 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Variable Causal Discovery under Selection Bias
Dec 12, 2025Addressing selection bias in latent variable causal discovery is important yet underexplored, largely due to a lack of suitable statistical tools: While various tools beyond basic conditional independencies have been developed to handle latent variables, none have been adapted for selection bias. We make an attempt by studying rank constraints, which, as a generalization to conditional independence constraints, exploits the ranks of covariance submatrices in linear Gaussian models. We show that although selection can significantly complicate the joint distribution, interestingly, the ranks in the biased covariance matrices still preserve meaningful information about both causal structures and selection mechanisms. We provide a graph-theoretic characterization of such rank constraints. Using this tool, we demonstrate that the one-factor model, a classical latent variable model, can be identified under selection bias. Simulations and real-world experiments confirm the effectiveness of using our rank constraints.
* Appears at ICML 2025
Score-based Greedy Search for Structure Identification of Partially Observed Linear Causal Models
Oct 05, 2025Identifying the structure of a partially observed causal system is essential to various scientific fields. Recent advances have focused on constraint-based causal discovery to solve this problem, and yet in practice these methods often face challenges related to multiple testing and error propagation. These issues could be mitigated by a score-based method and thus it has raised great attention whether there exists a score-based greedy search method that can handle the partially observed scenario. In this work, we propose the first score-based greedy search method for the identification of structure involving latent variables with identifiability guarantees. Specifically, we propose Generalized N Factor Model and establish the global consistency: the true structure including latent variables can be identified up to the Markov equivalence class by using score. We then design Latent variable Greedy Equivalence Search (LGES), a greedy search algorithm for this class of model with well-defined operators, which search very efficiently over the graph space to find the optimal structure. Our experiments on both synthetic and real-life data validate the effectiveness of our method (code will be publicly available).
Step-Aware Policy Optimization for Reasoning in Diffusion Large Language Models
Oct 02, 2025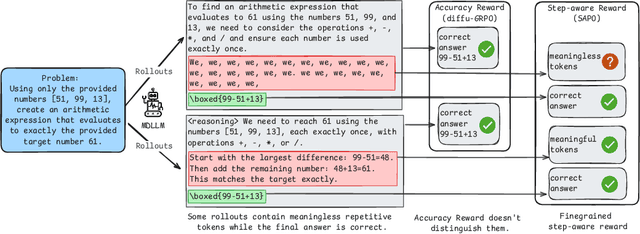
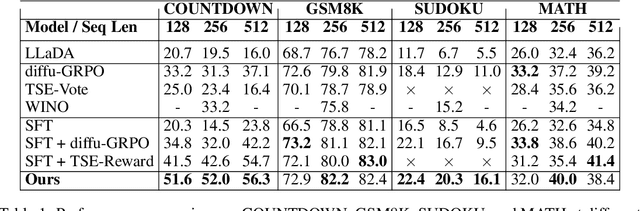
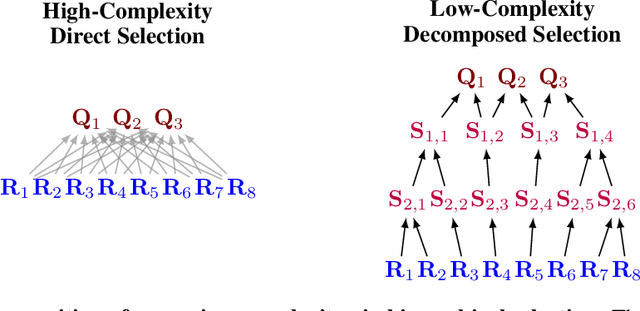
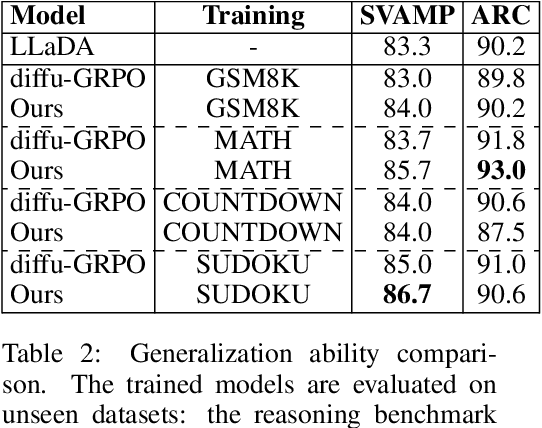
Diffusion language models (dLLMs) offer a promising, non-autoregressive paradigm for text generation, yet training them for complex reasoning remains a key challenge. Current reinforcement learning approaches often rely on sparse, outcome-based rewards, which can reinforce flawed reasoning paths that lead to coincidentally correct answers. We argue that this stems from a fundamental mismatch with the natural structure of reasoning. We first propose a theoretical framework that formalizes complex problem solving as a hierarchical selection process, where an intractable global constraint is decomposed into a series of simpler, localized logical steps. This framework provides a principled foundation for algorithm design, including theoretical insights into the identifiability of this latent reasoning structure. Motivated by this theory, we identify unstructured refinement -- a failure mode where a model's iterative steps do not contribute meaningfully to the solution -- as a core deficiency in existing methods. We then introduce Step-Aware Policy Optimization (SAPO), a novel RL algorithm that aligns the dLLM's denoising process with the latent reasoning hierarchy. By using a process-based reward function that encourages incremental progress, SAPO guides the model to learn structured, coherent reasoning paths. Our empirical results show that this principled approach significantly improves performance on challenging reasoning benchmarks and enhances the interpretability of the generation process.
