 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Video Generation with Provable Disentanglement
Feb 04, 2025



Controllable video generation remains a significant challenge, despite recent advances in generating high-quality and consistent videos. Most existing methods for controlling video generation treat the video as a whole, neglecting intricate fine-grained spatiotemporal relationships, which limits both control precision and efficiency. In this paper, we propose Controllable Video Generative Adversarial Networks (CoVoGAN) to disentangle the video concepts, thus facilitating efficient and independent control over individual concepts. Specifically, following the minimal change principle, we first disentangle static and dynamic latent variables. We then leverage the sufficient change property to achieve component-wise identifiability of dynamic latent variables, enabling independent control over motion and identity. To establish the theoretical foundation, we provide a rigorous analysis demonstrating the identifiability of our approach. Building on these theoretical insights, we design a Temporal Transition Module to disentangle latent dynamics. To enforce the minimal change principle and sufficient change property, we minimize the dimensionality of latent dynamic variables and impose temporal conditional independence. To validate our approach, we integrate this module as a plug-in for GANs. Extensive qualitative and quantitative experiments on various video generation benchmarks demonstrate that our method significantly improves generation quality and controllability across diverse real-world scenarios.
Flexible Multi-Generator Model with Fused Spatiotemporal Graph for Trajectory Prediction
Nov 06, 2023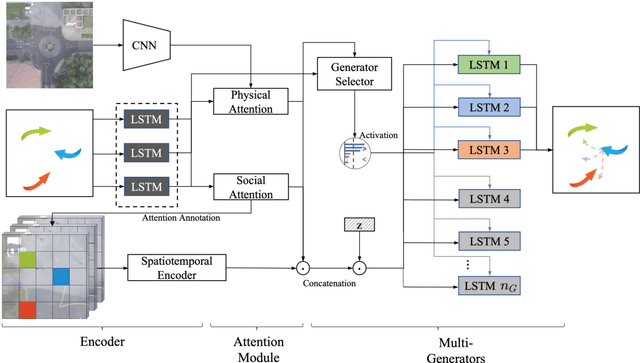

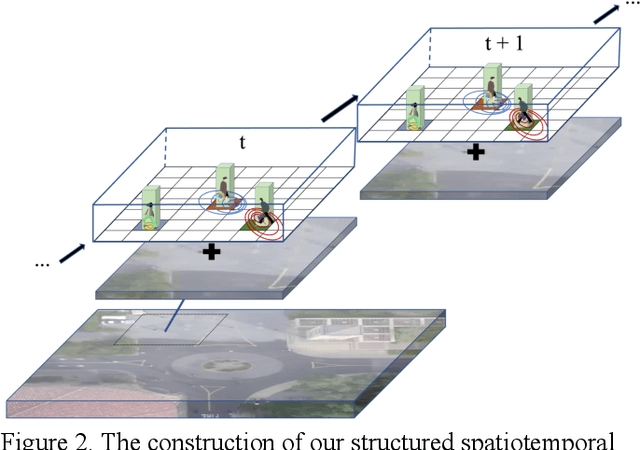

Trajectory prediction plays a vital role in automotive radar systems, facilitating precise tracking and decision-making in autonomous driving. Generative adversarial networks with the ability to learn a distribution over future trajectories tend to predict out-of-distribution samples, which typically occurs when the distribution of forthcoming paths comprises a blend of various manifolds that may be disconnected. To address this issue, we propose a trajectory prediction framework, which can capture the social interaction variations and model disconnected manifolds of pedestrian trajectories. Our framework is based on a fused spatiotemporal graph to better model the complex interactions of pedestrians in a scene, and a multi-generator architecture that incorporates a flexible generator selector network on generated trajectories to learn a distribution over multiple generators. We show that our framework achieves state-of-the-art performance compared with several baselines on different challenging datasets.
Model-based Transfer Learning for Automatic Optical Inspection based on domain discrepancy
Jan 14, 2023



