 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSGD: Automatic Learning Rate Selection for Stochastic Gradient Descent
May 27, 2025The learning rate is an important tuning parameter for stochastic gradient descent (SGD) and can greatly influence its performance. However, appropriate selection of a learning rate schedule across all iterations typically requires a non-trivial amount of user tuning effort. To address this, we introduce AutoSGD: an SGD method that automatically determines whether to increase or decrease the learning rate at a given iteration and then takes appropriate action. We introduce theory supporting the convergence of AutoSGD, along with its deterministic counterpart for standard gradient descent. Empirical results suggest strong performance of the method on a variety of traditional optimization problems and machine learning tasks.
Variational phylogenetic inference with products over bipartitions
Feb 21, 2025Bayesian phylogenetics requires accurate and efficient approximation of posterior distributions over trees. In this work, we develop a variational Bayesian approach for ultrametric phylogenetic trees. We present a novel variational family based on coalescent times of a single-linkage clustering and derive a closed-form density of the resulting distribution over trees. Unlike existing methods for ultrametric trees, our method performs inference over all of tree space, it does not require any Markov chain Monte Carlo subroutines, and our variational family is differentiable. Through experiments on benchmark genomic datasets and an application to SARS-CoV-2, we demonstrate that our method achieves competitive accuracy while requiring significantly fewer gradient evaluations than existing state-of-the-art techniques.
AutoStep: Locally adaptive involutive MCMC
Oct 24, 2024



Many common Markov chain Monte Carlo (MCMC) kernels can be formulated using a deterministic involutive proposal with a step size parameter. Selecting an appropriate step size is often a challenging task in practice; and for complex multiscale targets, there may not be one choice of step size that works well globally. In this work, we address this problem with a novel class of involutive MCMC methods -- AutoStep MCMC -- that selects an appropriate step size at each iteration adapted to the local geometry of the target distribution. We prove that AutoStep MCMC is $\pi$-invariant and has other desirable properties under mild assumptions on the target distribution $\pi$ and involutive proposal. Empirical results examine the effect of various step size selection design choices, and show that AutoStep MCMC is competitive with state-of-the-art methods in terms of effective sample size per unit cost on a range of challenging target distributions.
MCMC-driven learning
Feb 14, 2024



This paper is intended to appear as a chapter for the Handbook of Markov Chain Monte Carlo. The goal of this chapter is to unify various problems at the intersection of Markov chain Monte Carlo (MCMC) and machine learning$\unicode{x2014}$which includes black-box variational inference, adaptive MCMC, normalizing flow construction and transport-assisted MCMC, surrogate-likelihood MCMC, coreset construction for MCMC with big data, Markov chain gradient descent, Markovian score climbing, and more$\unicode{x2014}$within one common framework. By doing so, the theory and methods developed for each may be translated and generalized.
