 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinkTank-ME: A Multi-Expert Framework for Middle East Event Forecasting
Jan 22, 2026Event forecasting is inherently influenced by multifaceted considerations, including international relations, regional historical dynamics, and cultural contexts. However, existing LLM-based approaches employ single-model architectures that generate predictions along a singular explicit trajectory, constraining their ability to capture diverse geopolitical nuances across complex regional contexts. To address this limitation, we introduce ThinkTank-ME, a novel Think Tank framework for Middle East event forecasting that emulates collaborative expert analysis in real-world strategic decision-making. To facilitate expert specialization and rigorous evaluation, we construct POLECAT-FOR-ME, a Middle East-focused event forecasting benchmark. Experimental results demonstrate the superiority of multi-expert collaboration in handling complex temporal geopolitical forecasting tasks. The code is available at https://github.com/LuminosityX/ThinkTank-ME.
RISER: Orchestrating Latent Reasoning Skills for Adaptive Activation Steering
Jan 14, 2026Recent work on domain-specific reasoning with large language models (LLMs) often relies on training-intensive approaches that require parameter updates. While activation steering has emerged as a parameter efficient alternative, existing methods apply static, manual interventions that fail to adapt to the dynamic nature of complex reasoning. To address this limitation, we propose RISER (Router-based Intervention for Steerable Enhancement of Reasoning), a plug-and-play intervention framework that adaptively steers LLM reasoning in activation space. RISER constructs a library of reusable reasoning vectors and employs a lightweight Router to dynamically compose them for each input. The Router is optimized via reinforcement learning under task-level rewards, activating latent cognitive primitives in an emergent and compositional manner. Across seven diverse benchmarks, RISER yields 3.4-6.5% average zero-shot accuracy improvements over the base model while surpassing CoT-style reasoning with 2-3x higher token efficiency and robust accuracy gains. Further analysis shows that RISER autonomously combines multiple vectors into interpretable, precise control strategies, pointing toward more controllable and efficient LLM reasoning.
More Than One Teacher: Adaptive Multi-Guidance Policy Optimization for Diverse Exploration
Oct 02, 2025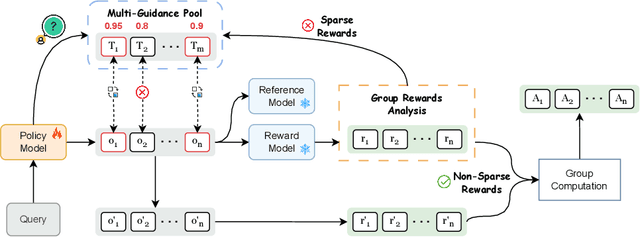
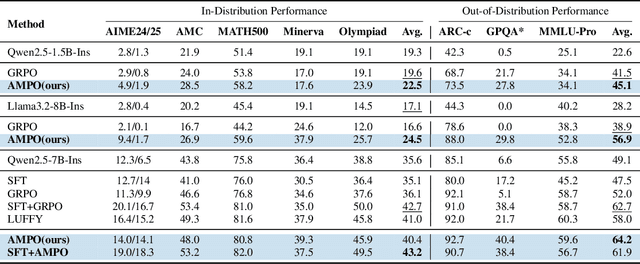

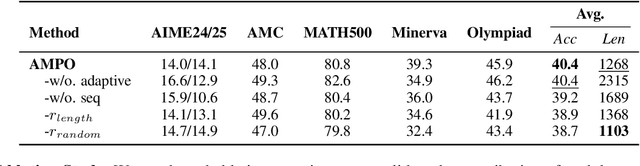
Reinforcement Learning with Verifiable Rewards (RLVR) is a promising paradigm for enhancing the reasoning ability in Large Language Models (LLMs). However, prevailing methods primarily rely on self-exploration or a single off-policy teacher to elicit long chain-of-thought (LongCoT) reasoning, which may introduce intrinsic model biases and restrict exploration, ultimately limiting reasoning diversity and performance. Drawing inspiration from multi-teacher strategies in knowledge distillation, we introduce Adaptive Multi-Guidance Policy Optimization (AMPO), a novel framework that adaptively leverages guidance from multiple proficient teacher models, but only when the on-policy model fails to generate correct solutions. This "guidance-on-demand" approach expands exploration while preserving the value of self-discovery. Moreover, AMPO incorporates a comprehension-based selection mechanism, prompting the student to learn from the reasoning paths that it is most likely to comprehend, thus balancing broad exploration with effective exploitation. Extensive experiments show AMPO substantially outperforms a strong baseline (GRPO), with a 4.3% improvement on mathematical reasoning tasks and 12.2% on out-of-distribution tasks, while significantly boosting Pass@k performance and enabling more diverse exploration. Notably, using four peer-sized teachers, our method achieves comparable results to approaches that leverage a single, more powerful teacher (e.g., DeepSeek-R1) with more data. These results demonstrate a more efficient and scalable path to superior reasoning and generalizability. Our code is available at https://github.com/SII-Enigma/AMPO.
