 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCA-RAC: First Cycle Annotated Repetitive Action Counting
Jun 18, 2024



Repetitive action counting quantifies the frequency of specific actions performed by individuals. However, existing action-counting datasets have limited action diversity, potentially hampering model performance on unseen actions. To address this issue, we propose a framework called First Cycle Annotated Repetitive Action Counting (FCA-RAC). This framework contains 4 parts: 1) a labeling technique that annotates each training video with the start and end of the first action cycle, along with the total action count. This technique enables the model to capture the correlation between the initial action cycle and subsequent actions; 2) an adaptive sampling strategy that maximizes action information retention by adjusting to the speed of the first annotated action cycle in videos; 3) a Multi-Temporal Granularity Convolution (MTGC) module, that leverages the muli-scale first action as a kernel to convolve across the entire video. This enables the model to capture action variations at different time scales within the video; 4) a strategy called Training Knowledge Augmentation (TKA) that exploits the annotated first action cycle information from the entire dataset. This allows the network to harness shared characteristics across actions effectively, thereby enhancing model performance and generalizability to unseen actions. Experimental results demonstrate that our approach achieves superior outcomes on RepCount-A and related datasets, highlighting the efficacy of our framework in improving model performance on seen and unseen actions. Our paper makes significant contributions to the field of action counting by addressing the limitations of existing datasets and proposing novel techniques for improving model generalizability.
Enhancing Industrial Transfer Learning with Style Filter: Cost Reduction and Defect-Focus
Mar 25, 2024



Addressing the challenge of data scarcity in industrial domains, transfer learning emerges as a pivotal paradigm. This work introduces Style Filter, a tailored methodology for industrial contexts. By selectively filtering source domain data before knowledge transfer, Style Filter reduces the quantity of data while maintaining or even enhancing the performance of transfer learning strategy. Offering label-free operation, minimal reliance on prior knowledge, independence from specific models, and re-utilization, Style Filter is evaluated on authentic industrial datasets, highlighting its effectiveness when employed before conventional transfer strategies in the deep learning domain. The results underscore the effectiveness of Style Filter in real-world industrial applications.
Underwater and Surface Aquatic Locomotion of Soft Biomimetic Robot Based on Bending Rolled Dielectric Elastomer Actuators
Oct 19, 2023All-around, real-time navigation and sensing across the water environments by miniature soft robotics are promising, for their merits of small size, high agility and good compliance to the unstructured surroundings. In this paper, we propose and demonstrate a mantas-like soft aquatic robot which propels itself by flapping-fins using rolled dielectric elastomer actuators (DEAs) with bending motions. This robot exhibits fast-moving capabilities of swimming at 57mm/s or 1.25 body length per second (BL/s), skating on water surface at 64 mm/s (1.36 BL/s) and vertical ascending at 38mm/s (0.82 BL/s) at 1300 V, 17 Hz of the power supply. These results show the feasibility of adopting rolled DEAs for mesoscale aquatic robots with high motion performance in various water-related scenarios.
Model-based Transfer Learning for Automatic Optical Inspection based on domain discrepancy
Jan 14, 2023



Transfer learning is a promising method for AOI applications since it can significantly shorten sample collection time and improve efficiency in today's smart manufacturing. However, related research enhanced the network models by applying TL without considering the domain similarity among datasets, the data long-tailedness of a source dataset, and mainly used linear transformations to mitigate the lack of samples. This research applies model-based TL via domain similarity to improve the overall performance and data augmentation in both target and source domains to enrich the data quality and reduce the imbalance. Given a group of source datasets from similar industrial processes, we define which group is the most related to the target through the domain discrepancy score and the number of samples each has. Then, we transfer the chosen pre-trained backbone weights to train and fine-tune the target network. Our research suggests increases in the F1 score and the PR curve up to 20% compared with TL using benchmark datasets.
* This is a fix of the published paper "Relational-based transfer learning for automatic optical inspection based on domain discrepancy"
MIPR:Automatic Annotation of Medical Images with Pixel Rearrangement
Apr 22, 2022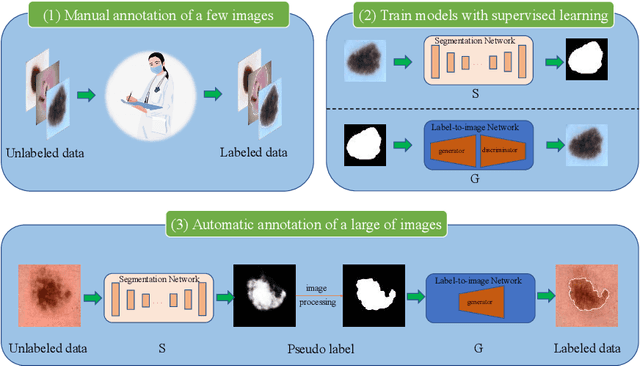
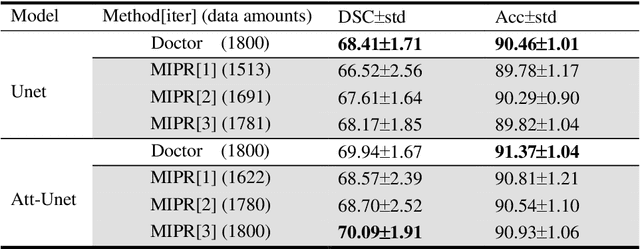
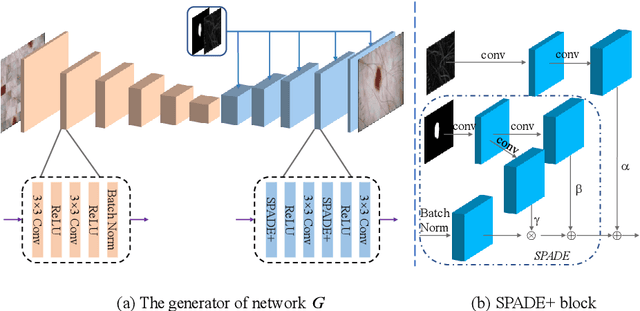

Most of the state-of-the-art semantic segmentation reported in recent years is based on fully supervised deep learning in the medical domain. How?ever, the high-quality annotated datasets require intense labor and domain knowledge, consuming enormous time and cost. Previous works that adopt semi?supervised and unsupervised learning are proposed to address the lack of anno?tated data through assisted training with unlabeled data and achieve good perfor?mance. Still, these methods can not directly get the image annotation as doctors do. In this paper, inspired by self-training of semi-supervised learning, we pro?pose a novel approach to solve the lack of annotated data from another angle, called medical image pixel rearrangement (short in MIPR). The MIPR combines image-editing and pseudo-label technology to obtain labeled data. As the number of iterations increases, the edited image is similar to the original image, and the labeled result is similar to the doctor annotation. Therefore, the MIPR is to get labeled pairs of data directly from amounts of unlabled data with pixel rearrange?ment, which is implemented with a designed conditional Generative Adversarial Networks and a segmentation network. Experiments on the ISIC18 show that the effect of the data annotated by our method for segmentation task is is equal to or even better than that of doctors annotations