Slice Sampling for General Completely Random Measures
Jun 25, 2020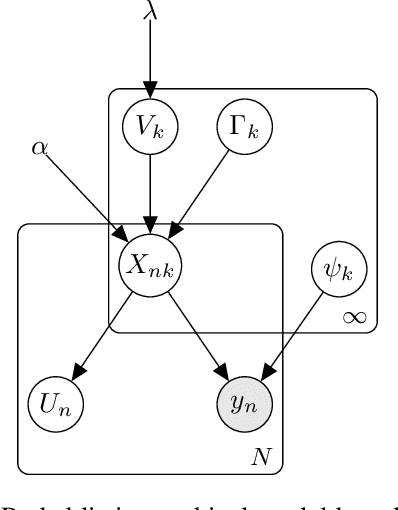
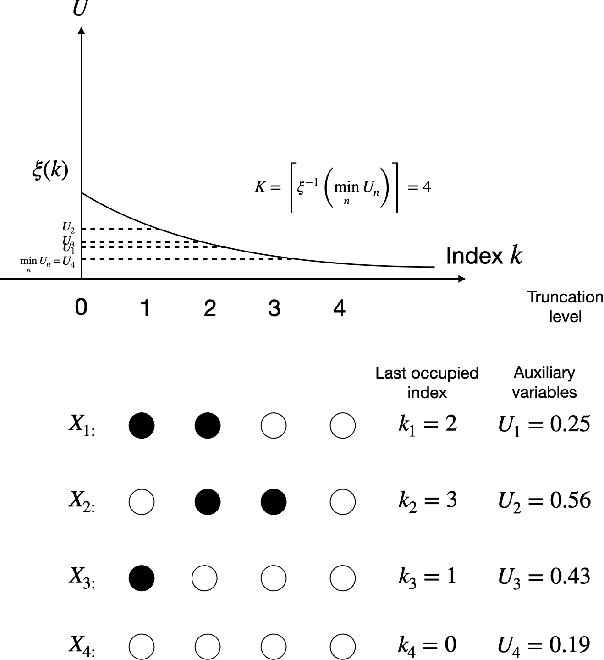
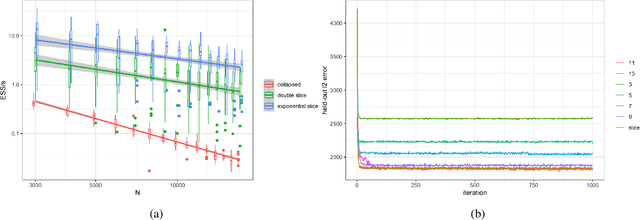
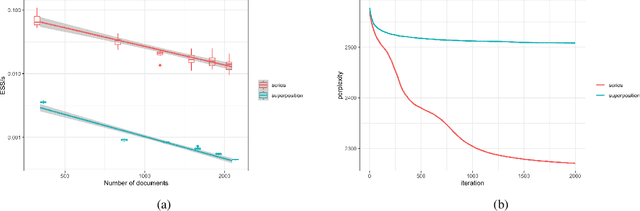
Completely random measures provide a principled approach to creating flexible unsupervised models, where the number of latent features is infinite and the number of features that influence the data grows with the size of the data set. Due to the infinity the latent features, posterior inference requires either marginalization---resulting in dependence structures that prevent efficient computation via parallelization and conjugacy---or finite truncation, which arbitrarily limits the flexibility of the model. In this paper we present a novel Markov chain Monte Carlo algorithm for posterior inference that adaptively sets the truncation level using auxiliary slice variables, enabling efficient, parallelized computation without sacrificing flexibility. In contrast to past work that achieved this on a model-by-model basis, we provide a general recipe that is applicable to the broad class of completely random measure-based priors. The efficacy of the proposed algorithm is evaluated on several popular nonparametric models, demonstrating a higher effective sample size per second compared to algorithms using marginalization as well as a higher predictive performance compared to models employing fixed truncations.
Particle-Gibbs Sampling For Bayesian Feature Allocation Models
Jan 25, 2020


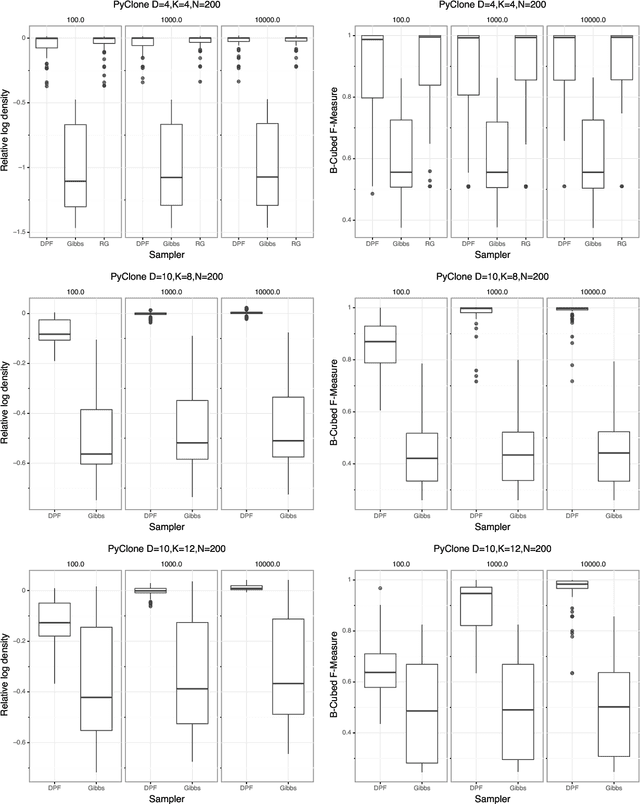
Bayesian feature allocation models are a popular tool for modelling data with a combinatorial latent structure. Exact inference in these models is generally intractable and so practitioners typically apply Markov Chain Monte Carlo (MCMC) methods for posterior inference. The most widely used MCMC strategies rely on an element wise Gibbs update of the feature allocation matrix. These element wise updates can be inefficient as features are typically strongly correlated. To overcome this problem we have developed a Gibbs sampler that can update an entire row of the feature allocation matrix in a single move. However, this sampler is impractical for models with a large number of features as the computational complexity scales exponentially in the number of features. We develop a Particle Gibbs sampler that targets the same distribution as the row wise Gibbs updates, but has computational complexity that only grows linearly in the number of features. We compare the performance of our proposed methods to the standard Gibbs sampler using synthetic data from a range of feature allocation models. Our results suggest that row wise updates using the PG methodology can significantly improve the performance of samplers for feature allocation models.
