 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMPrompter: reconceptualized segment anything model with multiprompt network for camouflaged object detection
Nov 28, 2024We rethink the segment anything model (SAM) and propose a novel multiprompt network called COMPrompter for camouflaged object detection (COD). SAM has zero-shot generalization ability beyond other models and can provide an ideal framework for COD. Our network aims to enhance the single prompt strategy in SAM to a multiprompt strategy. To achieve this, we propose an edge gradient extraction module, which generates a mask containing gradient information regarding the boundaries of camouflaged objects. This gradient mask is then used as a novel boundary prompt, enhancing the segmentation process. Thereafter, we design a box-boundary mutual guidance module, which fosters more precise and comprehensive feature extraction via mutual guidance between a boundary prompt and a box prompt. This collaboration enhances the model's ability to accurately detect camouflaged objects. Moreover, we employ the discrete wavelet transform to extract high-frequency features from image embeddings. The high-frequency features serve as a supplementary component to the multiprompt system. Finally, our COMPrompter guides the network to achieve enhanced segmentation results, thereby advancing the development of SAM in terms of COD. Experimental results across COD benchmarks demonstrate that COMPrompter achieves a cutting-edge performance, surpassing the current leading model by an average positive metric of 2.2% in COD10K. In the specific application of COD, the experimental results in polyp segmentation show that our model is superior to top-tier methods as well. The code will be made available at https://github.com/guobaoxiao/COMPrompter.
Exploring Deeper! Segment Anything Model with Depth Perception for Camouflaged Object Detection
Jul 17, 2024


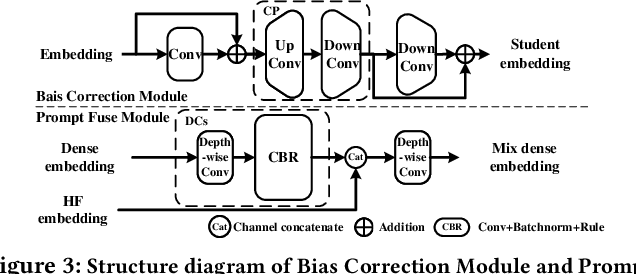
This paper introduces a new Segment Anything Model with Depth Perception (DSAM) for Camouflaged Object Detection (COD). DSAM exploits the zero-shot capability of SAM to realize precise segmentation in the RGB-D domain. It consists of the Prompt-Deeper Module and the Finer Module. The Prompt-Deeper Module utilizes knowledge distillation and the Bias Correction Module to achieve the interaction between RGB features and depth features, especially using depth features to correct erroneous parts in RGB features. Then, the interacted features are combined with the box prompt in SAM to create a prompt with depth perception. The Finer Module explores the possibility of accurately segmenting highly camouflaged targets from a depth perspective. It uncovers depth cues in areas missed by SAM through mask reversion, self-filtering, and self-attention operations, compensating for its defects in the COD domain. DSAM represents the first step towards the SAM-based RGB-D COD model. It maximizes the utilization of depth features while synergizing with RGB features to achieve multimodal complementarity, thereby overcoming the segmentation limitations of SAM and improving its accuracy in COD. Experimental results on COD benchmarks demonstrate that DSAM achieves excellent segmentation performance and reaches the state-of-the-art (SOTA) on COD benchmarks with less consumption of training resources. The code will be available at https://github.com/guobaoxiao/DSAM.