 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPS: Information Elicitation with Reinforcement Prompt Selection
Apr 15, 2026Large language models (LLMs) have shown remarkable capabilities in dialogue generation and reasoning, yet their effectiveness in eliciting user-known but concealed information in open-ended conversations remains limited. In many interactive AI applications, such as personal assistants, tutoring systems, and legal or clinical support, users often withhold sensitive or uncertain information due to privacy concerns, ambiguity, or social hesitation. This makes it challenging for LLMs to gather complete and contextually relevant inputs. In this work, we define the problem of information elicitation in open-ended dialogue settings and propose Reinforcement Prompt Selection (RPS), a lightweight reinforcement learning framework that formulates prompt selection as a sequential decision-making problem. To analyze this problem in a controlled setting, we design a synthetic experiment, where a reinforcement learning agent outperforms a random query baseline, illustrating the potential of policy-based approaches for adaptive information elicitation. Building on this insight, RPS learns a policy over a pool of prompts to adaptively elicit concealed or incompletely expressed information from users through dialogue. We also introduce IELegal, a new benchmark dataset constructed from real legal case documents, which simulates dialogue-based information elicitation tasks aimed at uncovering case-relevant facts. In this setting, RPS outperforms static prompt baselines, demonstrating the effectiveness of adaptive prompt selection for eliciting critical information in LLM-driven dialogue systems.
From Perception to Action: An Interactive Benchmark for Vision Reasoning
Feb 24, 2026Understanding the physical structure is essential for real-world applications such as embodied agents, interactive design, and long-horizon manipulation. Yet, prevailing Vision-Language Model (VLM) evaluations still center on structure-agnostic, single-turn setups (e.g., VQA), which fail to assess agents' ability to reason about how geometry, contact, and support relations jointly constrain what actions are possible in a dynamic environment. To address this gap, we introduce the Causal Hierarchy of Actions and Interactions (CHAIN) benchmark, an interactive 3D, physics-driven testbed designed to evaluate whether models can understand, plan, and execute structured action sequences grounded in physical constraints. CHAIN shifts evaluation from passive perception to active problem solving, spanning tasks such as interlocking mechanical puzzles and 3D stacking and packing. We conduct a comprehensive study of state-of-the-art VLMs and diffusion-based models under unified interactive settings. Our results show that top-performing models still struggle to internalize physical structure and causal constraints, often failing to produce reliable long-horizon plans and cannot robustly translate perceived structure into effective actions. The project is available at https://social-ai-studio.github.io/CHAIN/.
Learning Text Styles: A Study on Transfer, Attribution, and Verification
Jul 22, 2025This thesis advances the computational understanding and manipulation of text styles through three interconnected pillars: (1) Text Style Transfer (TST), which alters stylistic properties (e.g., sentiment, formality) while preserving content; (2)Authorship Attribution (AA), identifying the author of a text via stylistic fingerprints; and (3) Authorship Verification (AV), determining whether two texts share the same authorship. We address critical challenges in these areas by leveraging parameter-efficient adaptation of large language models (LLMs), contrastive disentanglement of stylistic features, and instruction-based fine-tuning for explainable verification.
