 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoRe: Modular Representations for Principled Continual Representation Learning on Squantial Data
May 14, 2026Continual learning requires models to adapt to new data while preserving previously acquired knowledge. At its core, this challenge can be viewed as principled one-step adaptation: incorporating new information with minimal interference to existing representations. Most existing approaches address this challenge by modifying model parameters or architectures in a supervised, task-specific manner. However, the underlying issue is representational: tasks require distinct yet structured representations that can be selectively updated without disrupting representations, while structure should reflect intrinsic organization in the data rather than task boundaries. In sequential data, time-delayed dependencies provide a natural signal for uncovering this organization, revealing how fundamental representations give rise to more specific ones. Inspired by the modular organization of the human brain, we propose MoRe, a framework that identifies modularity in the representation itself rather than allocating it at the architectural level. MoRe decomposes knowledge into a hierarchy of fundamental and specific modules with identifiability guarantees, enabling principled module reuse, alignment, and expansion during adaptation while preserving old modules by construction. Experiments on synthetic benchmarks and real-world LLM activations demonstrate interpretable hierarchical structure, improved plasticity-stability trade-offs, suggesting MoRe as a principled foundation for continual adaptation
Beyond the Black Box: Identifiable Interpretation and Control in Generative Models via Causal Minimality
Dec 11, 2025Deep generative models, while revolutionizing fields like image and text generation, largely operate as opaque black boxes, hindering human understanding, control, and alignment. While methods like sparse autoencoders (SAEs) show remarkable empirical success, they often lack theoretical guarantees, risking subjective insights. Our primary objective is to establish a principled foundation for interpretable generative models. We demonstrate that the principle of causal minimality -- favoring the simplest causal explanation -- can endow the latent representations of diffusion vision and autoregressive language models with clear causal interpretation and robust, component-wise identifiable control. We introduce a novel theoretical framework for hierarchical selection models, where higher-level concepts emerge from the constrained composition of lower-level variables, better capturing the complex dependencies in data generation. Under theoretically derived minimality conditions (manifesting as sparsity or compression constraints), we show that learned representations can be equivalent to the true latent variables of the data-generating process. Empirically, applying these constraints to leading generative models allows us to extract their innate hierarchical concept graphs, offering fresh insights into their internal knowledge organization. Furthermore, these causally grounded concepts serve as levers for fine-grained model steering, paving the way for transparent, reliable systems.
Multi-Scale Feature Fusion and Graph Neural Network Integration for Text Classification with Large Language Models
Nov 07, 2025This study investigates a hybrid method for text classification that integrates deep feature extraction from large language models, multi-scale fusion through feature pyramids, and structured modeling with graph neural networks to enhance performance in complex semantic contexts. First, the large language model captures contextual dependencies and deep semantic representations of the input text, providing a rich feature foundation for subsequent modeling. Then, based on multi-level feature representations, the feature pyramid mechanism effectively integrates semantic features of different scales, balancing global information and local details to construct hierarchical semantic expressions. Furthermore, the fused features are transformed into graph representations, and graph neural networks are employed to capture latent semantic relations and logical dependencies in the text, enabling comprehensive modeling of complex interactions among semantic units. On this basis, the readout and classification modules generate the final category predictions. The proposed method demonstrates significant advantages in robustness alignment experiments, outperforming existing models on ACC, F1-Score, AUC, and Precision, which verifies the effectiveness and stability of the framework. This study not only constructs an integrated framework that balances global and local information as well as semantics and structure, but also provides a new perspective for multi-scale feature fusion and structured semantic modeling in text classification tasks.
