 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-aware Contrastive Learning for Temporal Panoptic Scene Graph Generation
Dec 10, 2024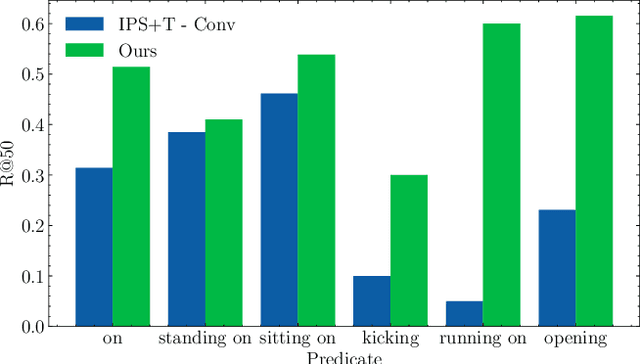
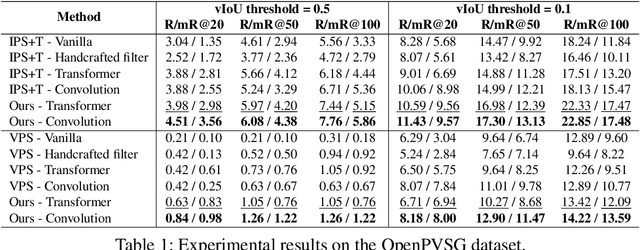
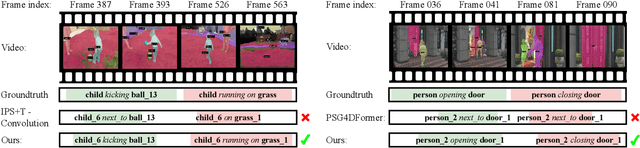

To equip artificial intelligence with a comprehensive understanding towards a temporal world, video and 4D panoptic scene graph generation abstracts visual data into nodes to represent entities and edges to capture temporal relations. Existing methods encode entity masks tracked across temporal dimensions (mask tubes), then predict their relations with temporal pooling operation, which does not fully utilize the motion indicative of the entities' relation. To overcome this limitation, we introduce a contrastive representation learning framework that focuses on motion pattern for temporal scene graph generation. Firstly, our framework encourages the model to learn close representations for mask tubes of similar subject-relation-object triplets. Secondly, we seek to push apart mask tubes from their temporally shuffled versions. Moreover, we also learn distant representations for mask tubes belonging to the same video but different triplets. Extensive experiments show that our motion-aware contrastive framework significantly improves state-of-the-art methods on both video and 4D datasets.
Multi-Scale Contrastive Learning for Video Temporal Grounding
Dec 10, 2024



Temporal grounding, which localizes video moments related to a natural language query, is a core problem of vision-language learning and video understanding. To encode video moments of varying lengths, recent methods employ a multi-level structure known as a feature pyramid. In this structure, lower levels concentrate on short-range video moments, while higher levels address long-range moments. Because higher levels experience downsampling to accommodate increasing moment length, their capacity to capture information is reduced and consequently leads to degraded information in moment representations. To resolve this problem, we propose a contrastive learning framework to capture salient semantics among video moments. Our key methodology is to leverage samples from the feature space emanating from multiple stages of the video encoder itself requiring neither data augmentation nor online memory banks to obtain positive and negative samples. To enable such an extension, we introduce a sampling process to draw multiple video moments corresponding to a common query. Subsequently, by utilizing these moments' representations across video encoder layers, we instantiate a novel form of multi-scale and cross-scale contrastive learning that links local short-range video moments with global long-range video moments. Extensive experiments demonstrate the effectiveness of our framework for not only long-form but also short-form video grounding.
Encoding and Controlling Global Semantics for Long-form Video Question Answering
May 30, 2024



Seeking answers effectively for long videos is essential to build video question answering (videoQA) systems. Previous methods adaptively select frames and regions from long videos to save computations. However, this fails to reason over the whole sequence of video, leading to sub-optimal performance. To address this problem, we introduce a state space layer (SSL) into multi-modal Transformer to efficiently integrate global semantics of the video, which mitigates the video information loss caused by frame and region selection modules. Our SSL includes a gating unit to enable controllability over the flow of global semantics into visual representations. To further enhance the controllability, we introduce a cross-modal compositional congruence (C^3) objective to encourage global semantics aligned with the question. To rigorously evaluate long-form videoQA capacity, we construct two new benchmarks Ego-QA and MAD-QA featuring videos of considerably long length, i.e. 17.5 minutes and 1.9 hours, respectively. Extensive experiments demonstrate the superiority of our framework on these new as well as existing datasets.
Topic Modeling as Multi-Objective Contrastive Optimization
Feb 12, 2024



Recent representation learning approaches enhance neural topic models by optimizing the weighted linear combination of the evidence lower bound (ELBO) of the log-likelihood and the contrastive learning objective that contrasts pairs of input documents. However, document-level contrastive learning might capture low-level mutual information, such as word ratio, which disturbs topic modeling. Moreover, there is a potential conflict between the ELBO loss that memorizes input details for better reconstruction quality, and the contrastive loss which attempts to learn topic representations that generalize among input documents. To address these issues, we first introduce a novel contrastive learning method oriented towards sets of topic vectors to capture useful semantics that are shared among a set of input documents. Secondly, we explicitly cast contrastive topic modeling as a gradient-based multi-objective optimization problem, with the goal of achieving a Pareto stationary solution that balances the trade-off between the ELBO and the contrastive objective. Extensive experiments demonstrate that our framework consistently produces higher-performing neural topic models in terms of topic coherence, topic diversity, and downstream performance.