Blang: Bayesian declarative modelling of arbitrary data structures
Dec 22, 2019

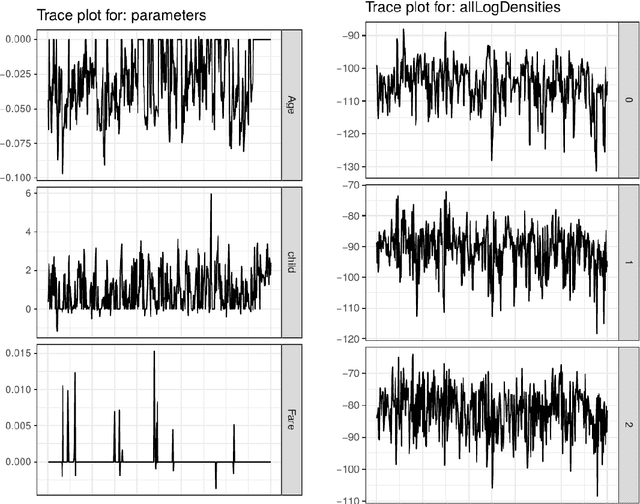
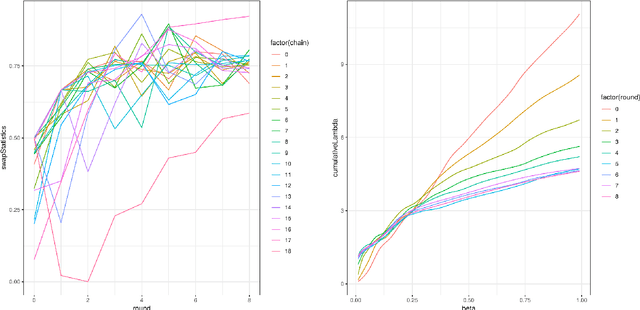
Consider a Bayesian inference problem where a variable of interest does not take values in a Euclidean space. These "non-standard" data structures are in reality fairly common. They are frequently used in problems involving latent discrete factor models, networks, and domain specific problems such as sequence alignments and reconstructions, pedigrees, and phylogenies. In principle, Bayesian inference should be particularly well-suited in such scenarios, as the Bayesian paradigm provides a principled way to obtain confidence assessment for random variables of any type. However, much of the recent work on making Bayesian analysis more accessible and computationally efficient has focused on inference in Euclidean spaces. In this paper, we introduce Blang, a domain specific language (DSL) and library aimed at bridging this gap. Blang allows users to perform Bayesian analysis on arbitrary data types while using a declarative syntax similar to BUGS. Blang is augmented with intuitive language additions to invent data types of the user's choosing. To perform inference at scale on such arbitrary state spaces, Blang leverages recent advances in parallelizable, non-reversible Markov chain Monte Carlo methods.
Analysis of high-dimensional Continuous Time Markov Chains using the Local Bouncy Particle Sampler
Jun 03, 2019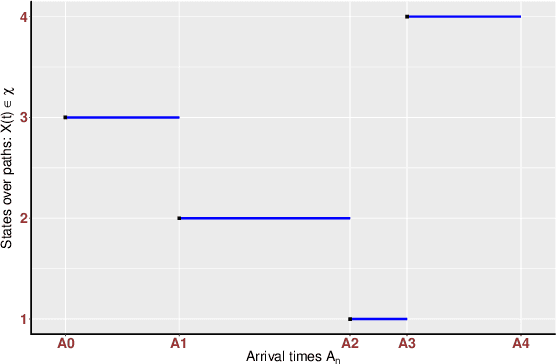


Sampling the parameters of high-dimensional Continuous Time Markov Chains (CTMC) is a challenging problem with important applications in many fields of applied statistics. In this work a recently proposed type of non-reversible rejection-free Markov Chain Monte Carlo (MCMC) sampler, the Bouncy Particle Sampler (BPS), is brought to bear to this problem. BPS has demonstrated its favorable computational efficiency compared with state-of-the-art MCMC algorithms, however to date applications to real-data scenario were scarce. An important aspect of the practical implementation of BPS is the simulation of event times. Default implementations use conservative thinning bounds. Such bounds can slow down the algorithm and limit the computational performance. Our paper develops an algorithm with an exact analytical solution to the random event times in the context of CTMCs. Our local version of BPS algorithm takes advantage of the sparse structure in the target factor graph and we also provide a framework for assessing the computational complexity of local BPS algorithms.
