 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Cognitive Supersensing in Multimodal Large Language Model
Feb 02, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable success in open-vocabulary perceptual tasks, yet their ability to solve complex cognitive problems remains limited, especially when visual details are abstract and require visual memory. Current approaches primarily scale Chain-of-Thought (CoT) reasoning in the text space, even when language alone is insufficient for clear and structured reasoning, and largely neglect visual reasoning mechanisms analogous to the human visuospatial sketchpad and visual imagery. To mitigate this deficiency, we introduce Cognitive Supersensing, a novel training paradigm that endows MLLMs with human-like visual imagery capabilities by integrating a Latent Visual Imagery Prediction (LVIP) head that jointly learns sequences of visual cognitive latent embeddings and aligns them with the answer, thereby forming vision-based internal reasoning chains. We further introduce a reinforcement learning stage that optimizes text reasoning paths based on this grounded visual latent. To evaluate the cognitive capabilities of MLLMs, we present CogSense-Bench, a comprehensive visual question answering (VQA) benchmark assessing five cognitive dimensions. Extensive experiments demonstrate that MLLMs trained with Cognitive Supersensing significantly outperform state-of-the-art baselines on CogSense-Bench and exhibit superior generalization on out-of-domain mathematics and science VQA benchmarks, suggesting that internal visual imagery is potentially key to bridging the gap between perceptual recognition and cognitive understanding. We will open-source the CogSense-Bench and our model weights.
PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation
Jan 11, 2026Recent advancements in vision-language-action (VLA) models have shown promise in robotic manipulation, yet they continue to struggle with long-horizon, multi-step tasks. Existing methods lack internal reasoning mechanisms that can identify task-relevant interaction cues or track progress within a subtask, leading to critical execution errors such as repeated actions, missed steps, and premature termination. To address these challenges, we introduce PALM, a VLA framework that structures policy learning around interaction-centric affordance reasoning and subtask progress cues. PALM distills complementary affordance representations that capture object relevance, contact geometry, spatial placements, and motion dynamics, and serve as task-relevant anchors for visuomotor control. To further stabilize long-horizon execution, PALM predicts continuous within-subtask progress, enabling seamless subtask transitions. Across extensive simulation and real-world experiments, PALM consistently outperforms baselines, achieving a 91.8% success rate on LIBERO-LONG, a 12.5% improvement in average length on CALVIN ABC->D, and a 2x improvement over real-world baselines across three long-horizon generalization settings.
CoRe3D: Collaborative Reasoning as a Foundation for 3D Intelligence
Dec 14, 2025Recent advances in large multimodal models suggest that explicit reasoning mechanisms play a critical role in improving model reliability, interpretability, and cross-modal alignment. While such reasoning-centric approaches have been proven effective in language and vision tasks, their extension to 3D remains underdeveloped. CoRe3D introduces a unified 3D understanding and generation reasoning framework that jointly operates over semantic and spatial abstractions, enabling high-level intent inferred from language to directly guide low-level 3D content formation. Central to this design is a spatially grounded reasoning representation that decomposes 3D latent space into localized regions, allowing the model to reason over geometry in a compositional and procedural manner. By tightly coupling semantic chain-of-thought inference with structured spatial reasoning, CoRe3D produces 3D outputs that exhibit strong local consistency and faithful alignment with linguistic descriptions.
MetaLogic: Robustness Evaluation of Text-to-Image Models via Logically Equivalent Prompts
Oct 01, 2025Recent advances in text-to-image (T2I) models, especially diffusion-based architectures, have significantly improved the visual quality of generated images. However, these models continue to struggle with a critical limitation: maintaining semantic consistency when input prompts undergo minor linguistic variations. Despite being logically equivalent, such prompt pairs often yield misaligned or semantically inconsistent images, exposing a lack of robustness in reasoning and generalisation. To address this, we propose MetaLogic, a novel evaluation framework that detects T2I misalignment without relying on ground truth images. MetaLogic leverages metamorphic testing, generating image pairs from prompts that differ grammatically but are semantically identical. By directly comparing these image pairs, the framework identifies inconsistencies that signal failures in preserving the intended meaning, effectively diagnosing robustness issues in the model's logic understanding. Unlike existing evaluation methods that compare a generated image to a single prompt, MetaLogic evaluates semantic equivalence between paired images, offering a scalable, ground-truth-free approach to identifying alignment failures. It categorises these alignment errors (e.g., entity omission, duplication, positional misalignment) and surfaces counterexamples that can be used for model debugging and refinement. We evaluate MetaLogic across multiple state-of-the-art T2I models and reveal consistent robustness failures across a range of logical constructs. We find that even the SOTA text-to-image models like Flux.dev and DALLE-3 demonstrate a 59 percent and 71 percent misalignment rate, respectively. Our results show that MetaLogic is not only efficient and scalable, but also effective in uncovering fine-grained logical inconsistencies that are overlooked by existing evaluation metrics.