LLM-Centric RAG with Multi-Granular Indexing and Confidence Constraints
Oct 30, 2025This paper addresses the issues of insufficient coverage, unstable results, and limited reliability in retrieval-augmented generation under complex knowledge environments, and proposes a confidence control method that integrates multi-granularity memory indexing with uncertainty estimation. The method builds a hierarchical memory structure that divides knowledge representations into different levels of granularity, enabling dynamic indexing and retrieval from local details to global context, and thus establishing closer semantic connections between retrieval and generation. On this basis, an uncertainty estimation mechanism is introduced to explicitly constrain and filter low-confidence paths during the generation process, allowing the model to maintain information coverage while effectively suppressing noise and false content. The overall optimization objective consists of generation loss, entropy constraints, and variance regularization, forming a unified confidence control framework. In the experiments, comprehensive sensitivity tests and comparative analyses were designed, covering hyperparameters, environmental conditions, and data structures, to verify the stability and robustness of the proposed method across different scenarios. The results show that the method achieves superior performance over existing models in QA accuracy, retrieval recall, ranking quality, and factual consistency, demonstrating the effectiveness of combining multi-granularity indexing with confidence control. This study not only provides a new technical pathway for retrieval-augmented generation but also offers practical evidence for improving the reliability and controllability of large models in complex contexts.
Score-based Greedy Search for Structure Identification of Partially Observed Linear Causal Models
Oct 05, 2025Identifying the structure of a partially observed causal system is essential to various scientific fields. Recent advances have focused on constraint-based causal discovery to solve this problem, and yet in practice these methods often face challenges related to multiple testing and error propagation. These issues could be mitigated by a score-based method and thus it has raised great attention whether there exists a score-based greedy search method that can handle the partially observed scenario. In this work, we propose the first score-based greedy search method for the identification of structure involving latent variables with identifiability guarantees. Specifically, we propose Generalized N Factor Model and establish the global consistency: the true structure including latent variables can be identified up to the Markov equivalence class by using score. We then design Latent variable Greedy Equivalence Search (LGES), a greedy search algorithm for this class of model with well-defined operators, which search very efficiently over the graph space to find the optimal structure. Our experiments on both synthetic and real-life data validate the effectiveness of our method (code will be publicly available).
Step-Aware Policy Optimization for Reasoning in Diffusion Large Language Models
Oct 02, 2025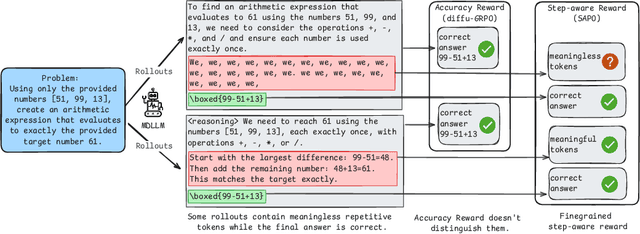
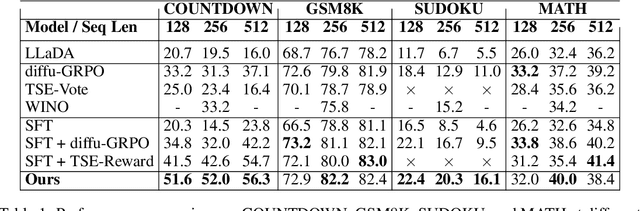
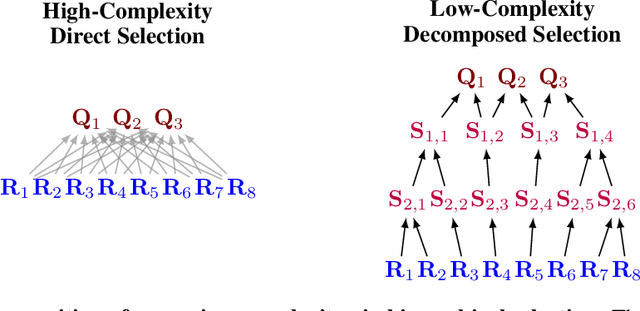
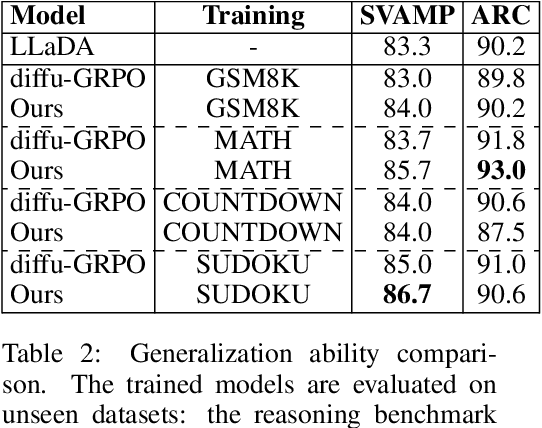
