 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Metropolis-Hastings for Exact Bayesian Inference with Large Datasets
Jan 30, 2019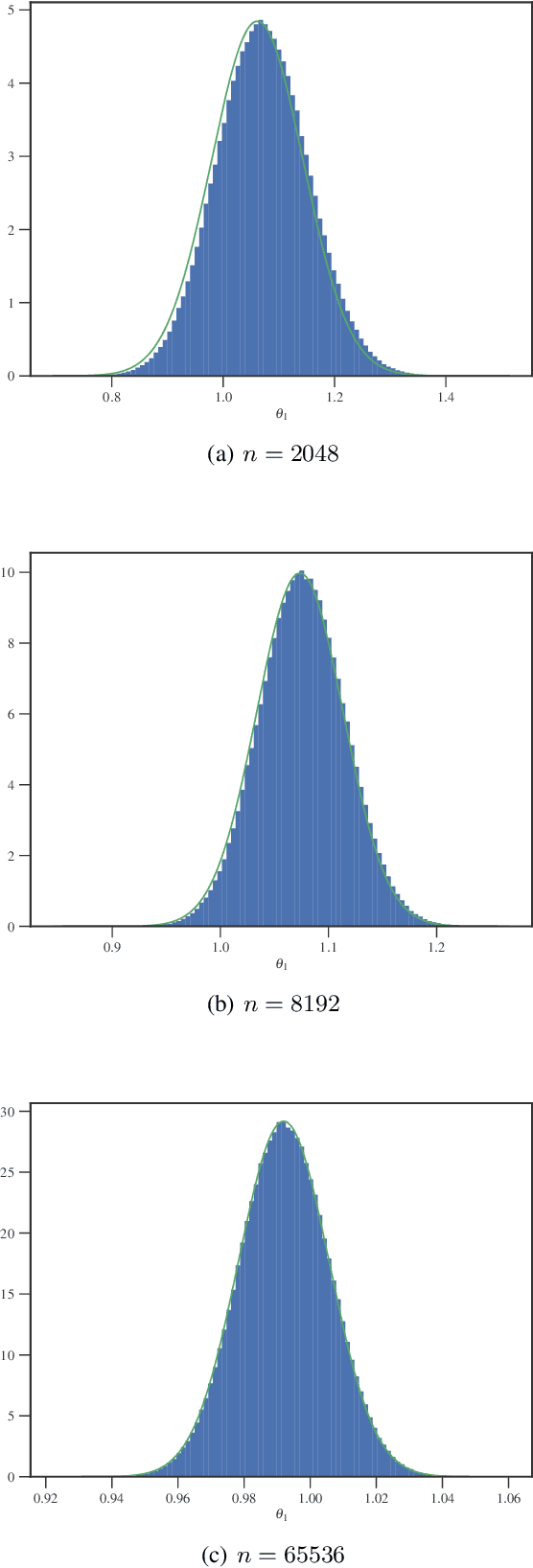
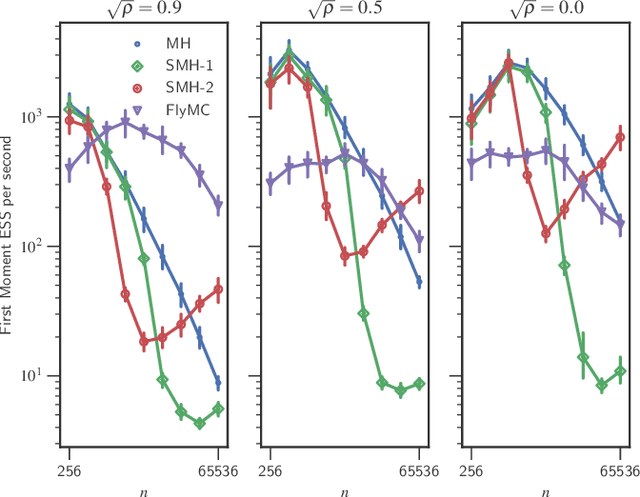
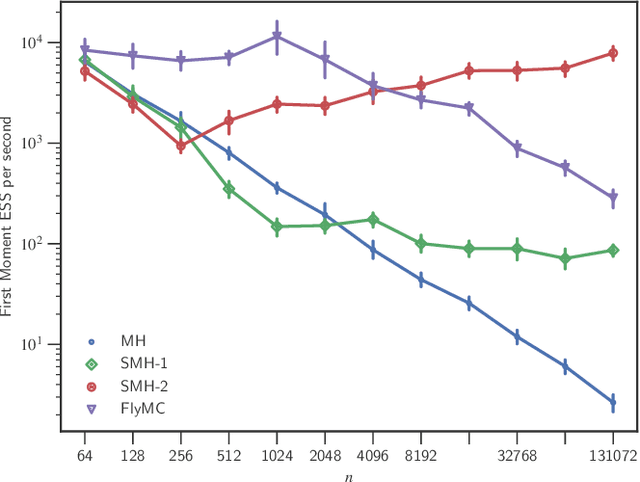
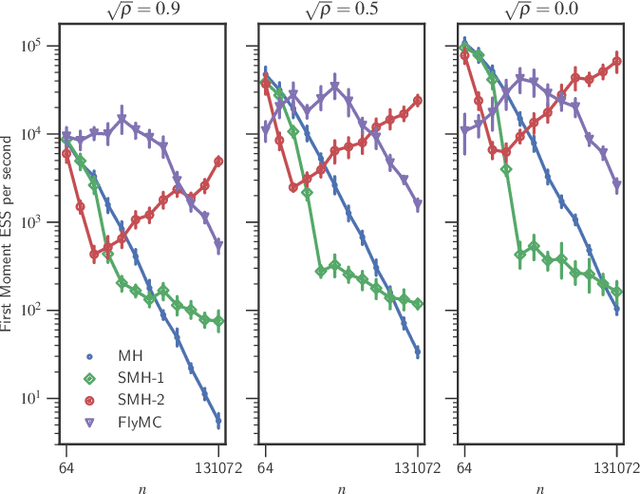
Bayesian inference via standard Markov Chain Monte Carlo (MCMC) methods such as Metropolis-Hastings is too computationally intensive to handle large datasets, since the cost per step usually scales like $O(n)$ in the number of data points $n$. We propose the Scalable Metropolis-Hastings (SMH) kernel that exploits Gaussian concentration of the posterior to require processing on average only $O(1)$ or even $O(1/\sqrt{n})$ data points per step. This scheme is based on a combination of factorized acceptance probabilities, procedures for fast simulation of Bernoulli processes, and control variate ideas. Contrary to many MCMC subsampling schemes such as fixed step-size Stochastic Gradient Langevin Dynamics, our approach is exact insofar as the invariant distribution is the true posterior and not an approximation to it. We characterise the performance of our algorithm theoretically, and give realistic and verifiable conditions under which it is geometrically ergodic. This theory is borne out by empirical results that demonstrate overall performance benefits over standard Metropolis-Hastings and various subsampling algorithms.