An Explainable Emotion Alignment Framework for LLM-Empowered Agent in Metaverse Service Ecosystem
Jul 30, 2025



Metaverse service is a product of the convergence between Metaverse and service systems, designed to address service-related challenges concerning digital avatars, digital twins, and digital natives within Metaverse. With the rise of large language models (LLMs), agents now play a pivotal role in Metaverse service ecosystem, serving dual functions: as digital avatars representing users in the virtual realm and as service assistants (or NPCs) providing personalized support. However, during the modeling of Metaverse service ecosystems, existing LLM-based agents face significant challenges in bridging virtual-world services with real-world services, particularly regarding issues such as character data fusion, character knowledge association, and ethical safety concerns. This paper proposes an explainable emotion alignment framework for LLM-based agents in Metaverse Service Ecosystem. It aims to integrate factual factors into the decision-making loop of LLM-based agents, systematically demonstrating how to achieve more relational fact alignment for these agents. Finally, a simulation experiment in the Offline-to-Offline food delivery scenario is conducted to evaluate the effectiveness of this framework, obtaining more realistic social emergence.
Reflection-Window Decoding: Text Generation with Selective Refinement
Feb 05, 2025



The autoregressive decoding for text generation in large language models (LLMs), while widely used, is inherently suboptimal due to the lack of a built-in mechanism to perform refinement and/or correction of the generated content. In this paper, we consider optimality in terms of the joint probability over the generated response, when jointly considering all tokens at the same time. We theoretically characterize the potential deviation of the autoregressively generated response from its globally optimal counterpart that is of the same length. Our analysis suggests that we need to be cautious when noticeable uncertainty arises during text generation, which may signal the sub-optimality of the generation history. To address the pitfall of autoregressive decoding for text generation, we propose an approach that incorporates a sliding reflection window and a pausing criterion, such that refinement and generation can be carried out interchangeably as the decoding proceeds. Our selective refinement framework strikes a balance between efficiency and optimality, and our extensive experimental results demonstrate the effectiveness of our approach.
Controllable Video Generation with Provable Disentanglement
Feb 04, 2025



Controllable video generation remains a significant challenge, despite recent advances in generating high-quality and consistent videos. Most existing methods for controlling video generation treat the video as a whole, neglecting intricate fine-grained spatiotemporal relationships, which limits both control precision and efficiency. In this paper, we propose Controllable Video Generative Adversarial Networks (CoVoGAN) to disentangle the video concepts, thus facilitating efficient and independent control over individual concepts. Specifically, following the minimal change principle, we first disentangle static and dynamic latent variables. We then leverage the sufficient change property to achieve component-wise identifiability of dynamic latent variables, enabling independent control over motion and identity. To establish the theoretical foundation, we provide a rigorous analysis demonstrating the identifiability of our approach. Building on these theoretical insights, we design a Temporal Transition Module to disentangle latent dynamics. To enforce the minimal change principle and sufficient change property, we minimize the dimensionality of latent dynamic variables and impose temporal conditional independence. To validate our approach, we integrate this module as a plug-in for GANs. Extensive qualitative and quantitative experiments on various video generation benchmarks demonstrate that our method significantly improves generation quality and controllability across diverse real-world scenarios.
Flow: A Modular Approach to Automated Agentic Workflow Generation
Jan 14, 2025



Multi-agent frameworks powered by large language models (LLMs) have demonstrated great success in automated planning and task execution. However, the effective adjustment of Agentic workflows during execution has not been well-studied. A effective workflow adjustment is crucial, as in many real-world scenarios, the initial plan must adjust to unforeseen challenges and changing conditions in real-time to ensure the efficient execution of complex tasks. In this paper, we define workflows as an activity-on-vertex (AOV) graphs. We continuously refine the workflow by dynamically adjusting task allocations based on historical performance and previous AOV with LLM agents. To further enhance system performance, we emphasize modularity in workflow design based on measuring parallelism and dependence complexity. Our proposed multi-agent framework achieved efficient sub-task concurrent execution, goal achievement, and error tolerance. Empirical results across different practical tasks demonstrate dramatic improvements in the efficiency of multi-agent frameworks through dynamic workflow updating and modularization.