Transfer learning is a promising method for AOI applications since it can significantly shorten sample collection time and improve efficiency in today's smart manufacturing. However, related research enhanced the network models by applying TL without considering the domain similarity among datasets, the data long-tailedness of a source dataset, and mainly used linear transformations to mitigate the lack of samples. This research applies model-based TL via domain similarity to improve the overall performance and data augmentation in both target and source domains to enrich the data quality and reduce the imbalance. Given a group of source datasets from similar industrial processes, we define which group is the most related to the target through the domain discrepancy score and the number of samples each has. Then, we transfer the chosen pre-trained backbone weights to train and fine-tune the target network. Our research suggests increases in the F1 score and the PR curve up to 20% compared with TL using benchmark datasets.
* This is a fix of the published paper "Relational-based transfer learning for automatic optical inspection based on domain discrepancy"
Context-aware Heterogeneous Graph Attention Network for User Behavior Prediction in Local Consumer Service Platform
Jun 29, 2021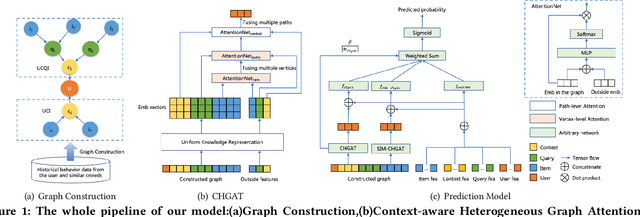