Diffusion language models (dLLMs) offer a promising, non-autoregressive paradigm for text generation, yet training them for complex reasoning remains a key challenge. Current reinforcement learning approaches often rely on sparse, outcome-based rewards, which can reinforce flawed reasoning paths that lead to coincidentally correct answers. We argue that this stems from a fundamental mismatch with the natural structure of reasoning. We first propose a theoretical framework that formalizes complex problem solving as a hierarchical selection process, where an intractable global constraint is decomposed into a series of simpler, localized logical steps. This framework provides a principled foundation for algorithm design, including theoretical insights into the identifiability of this latent reasoning structure. Motivated by this theory, we identify unstructured refinement -- a failure mode where a model's iterative steps do not contribute meaningfully to the solution -- as a core deficiency in existing methods. We then introduce Step-Aware Policy Optimization (SAPO), a novel RL algorithm that aligns the dLLM's denoising process with the latent reasoning hierarchy. By using a process-based reward function that encourages incremental progress, SAPO guides the model to learn structured, coherent reasoning paths. Our empirical results show that this principled approach significantly improves performance on challenging reasoning benchmarks and enhances the interpretability of the generation process.
Position: Mechanistic Interpretability Should Prioritize Feature Consistency in SAEs
May 26, 2025Sparse Autoencoders (SAEs) are a prominent tool in mechanistic interpretability (MI) for decomposing neural network activations into interpretable features. However, the aspiration to identify a canonical set of features is challenged by the observed inconsistency of learned SAE features across different training runs, undermining the reliability and efficiency of MI research. This position paper argues that mechanistic interpretability should prioritize feature consistency in SAEs -- the reliable convergence to equivalent feature sets across independent runs. We propose using the Pairwise Dictionary Mean Correlation Coefficient (PW-MCC) as a practical metric to operationalize consistency and demonstrate that high levels are achievable (0.80 for TopK SAEs on LLM activations) with appropriate architectural choices. Our contributions include detailing the benefits of prioritizing consistency; providing theoretical grounding and synthetic validation using a model organism, which verifies PW-MCC as a reliable proxy for ground-truth recovery; and extending these findings to real-world LLM data, where high feature consistency strongly correlates with the semantic similarity of learned feature explanations. We call for a community-wide shift towards systematically measuring feature consistency to foster robust cumulative progress in MI.
Reflection-Window Decoding: Text Generation with Selective Refinement
Feb 05, 2025



The autoregressive decoding for text generation in large language models (LLMs), while widely used, is inherently suboptimal due to the lack of a built-in mechanism to perform refinement and/or correction of the generated content. In this paper, we consider optimality in terms of the joint probability over the generated response, when jointly considering all tokens at the same time. We theoretically characterize the potential deviation of the autoregressively generated response from its globally optimal counterpart that is of the same length. Our analysis suggests that we need to be cautious when noticeable uncertainty arises during text generation, which may signal the sub-optimality of the generation history. To address the pitfall of autoregressive decoding for text generation, we propose an approach that incorporates a sliding reflection window and a pausing criterion, such that refinement and generation can be carried out interchangeably as the decoding proceeds. Our selective refinement framework strikes a balance between efficiency and optimality, and our extensive experimental results demonstrate the effectiveness of our approach.