Explore Briefly, Then Decide: Mitigating LLM Overthinking via Cumulative Entropy Regulation
Oct 02, 2025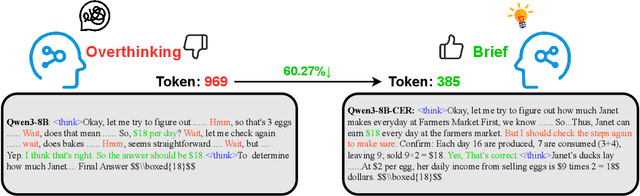
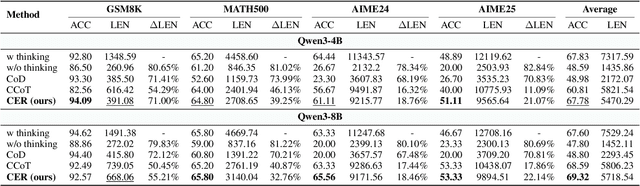
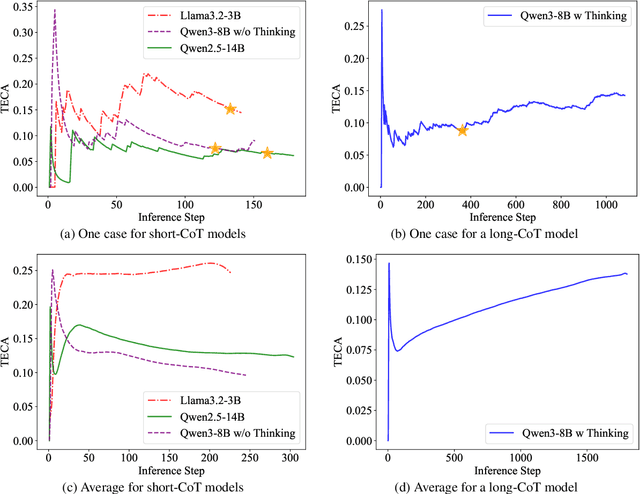
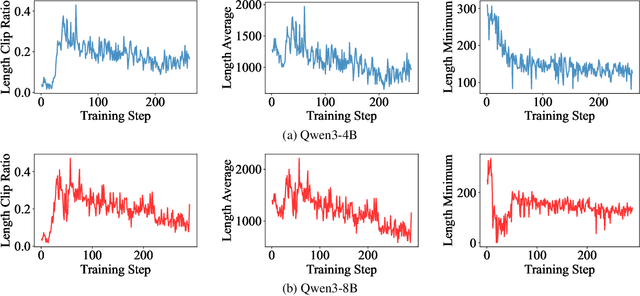
Large Language Models (LLMs) have demonstrated remarkable reasoning abilities on complex problems using long Chain-of-Thought (CoT) reasoning. However, they often suffer from overthinking, meaning generating unnecessarily lengthy reasoning steps for simpler problems. This issue may degrade the efficiency of the models and make them difficult to adapt the reasoning depth to the complexity of problems. To address this, we introduce a novel metric Token Entropy Cumulative Average (TECA), which measures the extent of exploration throughout the reasoning process. We further propose a novel reasoning paradigm -- Explore Briefly, Then Decide -- with an associated Cumulative Entropy Regulation (CER) mechanism. This paradigm leverages TECA to help the model dynamically determine the optimal point to conclude its thought process and provide a final answer, thus achieving efficient reasoning. Experimental results across diverse mathematical benchmarks show that our approach substantially mitigates overthinking without sacrificing problem-solving ability. With our thinking paradigm, the average response length decreases by up to 71% on simpler datasets, demonstrating the effectiveness of our method in creating a more efficient and adaptive reasoning process.
