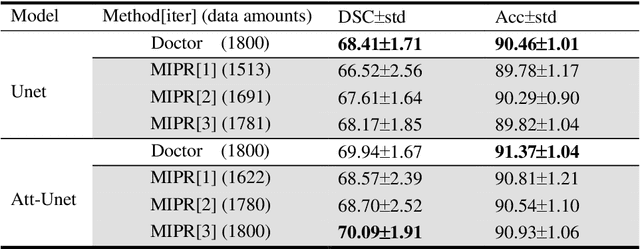
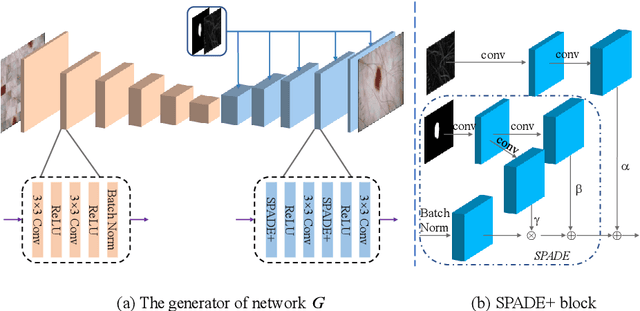

Most of the state-of-the-art semantic segmentation reported in recent years is based on fully supervised deep learning in the medical domain. How?ever, the high-quality annotated datasets require intense labor and domain knowledge, consuming enormous time and cost. Previous works that adopt semi?supervised and unsupervised learning are proposed to address the lack of anno?tated data through assisted training with unlabeled data and achieve good perfor?mance. Still, these methods can not directly get the image annotation as doctors do. In this paper, inspired by self-training of semi-supervised learning, we pro?pose a novel approach to solve the lack of annotated data from another angle, called medical image pixel rearrangement (short in MIPR). The MIPR combines image-editing and pseudo-label technology to obtain labeled data. As the number of iterations increases, the edited image is similar to the original image, and the labeled result is similar to the doctor annotation. Therefore, the MIPR is to get labeled pairs of data directly from amounts of unlabled data with pixel rearrange?ment, which is implemented with a designed conditional Generative Adversarial Networks and a segmentation network. Experiments on the ISIC18 show that the effect of the data annotated by our method for segmentation task is is equal to or even better than that of doctors annotations
Soft-CP: A Credible and Effective Data Augmentation for Semantic Segmentation of Medical Lesions
Mar 20, 2022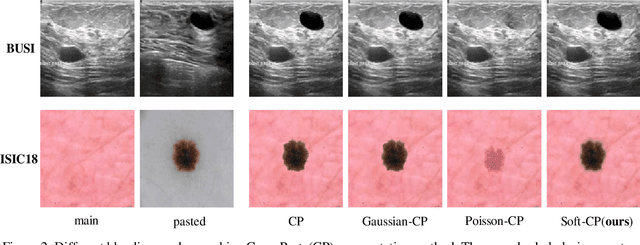

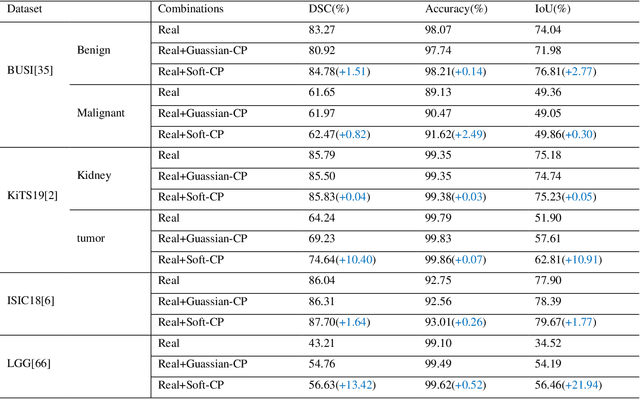
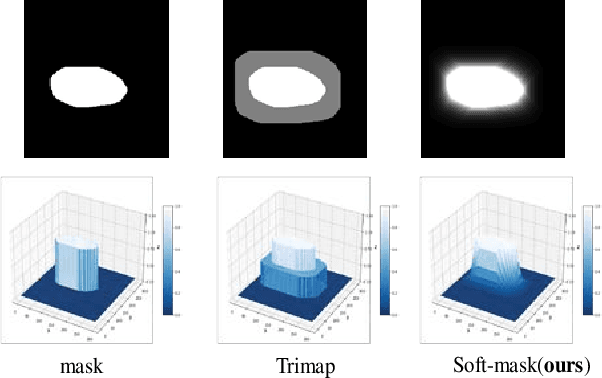
The medical datasets are usually faced with the problem of scarcity and data imbalance. Moreover, annotating large datasets for semantic segmentation of medical lesions is domain-knowledge and time-consuming. In this paper, we propose a new object-blend method(short in soft-CP) that combines the Copy-Paste augmentation method for semantic segmentation of medical lesions offline, ensuring the correct edge information around the lession to solve the issue above-mentioned. We proved the method's validity with several datasets in different imaging modalities. In our experiments on the KiTS19[2] dataset, Soft-CP outperforms existing medical lesions synthesis approaches. The Soft-CP augementation provides gains of +26.5% DSC in the low data regime(10% of data) and +10.2% DSC in the high data regime(all of data), In offline training data, the ratio of real images to synthetic images is 3:1.