Causal Temporal Representation Learning with Nonstationary Sparse Transition
Sep 05, 2024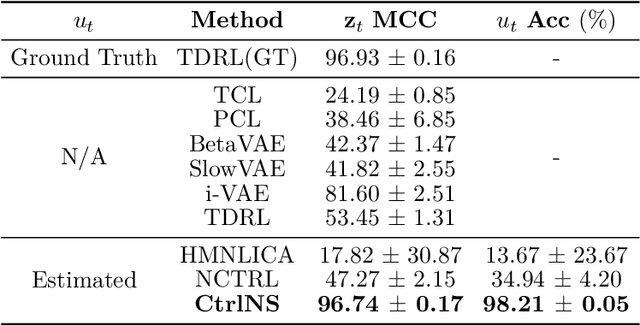
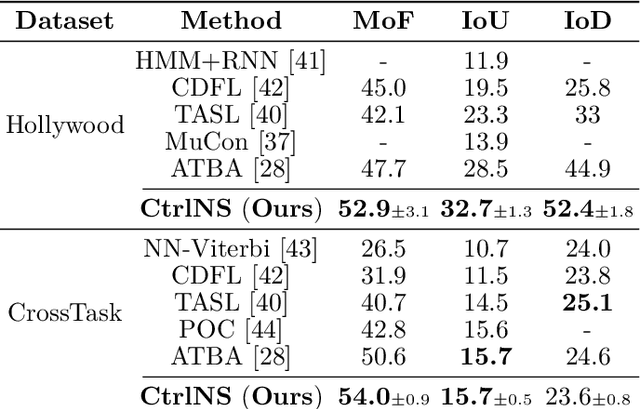
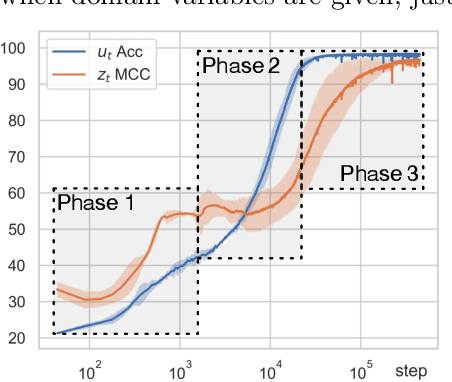

Causal Temporal Representation Learning (Ctrl) methods aim to identify the temporal causal dynamics of complex nonstationary temporal sequences. Despite the success of existing Ctrl methods, they require either directly observing the domain variables or assuming a Markov prior on them. Such requirements limit the application of these methods in real-world scenarios when we do not have such prior knowledge of the domain variables. To address this problem, this work adopts a sparse transition assumption, aligned with intuitive human understanding, and presents identifiability results from a theoretical perspective. In particular, we explore under what conditions on the significance of the variability of the transitions we can build a model to identify the distribution shifts. Based on the theoretical result, we introduce a novel framework, Causal Temporal Representation Learning with Nonstationary Sparse Transition (CtrlNS), designed to leverage the constraints on transition sparsity and conditional independence to reliably identify both distribution shifts and latent factors. Our experimental evaluations on synthetic and real-world datasets demonstrate significant improvements over existing baselines, highlighting the effectiveness of our approach.
On the Identification of Temporally Causal Representation with Instantaneous Dependence
May 24, 2024


Temporally causal representation learning aims to identify the latent causal process from time series observations, but most methods require the assumption that the latent causal processes do not have instantaneous relations. Although some recent methods achieve identifiability in the instantaneous causality case, they require either interventions on the latent variables or grouping of the observations, which are in general difficult to obtain in real-world scenarios. To fill this gap, we propose an \textbf{ID}entification framework for instantane\textbf{O}us \textbf{L}atent dynamics (\textbf{IDOL}) by imposing a sparse influence constraint that the latent causal processes have sparse time-delayed and instantaneous relations. Specifically, we establish identifiability results of the latent causal process based on sufficient variability and the sparse influence constraint by employing contextual information of time series data. Based on these theories, we incorporate a temporally variational inference architecture to estimate the latent variables and a gradient-based sparsity regularization to identify the latent causal process. Experimental results on simulation datasets illustrate that our method can identify the latent causal process. Furthermore, evaluations on multiple human motion forecasting benchmarks with instantaneous dependencies indicate the effectiveness of our method in real-world settings.