GeoPurify: A Data-Efficient Geometric Distillation Framework for Open-Vocabulary 3D Segmentation
Oct 02, 2025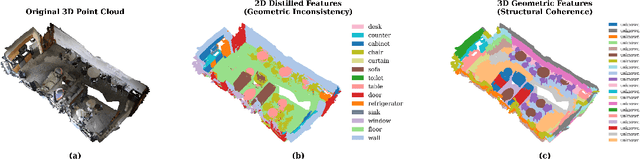
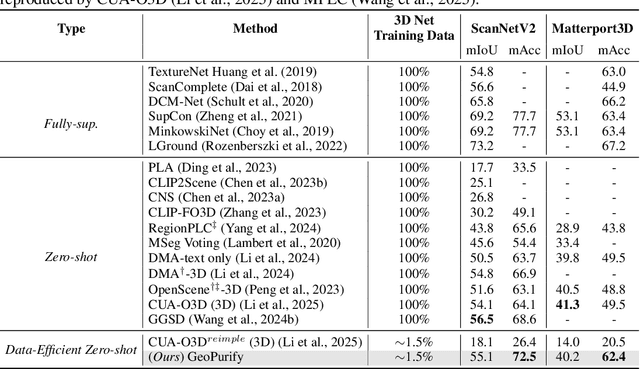
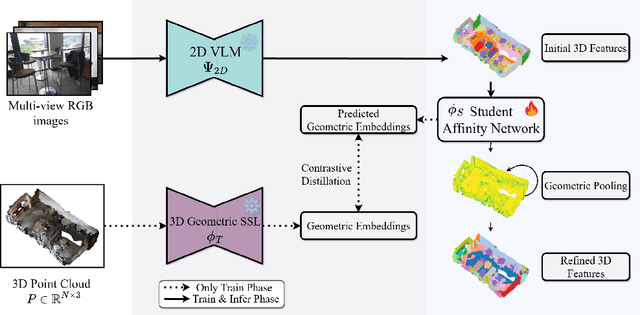
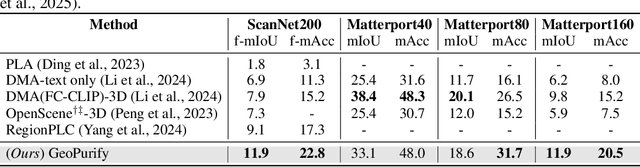
Recent attempts to transfer features from 2D Vision-Language Models (VLMs) to 3D semantic segmentation expose a persistent trade-off. Directly projecting 2D features into 3D yields noisy and fragmented predictions, whereas enforcing geometric coherence necessitates costly training pipelines and large-scale annotated 3D data. We argue that this limitation stems from the dominant segmentation-and-matching paradigm, which fails to reconcile 2D semantics with 3D geometric structure. The geometric cues are not eliminated during the 2D-to-3D transfer but remain latent within the noisy and view-aggregated features. To exploit this property, we propose GeoPurify that applies a small Student Affinity Network to purify 2D VLM-generated 3D point features using geometric priors distilled from a 3D self-supervised teacher model. During inference, we devise a Geometry-Guided Pooling module to further denoise the point cloud and ensure the semantic and structural consistency. Benefiting from latent geometric information and the learned affinity network, GeoPurify effectively mitigates the trade-off and achieves superior data efficiency. Extensive experiments on major 3D benchmarks demonstrate that GeoPurify achieves or surpasses state-of-the-art performance while utilizing only about 1.5% of the training data. Our codes and checkpoints are available at [https://github.com/tj12323/GeoPurify](https://github.com/tj12323/GeoPurify).