Multimodal Mathematical Reasoning with Diverse Solving Perspective
Jul 03, 2025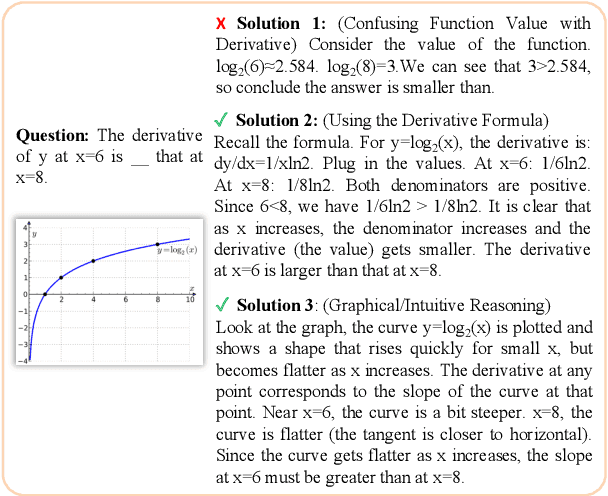
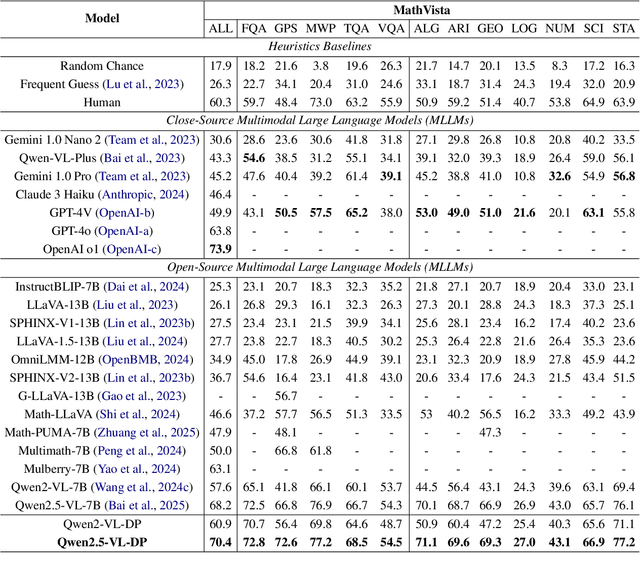
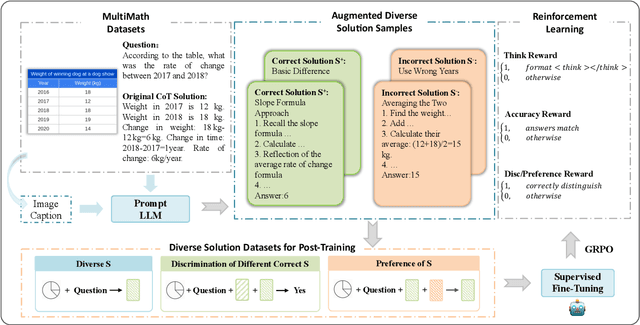
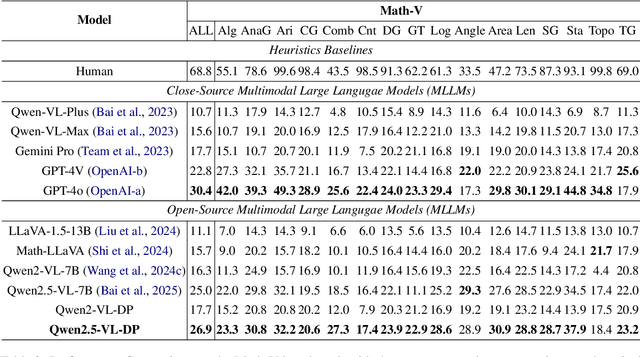
Recent progress in large-scale reinforcement learning (RL) has notably enhanced the reasoning capabilities of large language models (LLMs), especially in mathematical domains. However, current multimodal LLMs (MLLMs) for mathematical reasoning often rely on one-to-one image-text pairs and single-solution supervision, overlooking the diversity of valid reasoning perspectives and internal reflections. In this work, we introduce MathV-DP, a novel dataset that captures multiple diverse solution trajectories for each image-question pair, fostering richer reasoning supervision. We further propose Qwen-VL-DP, a model built upon Qwen-VL, fine-tuned with supervised learning and enhanced via group relative policy optimization (GRPO), a rule-based RL approach that integrates correctness discrimination and diversity-aware reward functions. Our method emphasizes learning from varied reasoning perspectives and distinguishing between correct yet distinct solutions. Extensive experiments on the MathVista's minitest and Math-V benchmarks demonstrate that Qwen-VL-DP significantly outperforms prior base MLLMs in both accuracy and generative diversity, highlighting the importance of incorporating diverse perspectives and reflective reasoning in multimodal mathematical reasoning.
LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning
Jun 23, 2025Ultra-long generation by large language models (LLMs) is a widely demanded scenario, yet it remains a significant challenge due to their maximum generation length limit and overall quality degradation as sequence length increases. Previous approaches, exemplified by LongWriter, typically rely on ''teaching'', which involves supervised fine-tuning (SFT) on synthetic long-form outputs. However, this strategy heavily depends on synthetic SFT data, which is difficult and costly to construct, often lacks coherence and consistency, and tends to be overly artificial and structurally monotonous. In this work, we propose an incentivization-based approach that, starting entirely from scratch and without relying on any annotated or synthetic data, leverages reinforcement learning (RL) to foster the emergence of ultra-long, high-quality text generation capabilities in LLMs. We perform RL training starting from a base model, similar to R1-Zero, guiding it to engage in reasoning that facilitates planning and refinement during the writing process. To support this, we employ specialized reward models that steer the LLM towards improved length control, writing quality, and structural formatting. Experimental evaluations show that our LongWriter-Zero model, trained from Qwen2.5-32B, consistently outperforms traditional SFT methods on long-form writing tasks, achieving state-of-the-art results across all metrics on WritingBench and Arena-Write, and even surpassing 100B+ models such as DeepSeek R1 and Qwen3-235B. We open-source our data and model checkpoints under https://huggingface.co/THU-KEG/LongWriter-Zero-32B
SuperWriter: Reflection-Driven Long-Form Generation with Large Language Models
Jun 04, 2025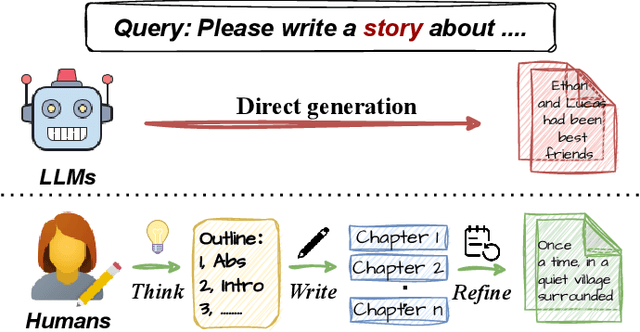


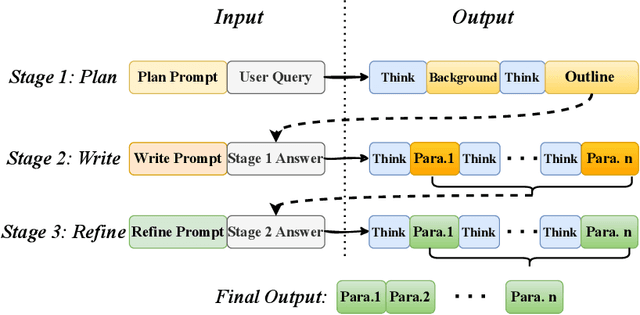