A Sample Efficient Conditional Independence Test in the Presence of Discretization
Jun 10, 2025In many real-world scenarios, interested variables are often represented as discretized values due to measurement limitations. Applying Conditional Independence (CI) tests directly to such discretized data, however, can lead to incorrect conclusions. To address this, recent advancements have sought to infer the correct CI relationship between the latent variables through binarizing observed data. However, this process inevitably results in a loss of information, which degrades the test's performance. Motivated by this, this paper introduces a sample-efficient CI test that does not rely on the binarization process. We find that the independence relationships of latent continuous variables can be established by addressing an over-identifying restriction problem with Generalized Method of Moments (GMM). Based on this insight, we derive an appropriate test statistic and establish its asymptotic distribution correctly reflecting CI by leveraging nodewise regression. Theoretical findings and Empirical results across various datasets demonstrate that the superiority and effectiveness of our proposed test. Our code implementation is provided in https://github.com/boyangaaaaa/DCT
Causal Discovery and Counterfactual Reasoning to Optimize Persuasive Dialogue Policies
Mar 19, 2025Tailoring persuasive conversations to users leads to more effective persuasion. However, existing dialogue systems often struggle to adapt to dynamically evolving user states. This paper presents a novel method that leverages causal discovery and counterfactual reasoning for optimizing system persuasion capability and outcomes. We employ the Greedy Relaxation of the Sparsest Permutation (GRaSP) algorithm to identify causal relationships between user and system utterance strategies, treating user strategies as states and system strategies as actions. GRaSP identifies user strategies as causal factors influencing system responses, which inform Bidirectional Conditional Generative Adversarial Networks (BiCoGAN) in generating counterfactual utterances for the system. Subsequently, we use the Dueling Double Deep Q-Network (D3QN) model to utilize counterfactual data to determine the best policy for selecting system utterances. Our experiments with the PersuasionForGood dataset show measurable improvements in persuasion outcomes using our approach over baseline methods. The observed increase in cumulative rewards and Q-values highlights the effectiveness of causal discovery in enhancing counterfactual reasoning and optimizing reinforcement learning policies for online dialogue systems.
Type Information-Assisted Self-Supervised Knowledge Graph Denoising
Mar 13, 2025Knowledge graphs serve as critical resources supporting intelligent systems, but they can be noisy due to imperfect automatic generation processes. Existing approaches to noise detection often rely on external facts, logical rule constraints, or structural embeddings. These methods are often challenged by imperfect entity alignment, flexible knowledge graph construction, and overfitting on structures. In this paper, we propose to exploit the consistency between entity and relation type information for noise detection, resulting a novel self-supervised knowledge graph denoising method that avoids those problems. We formalize type inconsistency noise as triples that deviate from the majority with respect to type-dependent reasoning along the topological structure. Specifically, we first extract a compact representation of a given knowledge graph via an encoder that models the type dependencies of triples. Then, the decoder reconstructs the original input knowledge graph based on the compact representation. It is worth noting that, our proposal has the potential to address the problems of knowledge graph compression and completion, although this is not our focus. For the specific task of noise detection, the discrepancy between the reconstruction results and the input knowledge graph provides an opportunity for denoising, which is facilitated by the type consistency embedded in our method. Experimental validation demonstrates the effectiveness of our approach in detecting potential noise in real-world data.
When Selection Meets Intervention: Additional Complexities in Causal Discovery
Mar 10, 2025We address the common yet often-overlooked selection bias in interventional studies, where subjects are selectively enrolled into experiments. For instance, participants in a drug trial are usually patients of the relevant disease; A/B tests on mobile applications target existing users only, and gene perturbation studies typically focus on specific cell types, such as cancer cells. Ignoring this bias leads to incorrect causal discovery results. Even when recognized, the existing paradigm for interventional causal discovery still fails to address it. This is because subtle differences in when and where interventions happen can lead to significantly different statistical patterns. We capture this dynamic by introducing a graphical model that explicitly accounts for both the observed world (where interventions are applied) and the counterfactual world (where selection occurs while interventions have not been applied). We characterize the Markov property of the model, and propose a provably sound algorithm to identify causal relations as well as selection mechanisms up to the equivalence class, from data with soft interventions and unknown targets. Through synthetic and real-world experiments, we demonstrate that our algorithm effectively identifies true causal relations despite the presence of selection bias.