Multimodal Mathematical Reasoning with Diverse Solving Perspective
Jul 03, 2025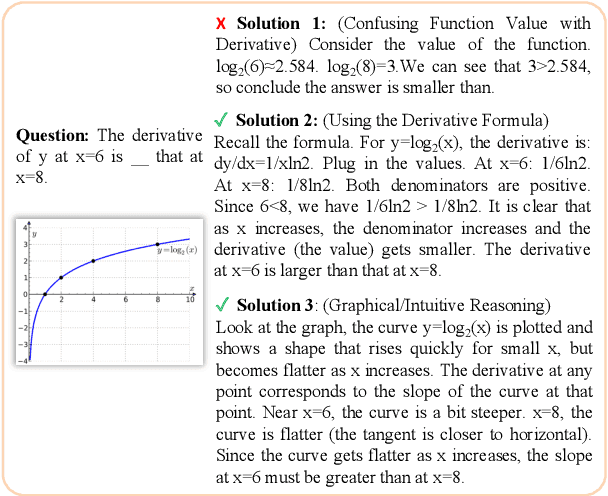
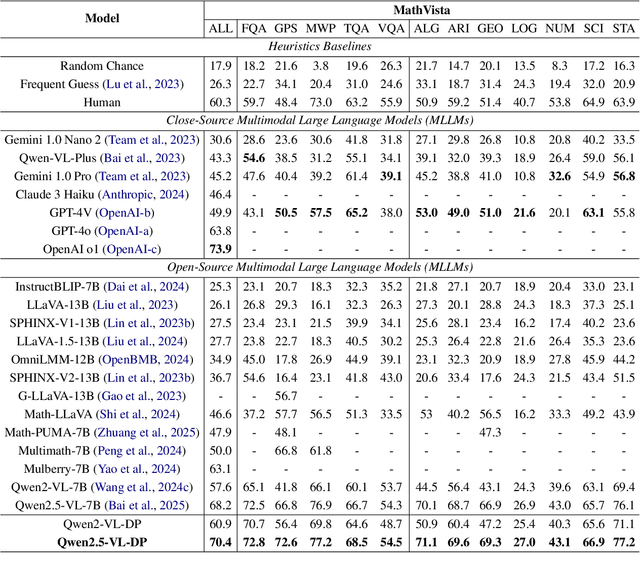
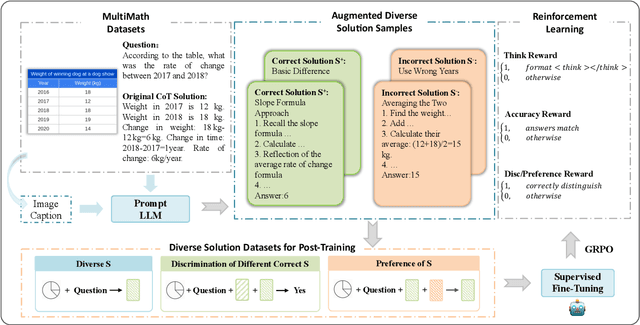
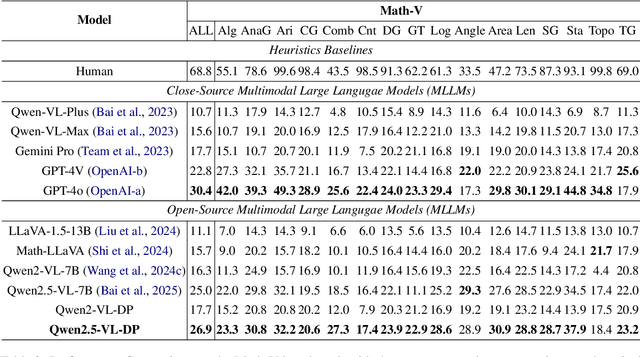
Recent progress in large-scale reinforcement learning (RL) has notably enhanced the reasoning capabilities of large language models (LLMs), especially in mathematical domains. However, current multimodal LLMs (MLLMs) for mathematical reasoning often rely on one-to-one image-text pairs and single-solution supervision, overlooking the diversity of valid reasoning perspectives and internal reflections. In this work, we introduce MathV-DP, a novel dataset that captures multiple diverse solution trajectories for each image-question pair, fostering richer reasoning supervision. We further propose Qwen-VL-DP, a model built upon Qwen-VL, fine-tuned with supervised learning and enhanced via group relative policy optimization (GRPO), a rule-based RL approach that integrates correctness discrimination and diversity-aware reward functions. Our method emphasizes learning from varied reasoning perspectives and distinguishing between correct yet distinct solutions. Extensive experiments on the MathVista's minitest and Math-V benchmarks demonstrate that Qwen-VL-DP significantly outperforms prior base MLLMs in both accuracy and generative diversity, highlighting the importance of incorporating diverse perspectives and reflective reasoning in multimodal mathematical reasoning.