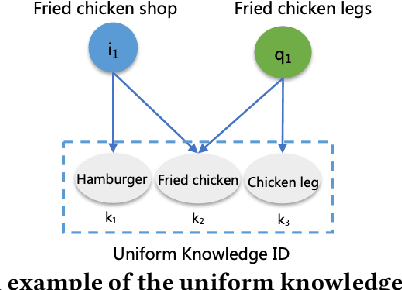
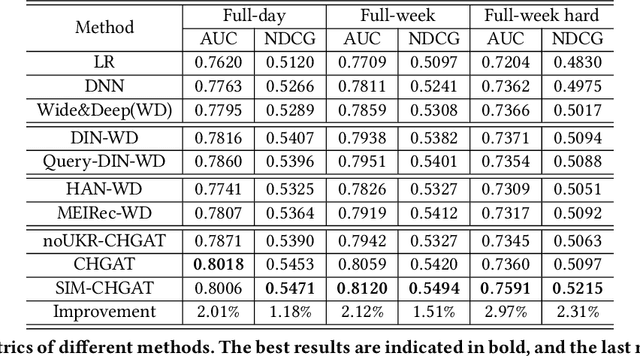
As a new type of e-commerce platform developed in recent years, local consumer service platform provides users with software to consume service to the nearby store or to the home, such as Groupon and Koubei. Different from other common e-commerce platforms, the behavior of users on the local consumer service platform is closely related to their real-time local context information. Therefore, building a context-aware user behavior prediction system is able to provide both merchants and users better service in local consumer service platforms. However, most of the previous work just treats the contextual information as an ordinary feature into the prediction model to obtain the prediction list under a specific context, which ignores the fact that the interest of a user in different contexts is often significantly different. Hence, in this paper, we propose a context-aware heterogeneous graph attention network (CHGAT) to dynamically generate the representation of the user and to estimate the probability for future behavior. Specifically, we first construct the meta-path based heterogeneous graphs with the historical behaviors from multiple sources and comprehend heterogeneous vertices in the graph with a novel unified knowledge representing approach. Next, a multi-level attention mechanism is introduced for context-aware aggregation with graph vertices, which contains the vertex-level attention network and the path-level attention network. Both of them aim to capture the semantic correlation between information contained in the graph and the outside real-time contextual information in the search system. Then the model proposed in this paper aggregates specific graphs with their corresponding context features and obtains the representation of user interest under a specific context and input it into the prediction network to finally obtain the predicted probability of user behavior.
Slice Sampling for General Completely Random Measures
Jun 25, 2020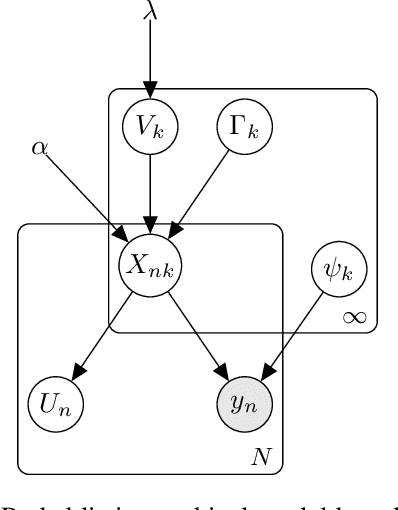
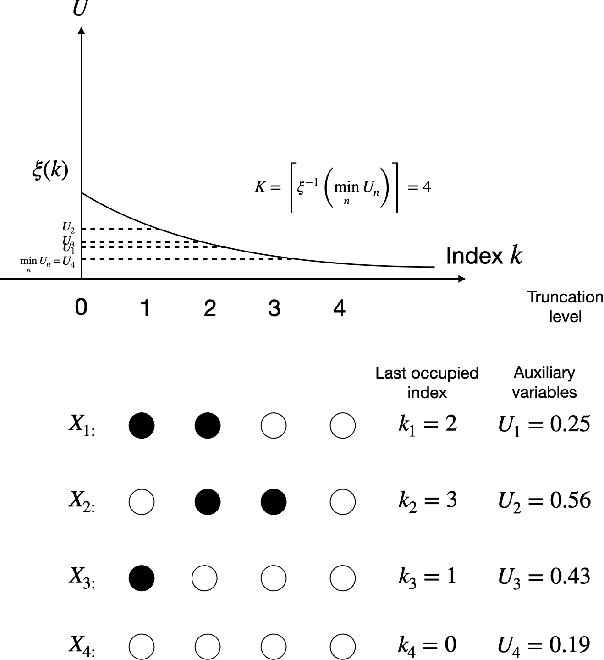
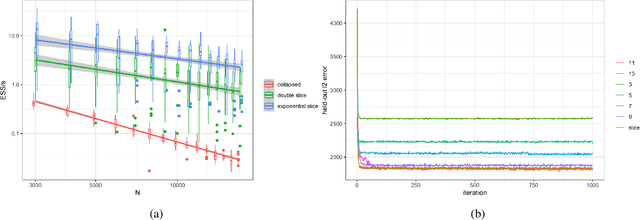
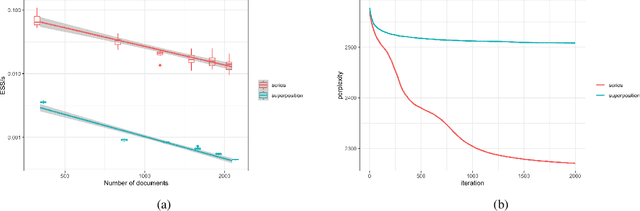
Completely random measures provide a principled approach to creating flexible unsupervised models, where the number of latent features is infinite and the number of features that influence the data grows with the size of the data set. Due to the infinity the latent features, posterior inference requires either marginalization---resulting in dependence structures that prevent efficient computation via parallelization and conjugacy---or finite truncation, which arbitrarily limits the flexibility of the model. In this paper we present a novel Markov chain Monte Carlo algorithm for posterior inference that adaptively sets the truncation level using auxiliary slice variables, enabling efficient, parallelized computation without sacrificing flexibility. In contrast to past work that achieved this on a model-by-model basis, we provide a general recipe that is applicable to the broad class of completely random measure-based priors. The efficacy of the proposed algorithm is evaluated on several popular nonparametric models, demonstrating a higher effective sample size per second compared to algorithms using marginalization as well as a higher predictive performance compared to models employing fixed truncations.