Scalable Metropolis-Hastings for Exact Bayesian Inference with Large Datasets
Jan 30, 2019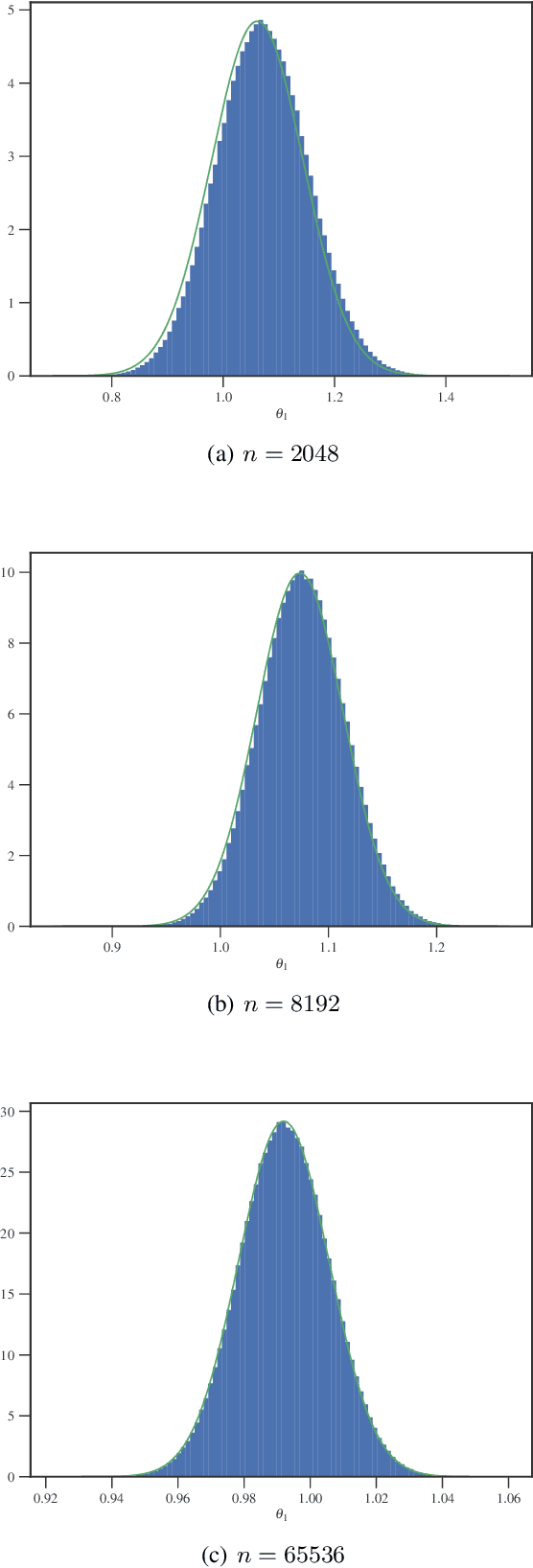
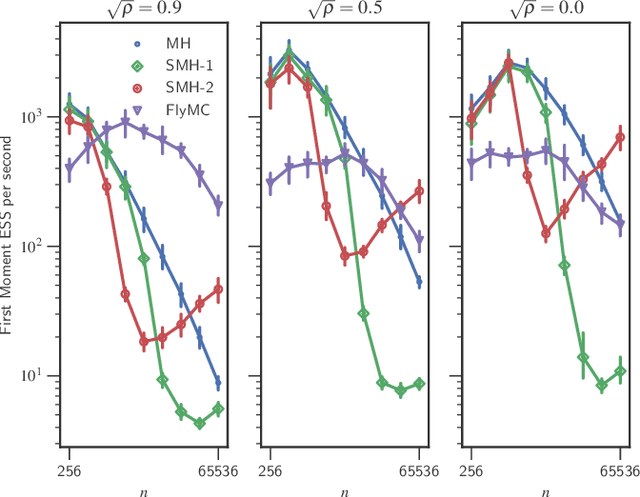
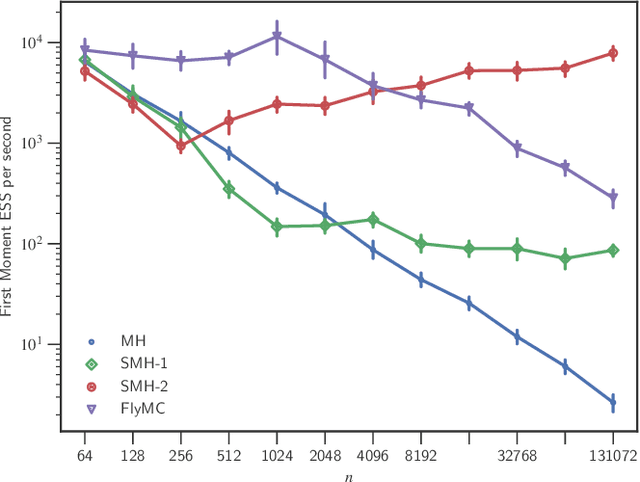
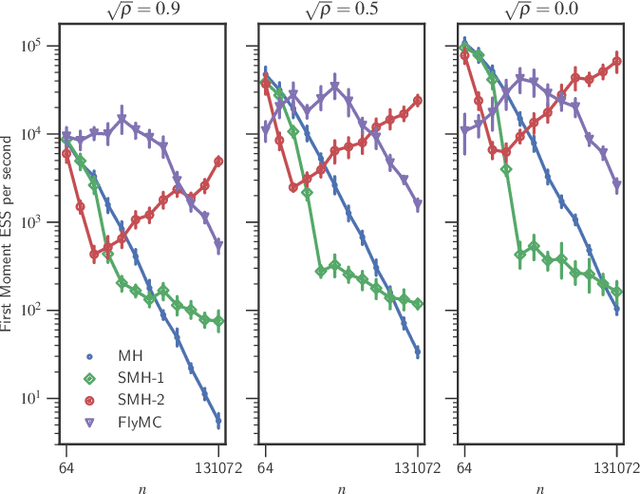
Bayesian inference via standard Markov Chain Monte Carlo (MCMC) methods such as Metropolis-Hastings is too computationally intensive to handle large datasets, since the cost per step usually scales like $O(n)$ in the number of data points $n$. We propose the Scalable Metropolis-Hastings (SMH) kernel that exploits Gaussian concentration of the posterior to require processing on average only $O(1)$ or even $O(1/\sqrt{n})$ data points per step. This scheme is based on a combination of factorized acceptance probabilities, procedures for fast simulation of Bernoulli processes, and control variate ideas. Contrary to many MCMC subsampling schemes such as fixed step-size Stochastic Gradient Langevin Dynamics, our approach is exact insofar as the invariant distribution is the true posterior and not an approximation to it. We characterise the performance of our algorithm theoretically, and give