 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Metropolis-Hastings for Exact Bayesian Inference with Large Datasets
Jan 30, 2019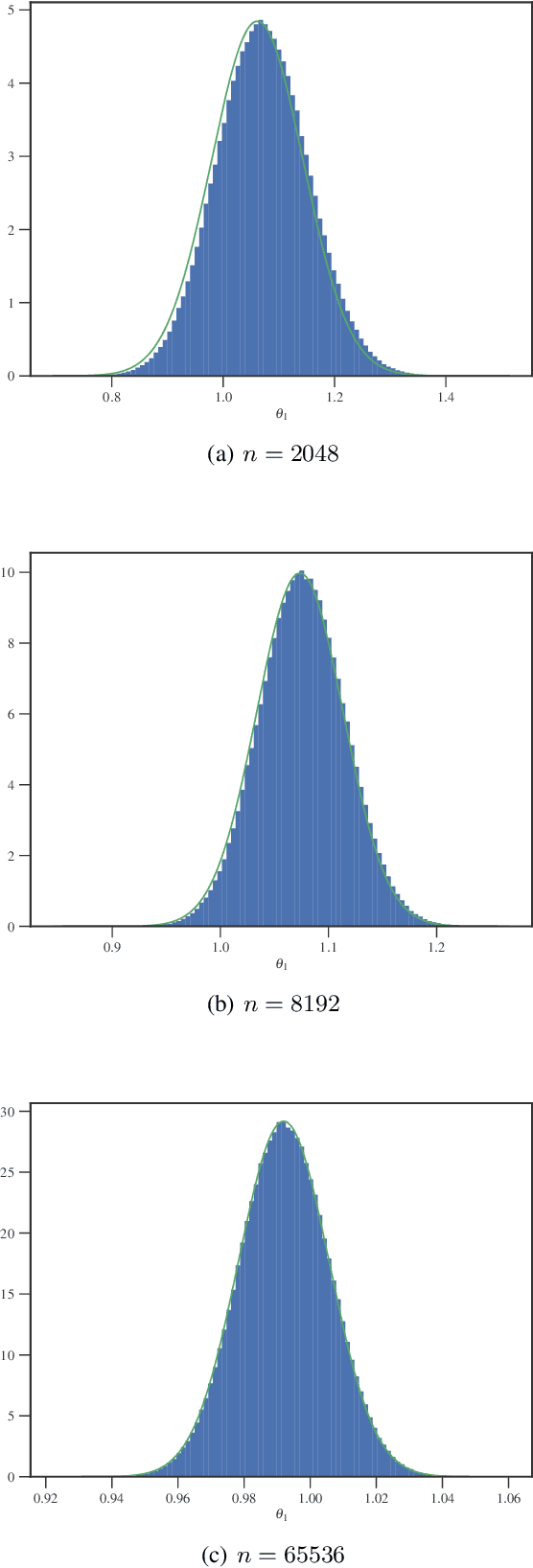
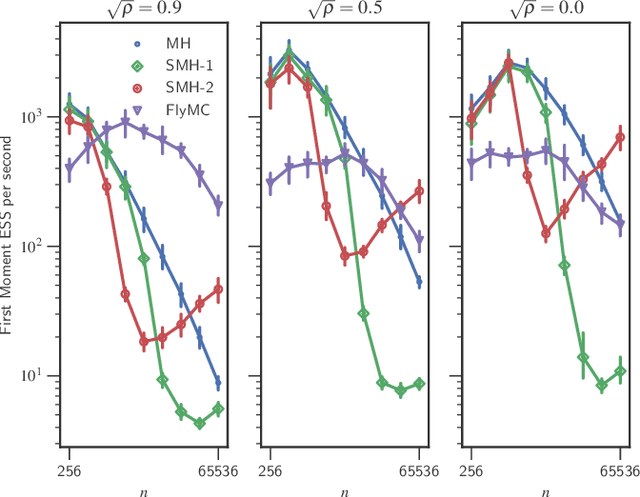
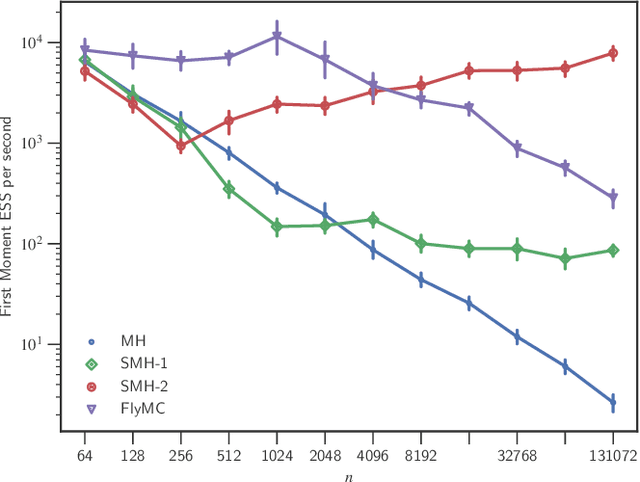
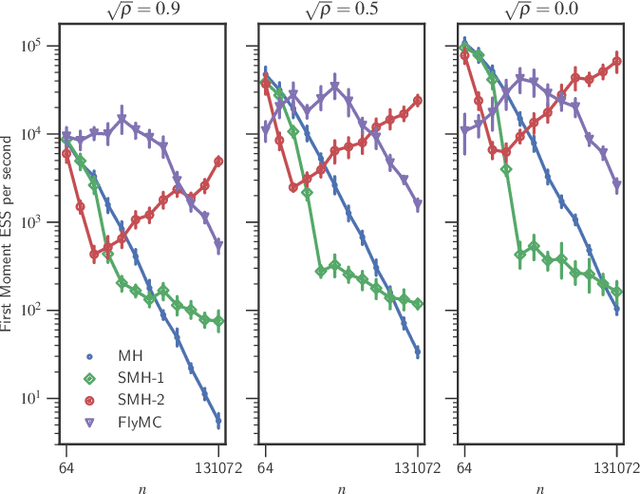
Bayesian inference via standard Markov Chain Monte Carlo (MCMC) methods such as Metropolis-Hastings is too computationally intensive to handle large datasets, since the cost per step usually scales like $O(n)$ in the number of data points $n$. We propose the Scalable Metropolis-Hastings (SMH) kernel that exploits Gaussian concentration of the posterior to require processing on average only $O(1)$ or even $O(1/\sqrt{n})$ data points per step. This scheme is based on a combination of factorized acceptance probabilities, procedures for fast simulation of Bernoulli processes, and control variate ideas. Contrary to many MCMC subsampling schemes such as fixed step-size Stochastic Gradient Langevin Dynamics, our approach is exact insofar as the invariant distribution is the true posterior and not an approximation to it. We characterise the performance of our algorithm theoretically, and give realistic and verifiable conditions under which it is geometrically ergodic. This theory is borne out by empirical results that demonstrate overall performance benefits over standard Metropolis-Hastings and various subsampling algorithms.