* Appears at ICLR 2025 (oral)
Permutation-Based Rank Test in the Presence of Discretization and Application in Causal Discovery with Mixed Data
Jan 31, 2025



Recent advances have shown that statistical tests for the rank of cross-covariance matrices play an important role in causal discovery. These rank tests include partial correlation tests as special cases and provide further graphical information about latent variables. Existing rank tests typically assume that all the continuous variables can be perfectly measured, and yet, in practice many variables can only be measured after discretization. For example, in psychometric studies, the continuous level of certain personality dimensions of a person can only be measured after being discretized into order-preserving options such as disagree, neutral, and agree. Motivated by this, we propose Mixed data Permutation-based Rank Test (MPRT), which properly controls the statistical errors even when some or all variables are discretized. Theoretically, we establish the exchangeability and estimate the asymptotic null distribution by permutations; as a consequence, MPRT can effectively control the Type I error in the presence of discretization while previous methods cannot. Empirically, our method is validated by extensive experiments on synthetic data and real-world data to demonstrate its effectiveness as well as applicability in causal discovery.
Causal Temporal Representation Learning with Nonstationary Sparse Transition
Sep 05, 2024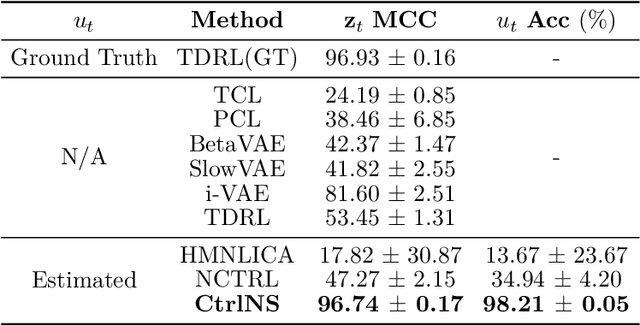
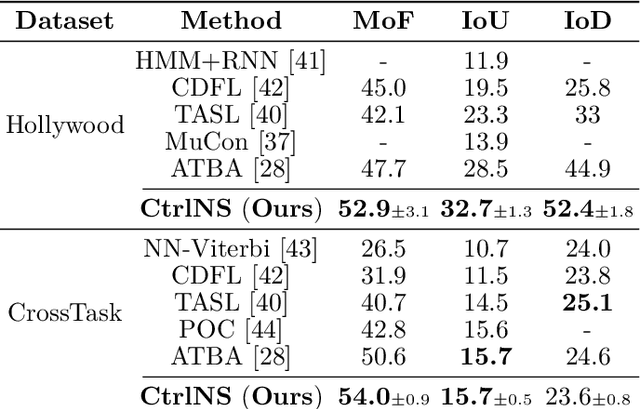
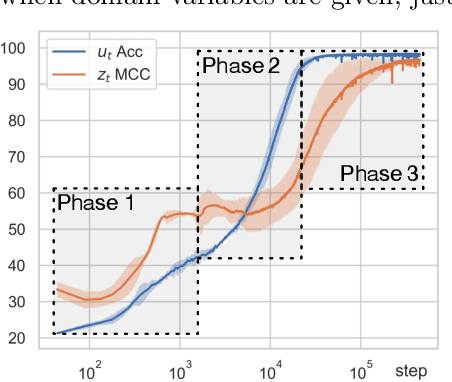

Causal Temporal Representation Learning (Ctrl) methods aim to identify the temporal causal dynamics of complex nonstationary temporal sequences. Despite the success of existing Ctrl methods, they require either directly observing the domain variables or assuming a Markov prior on them. Such requirements limit the application of these methods in real-world scenarios when we do not have such prior knowledge of the domain variables. To address this problem, this work adopts a sparse transition assumption, aligned with intuitive human understanding, and presents identifiability results from a theoretical perspective. In particular, we explore under what conditions on the significance of the variability of the transitions we can build a model to identify the distribution shifts. Based on the theoretical result, we introduce a novel framework, Causal Temporal Representation Learning with Nonstationary Sparse Transition (CtrlNS), designed to leverage the constraints on transition sparsity and conditional independence to reliably identify both distribution shifts and latent factors. Our experimental evaluations on synthetic and real-world datasets demonstrate significant improvements over existing baselines, highlighting the effectiveness of our approach.
On the Identifiability of Sparse ICA without Assuming Non-Gaussianity
Aug 19, 2024Independent component analysis (ICA) is a fundamental statistical tool used to reveal hidden generative processes from observed data. However, traditional ICA approaches struggle with the rotational invariance inherent in Gaussian distributions, often necessitating the assumption of non-Gaussianity in the underlying sources. This may limit their applicability in broader contexts. To accommodate Gaussian sources, we develop an identifiability theory that relies on second-order statistics without imposing further preconditions on the distribution of sources, by introducing novel assumptions on the connective structure from sources to observed variables. Different from recent work that focuses on potentially restrictive connective structures, our proposed assumption of structural variability is both considerably less restrictive and provably necessary. Furthermore, we propose two estimation methods based on second-order statistics and sparsity constraint. Experimental results are provided to validate our identifiability theory and estimation methods.