 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-optimized Angular Margin Contrastive Framework for Video-Language Representation Learning
Paper and Code
Jul 04, 2024

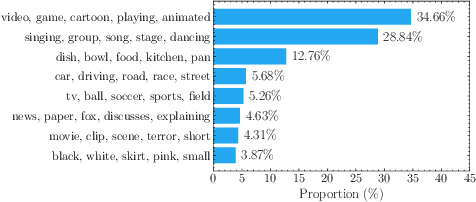
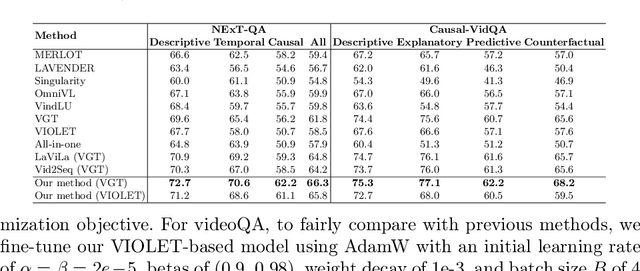
Data quality stands at the forefront of deciding the effectiveness of video-language representation learning. However, video-text pairs in previous data typically do not align perfectly with each other, which might lead to video-language representations that do not accurately reflect cross-modal semantics. Moreover, previous data also possess an uneven distribution of concepts, thereby hampering the downstream performance across unpopular subjects. To address these problems, we propose a contrastive objective with a subtractive angular margin to regularize cross-modal representations in their effort to reach perfect similarity. Furthermore, to adapt to the non-uniform concept distribution, we propose a multi-layer perceptron (MLP)-parameterized weighting function that maps loss values to sample weights which enable dynamic adjustment of the model's focus throughout the training. With the training guided by a small amount of unbiased meta-data and augmented by video-text data generated by large vision-language model, we improve video-language representations and achieve superior performances on commonly used video question answering and text-video retrieval datasets.