SemCORE: A Semantic-Enhanced Generative Cross-Modal Retrieval Framework with MLLMs
Apr 17, 2025Cross-modal retrieval (CMR) is a fundamental task in multimedia research, focused on retrieving semantically relevant targets across different modalities. While traditional CMR methods match text and image via embedding-based similarity calculations, recent advancements in pre-trained generative models have established generative retrieval as a promising alternative. This paradigm assigns each target a unique identifier and leverages a generative model to directly predict identifiers corresponding to input queries without explicit indexing. Despite its great potential, current generative CMR approaches still face semantic information insufficiency in both identifier construction and generation processes. To address these limitations, we propose a novel unified Semantic-enhanced generative Cross-mOdal REtrieval framework (SemCORE), designed to unleash the semantic understanding capabilities in generative cross-modal retrieval task. Specifically, we first construct a Structured natural language IDentifier (SID) that effectively aligns target identifiers with generative models optimized for natural language comprehension and generation. Furthermore, we introduce a Generative Semantic Verification (GSV) strategy enabling fine-grained target discrimination. Additionally, to the best of our knowledge, SemCORE is the first framework to simultaneously consider both text-to-image and image-to-text retrieval tasks within generative cross-modal retrieval. Extensive experiments demonstrate that our framework outperforms state-of-the-art generative cross-modal retrieval methods. Notably, SemCORE achieves substantial improvements across benchmark datasets, with an average increase of 8.65 points in Recall@1 for text-to-image retrieval.
Multi-Scale Contrastive Learning for Video Temporal Grounding
Dec 10, 2024



Temporal grounding, which localizes video moments related to a natural language query, is a core problem of vision-language learning and video understanding. To encode video moments of varying lengths, recent methods employ a multi-level structure known as a feature pyramid. In this structure, lower levels concentrate on short-range video moments, while higher levels address long-range moments. Because higher levels experience downsampling to accommodate increasing moment length, their capacity to capture information is reduced and consequently leads to degraded information in moment representations. To resolve this problem, we propose a contrastive learning framework to capture salient semantics among video moments. Our key methodology is to leverage samples from the feature space emanating from multiple stages of the video encoder itself requiring neither data augmentation nor online memory banks to obtain positive and negative samples. To enable such an extension, we introduce a sampling process to draw multiple video moments corresponding to a common query. Subsequently, by utilizing these moments' representations across video encoder layers, we instantiate a novel form of multi-scale and cross-scale contrastive learning that links local short-range video moments with global long-range video moments. Extensive experiments demonstrate the effectiveness of our framework for not only long-form but also short-form video grounding.