Symmetry Adapted Residual Neural Network Diabatization: Conical Intersections in Aniline Photodissociation
Nov 03, 2024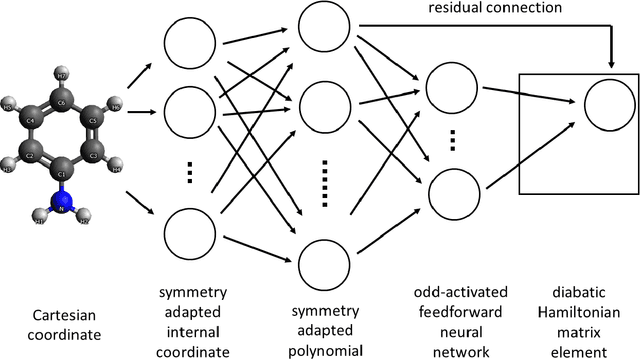
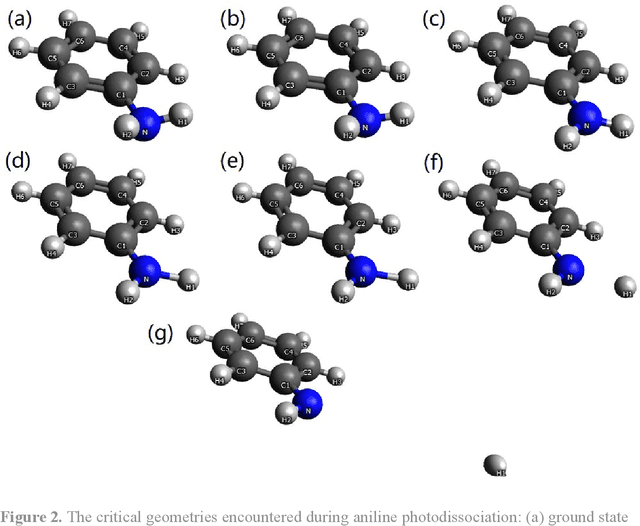
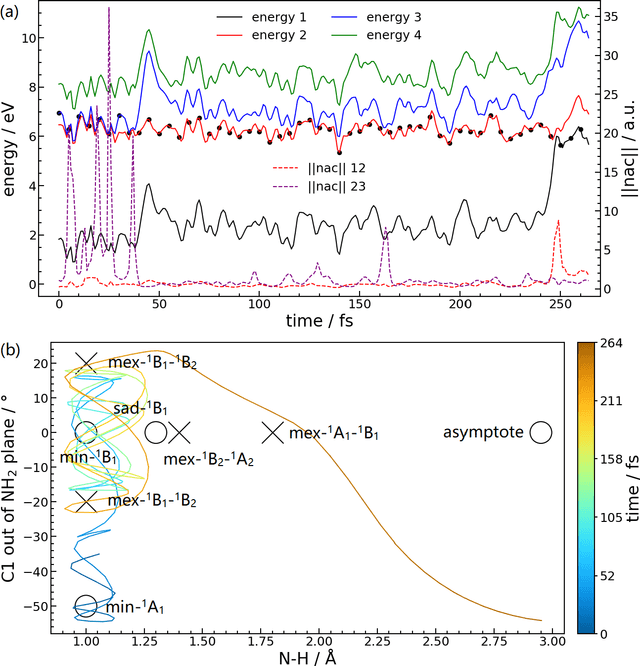
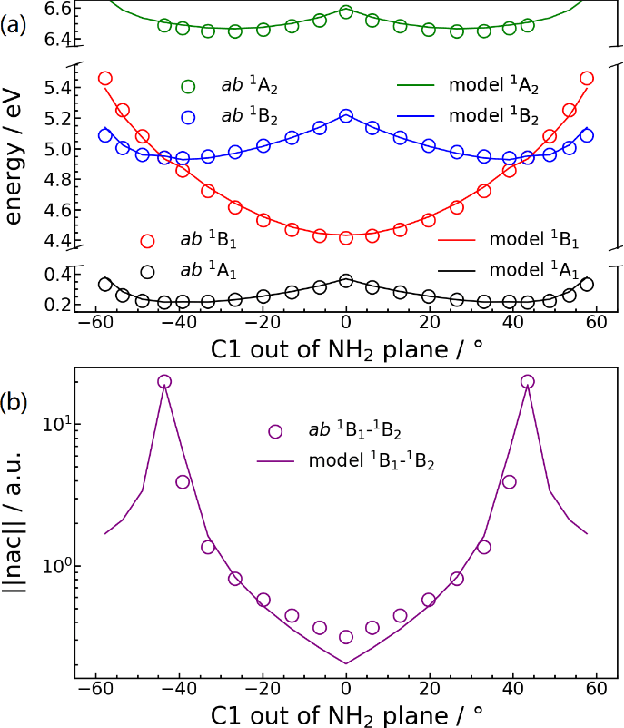
We present a symmetry adapted residual neural network (SAResNet) diabatization method to construct quasi-diabatic Hamiltonians that accurately represent ab initio adiabatic energies, energy gradients, and nonadiabatic couplings for moderate sized systems. Our symmetry adapted neural network inherits from the pioneering symmetry adapted polynomial and fundamental invariant neural network diabatization methods to exploit the power of neural network along with the transparent symmetry adaptation of polynomial for both symmetric and asymmetric irreducible representations. In addition, our symmetry adaptation provides a unified framework for symmetry adapted polynomial and symmetry adapted neural network, enabling the adoption of the residual neural network architecture, which is a powerful descendant of the pioneering feedforward neural network. Our SAResNet is applied to construct the full 36-dimensional coupled diabatic potential energy surfaces for aniline N-H bond photodissociation, with 2,269 data points and 32,640 trainable parameters and 190 cm-1 root mean square deviation in energy. In addition to the experimentally observed {\pi}{\pi}* and {\pi}Rydberg/{\pi}{\sigma}* states, a higher state (HOMO - 1 {\pi} to Rydberg/{\sigma}* excitation) is found to introduce an induced geometric phase effect thus indirectly participate in the photodissociation process.
