 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-Forecast: A Multimodal Approach to Temporal Event Forecasting with Large Language Models
Aug 08, 2024
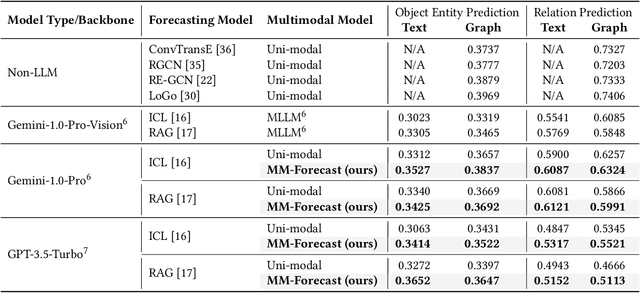
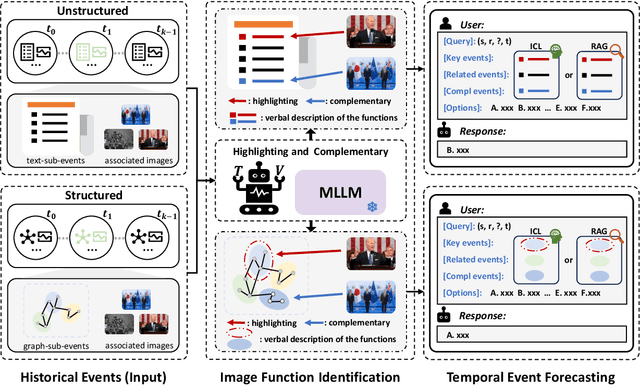
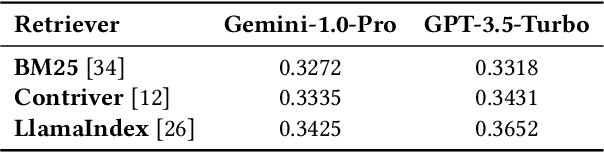
We study an emerging and intriguing problem of multimodal temporal event forecasting with large language models. Compared to using text or graph modalities, the investigation of utilizing images for temporal event forecasting has not been fully explored, especially in the era of large language models (LLMs). To bridge this gap, we are particularly interested in two key questions of: 1) why images will help in temporal event forecasting, and 2) how to integrate images into the LLM-based forecasting framework. To answer these research questions, we propose to identify two essential functions that images play in the scenario of temporal event forecasting, i.e., highlighting and complementary. Then, we develop a novel framework, named MM-Forecast. It employs an Image Function Identification module to recognize these functions as verbal descriptions using multimodal large language models (MLLMs), and subsequently incorporates these function descriptions into LLM-based forecasting models. To evaluate our approach, we construct a new multimodal dataset, MidEast-TE-mm, by extending an existing event dataset MidEast-TE-mini with images. Empirical studies demonstrate that our MM-Forecast can correctly identify the image functions, and further more, incorporating these verbal function descriptions significantly improves the forecasting performance. The dataset, code, and prompts are available at https://github.com/LuminosityX/MM-Forecast.