Motion-aware Contrastive Learning for Temporal Panoptic Scene Graph Generation
Dec 10, 2024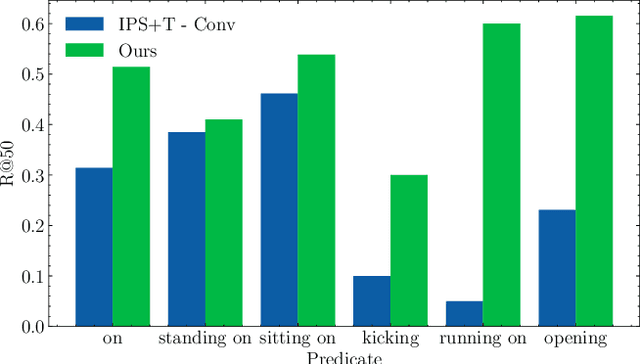
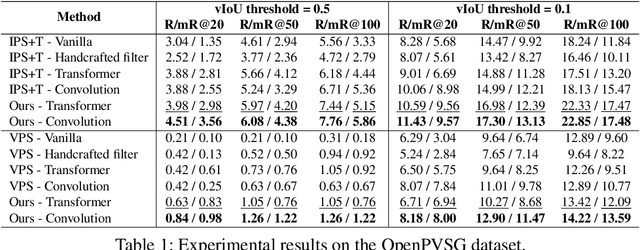
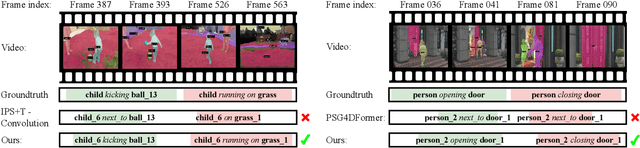

To equip artificial intelligence with a comprehensive understanding towards a temporal world, video and 4D panoptic scene graph generation abstracts visual data into nodes to represent entities and edges to capture temporal relations. Existing methods encode entity masks tracked across temporal dimensions (mask tubes), then predict their relations with temporal pooling operation, which does not fully utilize the motion indicative of the entities' relation. To overcome this limitation, we introduce a contrastive representation learning framework that focuses on motion pattern for temporal scene graph generation. Firstly, our framework encourages the model to learn close representations for mask tubes of similar subject-relation-object triplets. Secondly, we seek to push apart mask tubes from their temporally shuffled versions. Moreover, we also learn distant representations for mask tubes belonging to the same video but different triplets. Extensive experiments show that our motion-aware contrastive framework significantly improves state-of-the-art methods on both video and 4D datasets.
Dynamic Multimodal Evaluation with Flexible Complexity by Vision-Language Bootstrapping
Oct 11, 2024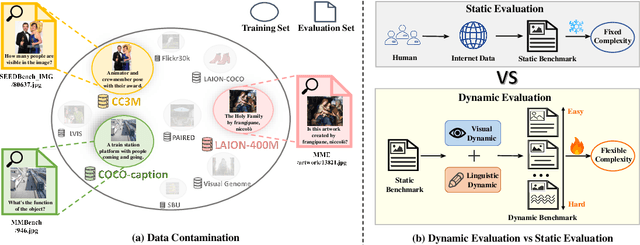

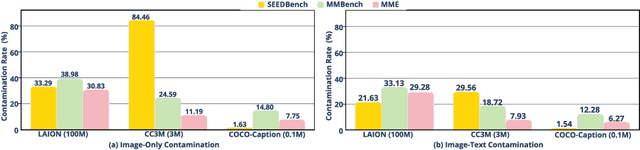

Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities across multimodal tasks such as visual perception and reasoning, leading to good performance on various multimodal evaluation benchmarks. However, these benchmarks keep a static nature and overlap with the pre-training data, resulting in fixed complexity constraints and data contamination issues. This raises the concern regarding the validity of the evaluation. To address these two challenges, we introduce a dynamic multimodal evaluation protocol called Vision-Language Bootstrapping (VLB). VLB provides a robust and comprehensive assessment for LVLMs with reduced data contamination and flexible complexity. To this end, VLB dynamically generates new visual question-answering samples through a multimodal bootstrapping module that modifies both images and language, while ensuring that newly generated samples remain consistent with the original ones by a judge module. By composing various bootstrapping strategies, VLB offers dynamic variants of existing benchmarks with diverse complexities, enabling the evaluation to co-evolve with the ever-evolving capabilities of LVLMs. Extensive experimental results across multiple benchmarks, including SEEDBench, MMBench, and MME, show that VLB significantly reduces data contamination and exposes performance limitations of LVLMs.