Continual Learning of Nonlinear Independent Representations
Aug 11, 2024
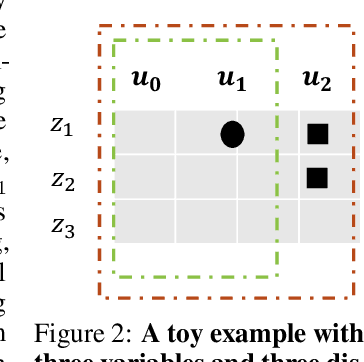
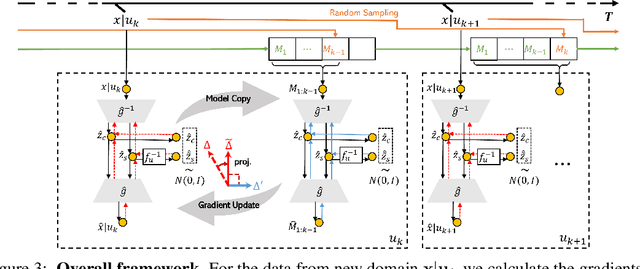
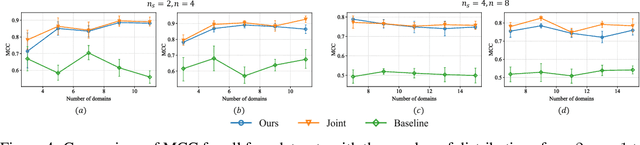
Identifying the causal relations between interested variables plays a pivotal role in representation learning as it provides deep insights into the dataset. Identifiability, as the central theme of this approach, normally hinges on leveraging data from multiple distributions (intervention, distribution shift, time series, etc.). Despite the exciting development in this field, a practical but often overlooked problem is: what if those distribution shifts happen sequentially? In contrast, any intelligence possesses the capacity to abstract and refine learned knowledge sequentially -- lifelong learning. In this paper, with a particular focus on the nonlinear independent component analysis (ICA) framework, we move one step forward toward the question of enabling models to learn meaningful (identifiable) representations in a sequential manner, termed continual causal representation learning. We theoretically demonstrate that model identifiability progresses from a subspace level to a component-wise level as the number of distributions increases. Empirically, we show that our method achieves performance comparable to nonlinear ICA methods trained jointly on multiple offline distributions and, surprisingly, the incoming new distribution does not necessarily benefit the identification of all latent variables.