realistic and verifiable conditions under which it is geometrically ergodic. This theory is borne out by empirical results that demonstrate overall performance benefits over standard Metropolis-Hastings and various subsampling algorithms.
Unbounded Bayesian Optimization via Regularization
Aug 14, 2015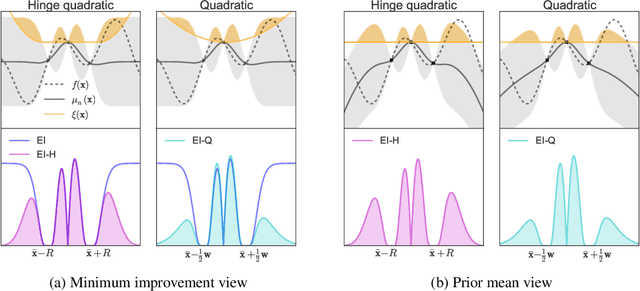
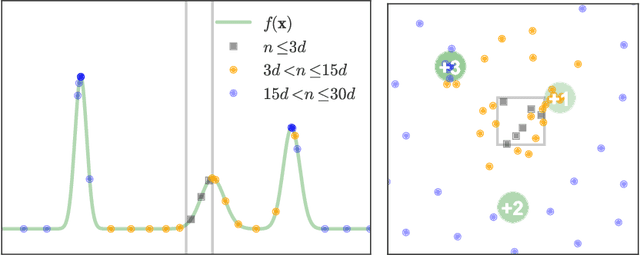


Bayesian optimization has recently emerged as a popular and efficient tool for global optimization and hyperparameter tuning. Currently, the established Bayesian optimization practice requires a user-defined bounding box which is assumed to contain the optimizer. However, when little is known about the probed objective function, it can be difficult to prescribe such bounds. In this work we modify the standard Bayesian optimization framework in a principled way to allow automatic resizing of the search space. We introduce two alternative methods and compare them on two common synthetic benchmarking test functions as well as the tasks of tuning the stochastic gradient descent optimizer of a multi-layered perceptron and a convolutional neural network on MNIST.