On Nesting Monte Carlo Estimators
May 23, 2018
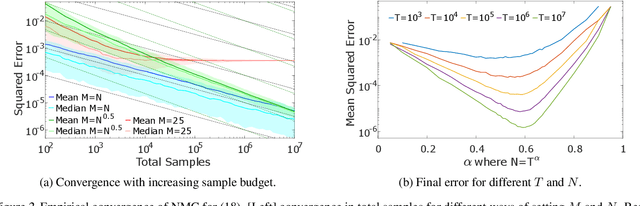
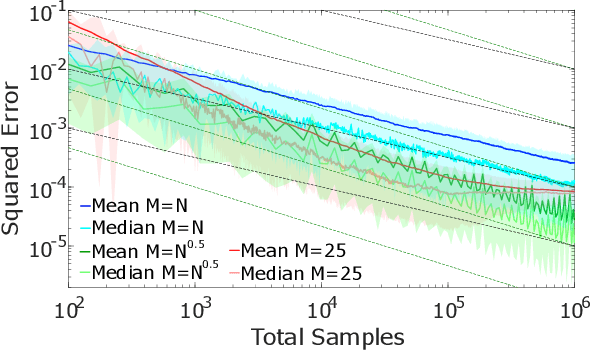
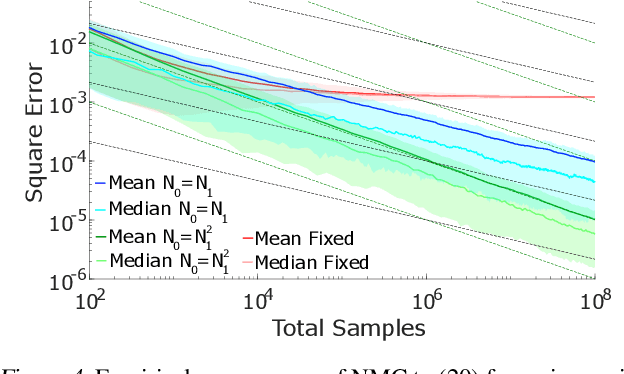
Many problems in machine learning and statistics involve nested expectations and thus do not permit conventional Monte Carlo (MC) estimation. For such problems, one must nest estimators, such that terms in an outer estimator themselves involve calculation of a separate, nested, estimation. We investigate the statistical implications of nesting MC estimators, including cases of multiple levels of nesting, and establish the conditions under which they converge. We derive corresponding rates of convergence and provide empirical evidence that these rates are observed in practice. We further establish a number of pitfalls that can arise from naive nesting of MC estimators, provide guidelines about how these can be avoided, and lay out novel methods for reformulating certain classes of nested expectation problems into single expectations, leading to improved convergence rates. We demonstrate the applicability of our work by using our results to develop a new estimator for discrete Bayesian experimental design problems and derive error bounds for a class of variational objectives.
