 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen In-Distribution Gains Fail: Evaluating Weak-to-Strong Reward Models under Preference Shift
May 26, 2026Weak-to-strong (W2S) generalization is a promising framework for scalable oversight, yet existing evaluations often test students under matched train-test distributions. Therefore, we study W2S preference learning under zero-shot distribution shift and find that strong students trained on weak preference labels can appear successful in-distribution while failing to transfer across preference datasets. We provide evidence for a representational failure mode in which weak-supervised fine-tuning can pull the strong model toward source-domain features instead of maintaining broadly transferable preference representations. To mitigate this, we propose Representation Anchoring (Anchor), a simple yet effective regularizer that constrains excessive drift from the pretrained strong model's representation space during fine-tuning, while still allowing task-relevant adaptation. Across preference domains, datasets, and model families, Anchor consistently improves out-of-distribution transfer while maintaining competitive in-distribution performance. Together, our evaluation protocol, transfer-aware metrics, and method expose hidden brittleness in current W2S reward modeling and provide a practical path toward more robust preference transfer.
WARD: Adversarially Robust Defense of Web Agents Against Prompt Injections
May 14, 2026Web agents can autonomously complete online tasks by interacting with websites, but their exposure to open web environments makes them vulnerable to prompt injection attacks embedded in HTML content or visual interfaces. Existing guard models still suffer from limited generalization to unseen domains and attack patterns, high false positive rates on benign content, reduced deployment efficiency due to added latency at each step, and vulnerability to adversarial attacks that evolve over time or directly target the guard itself. To address these limitations, we propose WARD (Web Agent Robust Defense against Prompt Injection), a practical guard model for secure and efficient web agents. WARD is built on WARD-Base, a large-scale dataset with around 177K samples collected from 719 high-traffic URLs and platforms, and WARD-PIG, a dedicated dataset designed for prompt injection attacks targeting the guard model. We further introduce A3T, an adaptive adversarial attack training framework that iteratively strengthens WARD through a memory-based attacker and guard co-evolution process. Extensive experiments show that WARD achieves nearly perfect recall on out-of-distribution benchmarks, maintains low false positive rates to preserve agent utility, remains robust against guard-targeted and adaptive attacks under substantial distribution shifts, and runs efficiently in parallel with the agent without introducing additional latency.
Enhancing Multimodal Entity Linking with Jaccard Distance-based Conditional Contrastive Learning and Contextual Visual Augmentation
Jan 24, 2025Previous research on multimodal entity linking (MEL) has primarily employed contrastive learning as the primary objective. However, using the rest of the batch as negative samples without careful consideration, these studies risk leveraging easy features and potentially overlook essential details that make entities unique. In this work, we propose JD-CCL (Jaccard Distance-based Conditional Contrastive Learning), a novel approach designed to enhance the ability to match multimodal entity linking models. JD-CCL leverages meta-information to select negative samples with similar attributes, making the linking task more challenging and robust. Additionally, to address the limitations caused by the variations within the visual modality among mentions and entities, we introduce a novel method, CVaCPT (Contextual Visual-aid Controllable Patch Transform). It enhances visual representations by incorporating multi-view synthetic images and contextual textual representations to scale and shift patch representations. Experimental results on benchmark MEL datasets demonstrate the strong effectiveness of our approach.
Meta-optimized Angular Margin Contrastive Framework for Video-Language Representation Learning
Jul 04, 2024

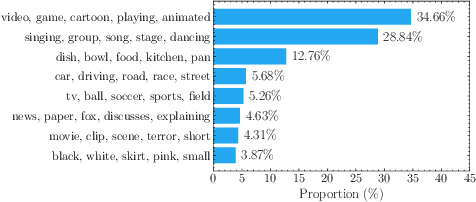
Data quality stands at the forefront of deciding the effectiveness of video-language representation learning. However, video-text pairs in previous data typically do not align perfectly with each other, which might lead to video-language representations that do not accurately reflect cross-modal semantics. Moreover, previous data also possess an uneven distribution of concepts, thereby hampering the downstream performance across unpopular subjects. To address these problems, we propose a contrastive objective with a subtractive angular margin to regularize cross-modal representations in their effort to reach perfect similarity. Furthermore, to adapt to the non-uniform concept distribution, we propose a multi-layer perceptron (MLP)-parameterized weighting function that maps loss values to sample weights which enable dynamic adjustment of the model's focus throughout the training. With the training guided by a small amount of unbiased meta-data and augmented by video-text data generated by large vision-language model, we improve video-language representations and achieve superior performances on commonly used video question answering and text-video retrieval datasets.
READ-PVLA: Recurrent Adapter with Partial Video-Language Alignment for Parameter-Efficient Transfer Learning in Low-Resource Video-Language Modeling
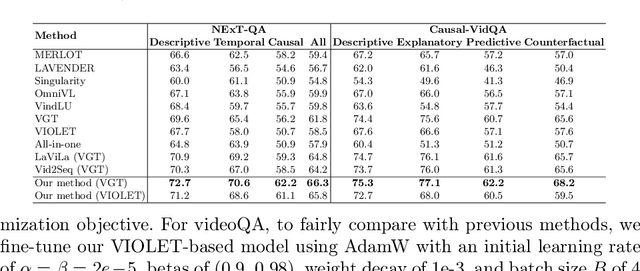
Dec 12, 2023Fully fine-tuning pretrained large-scale transformer models has become a popular paradigm for video-language modeling tasks, such as temporal language grounding and video-language summarization. With a growing number of tasks and limited training data, such full fine-tuning approach leads to costly model storage and unstable training. To overcome these shortcomings, we introduce lightweight adapters to the pre-trained model and only update them at fine-tuning time. However, existing adapters fail to capture intrinsic temporal relations among video frames or textual words. Moreover, they neglect the preservation of critical task-related information that flows from the raw video-language input into the adapter's low-dimensional space. To address these issues, we first propose a novel REcurrent ADapter (READ) that employs recurrent computation to enable temporal modeling capability. Second, we propose Partial Video-Language Alignment (PVLA) objective via the use of partial optimal transport to maintain task-related information flowing into our READ modules. We validate our READ-PVLA framework through extensive experiments where READ-PVLA significantly outperforms all existing fine-tuning strategies on multiple low-resource temporal language grounding and video-language summarization benchmarks.