Online Learning Rate Adaptation with Hypergradient Descent
Feb 26, 2018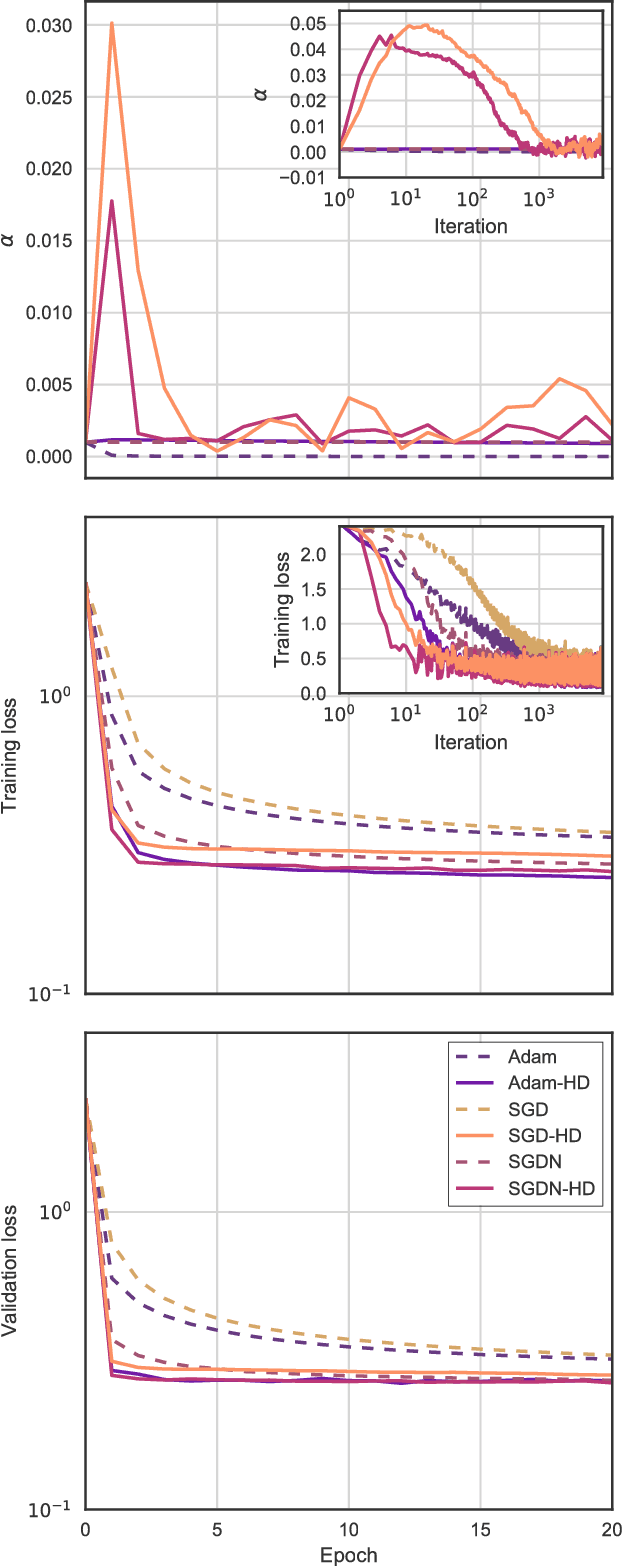
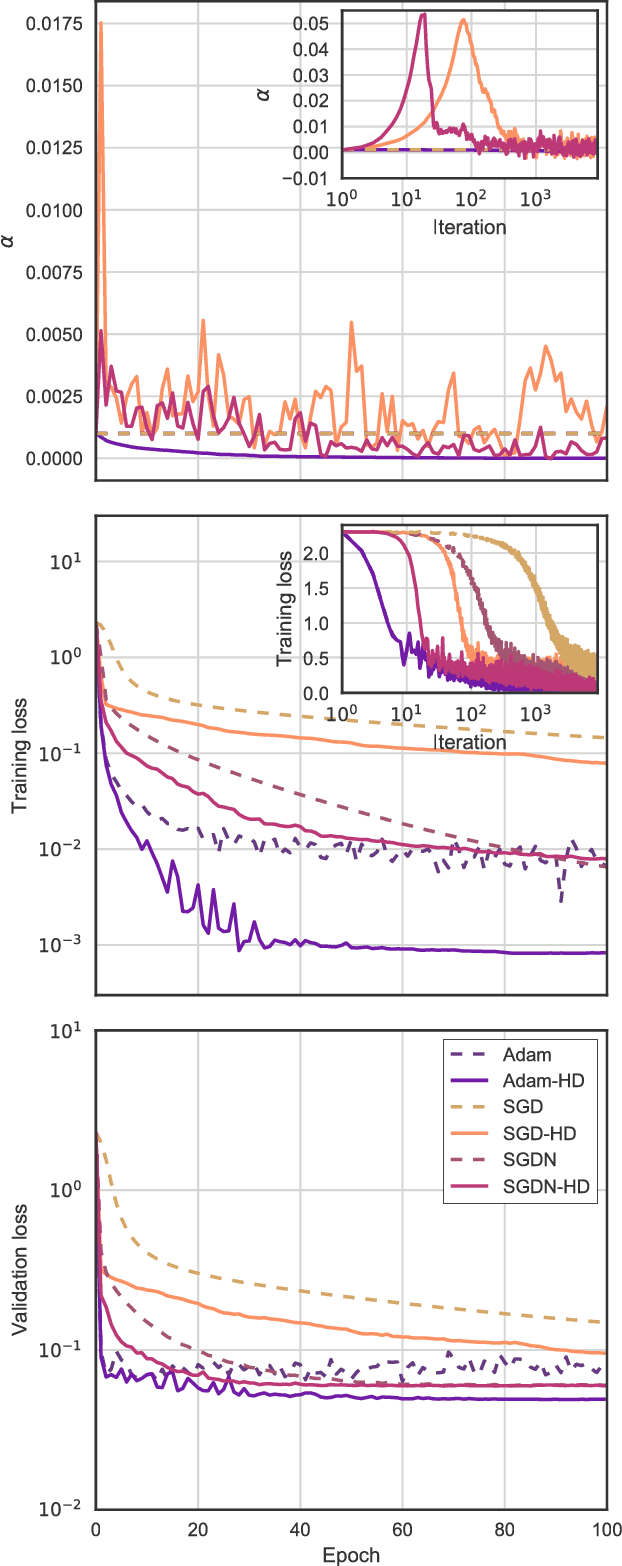
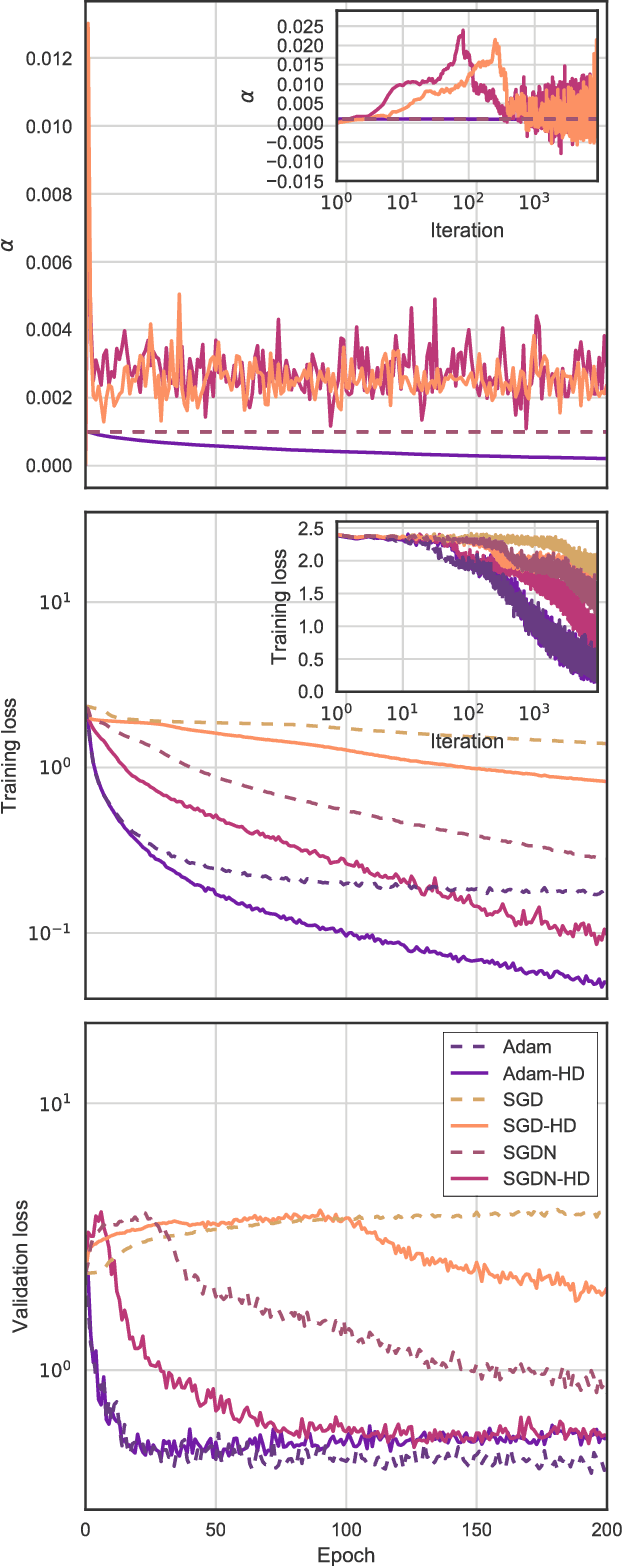
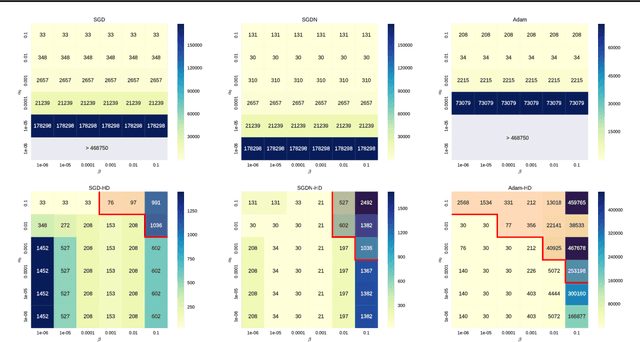
We introduce a general method for improving the convergence rate of gradient-based optimizers that is easy to implement and works well in practice. We demonstrate the effectiveness of the method in a range of optimization problems by applying it to stochastic gradient descent, stochastic gradient descent with Nesterov momentum, and Adam, showing that it significantly reduces the need for the manual tuning of the initial learning rate for these commonly used algorithms. Our method works by dynamically updating the learning rate during optimization using the gradient with respect to the learning rate of the update rule itself. Computing this "hypergradient" needs little additional computation, requires only one extra copy of the original gradient to be stored in memory, and relies upon nothing more than what is provided by reverse-mode automatic differentiation.
* 11 pages, 4 figures
On the Pitfalls of Nested Monte Carlo
Dec 03, 2016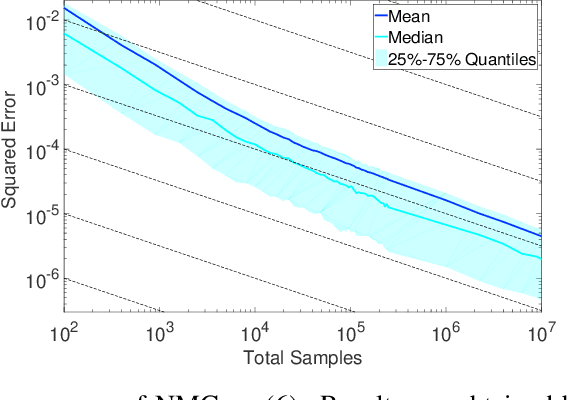
There is an increasing interest in estimating expectations outside of the classical inference framework, such as for models expressed as probabilistic programs. Many of these contexts call for some form of nested inference to be applied. In this paper, we analyse the behaviour of nested Monte Carlo (NMC) schemes, for which classical convergence proofs are insufficient. We give conditions under which NMC will converge, establish a rate of convergence, and provide empirical data that suggests that this rate is observable in practice. Finally, we prove that general-purpose nested inference schemes are inherently biased. Our results serve to warn of the dangers associated with naive composition of inference and models.