Long-form text generation remains a significant challenge for large language models (LLMs), particularly in maintaining coherence, ensuring logical consistency, and preserving text quality as sequence length increases. To address these limitations, we propose SuperWriter-Agent, an agent-based framework designed to enhance the quality and consistency of long-form text generation. SuperWriter-Agent introduces explicit structured thinking-through planning and refinement stages into the generation pipeline, guiding the model to follow a more deliberate and cognitively grounded process akin to that of a professional writer. Based on this framework, we construct a supervised fine-tuning dataset to train a 7B SuperWriter-LM. We further develop a hierarchical Direct Preference Optimization (DPO) procedure that uses Monte Carlo Tree Search (MCTS) to propagate final quality assessments and optimize each generation step accordingly. Empirical results across diverse benchmarks demonstrate that SuperWriter-LM achieves state-of-the-art performance, surpassing even larger-scale baseline models in both automatic evaluation and human evaluation. Furthermore, comprehensive ablation studies demonstrate the effectiveness of hierarchical DPO and underscore the value of incorporating structured thinking steps to improve the quality of long-form text generation.
REMEDI: Relative Feature Enhanced Meta-Learning with Distillation for Imbalanced Prediction
May 12, 2025Predicting future vehicle purchases among existing owners presents a critical challenge due to extreme class imbalance (<0.5% positive rate) and complex behavioral patterns. We propose REMEDI (Relative feature Enhanced Meta-learning with Distillation for Imbalanced prediction), a novel multi-stage framework addressing these challenges. REMEDI first trains diverse base models to capture complementary aspects of user behavior. Second, inspired by comparative op-timization techniques, we introduce relative performance meta-features (deviation from ensemble mean, rank among peers) for effective model fusion through a hybrid-expert architecture. Third, we distill the ensemble's knowledge into a single efficient model via supervised fine-tuning with MSE loss, enabling practical deployment. Evaluated on approximately 800,000 vehicle owners, REMEDI significantly outperforms baseline approaches, achieving the business target of identifying ~50% of actual buyers within the top 60,000 recommendations at ~10% precision. The distilled model preserves the ensemble's predictive power while maintaining deployment efficiency, demonstrating REMEDI's effectiveness for imbalanced prediction in industry settings.
Benchmarking Multimodal Mathematical Reasoning with Explicit Visual Dependency
Apr 29, 2025Recent advancements in Large Vision-Language Models (LVLMs) have significantly enhanced their ability to integrate visual and linguistic information, achieving near-human proficiency in tasks like object recognition, captioning, and visual question answering. However, current benchmarks typically focus on knowledge-centric evaluations that assess domain-specific expertise, often neglecting the core ability to reason about fundamental mathematical elements and visual concepts. We identify a gap in evaluating elementary-level math problems, which rely on explicit visual dependencies-requiring models to discern, integrate, and reason across multiple images while incorporating commonsense knowledge, all of which are crucial for advancing toward broader AGI capabilities. To address this gap, we introduce VCBENCH, a comprehensive benchmark for multimodal mathematical reasoning with explicit visual dependencies. VCBENCH includes 1,720 problems across six cognitive domains, featuring 6,697 images (averaging 3.9 per question) to ensure multi-image reasoning. We evaluate 26 state-of-the-art LVLMs on VCBENCH, revealing substantial performance disparities, with even the top models unable to exceed 50% accuracy. Our findings highlight the ongoing challenges in visual-mathematical integration and suggest avenues for future LVLM advancements.
Rethinking the generalization of drug target affinity prediction algorithms via similarity aware evaluation
Apr 13, 2025Drug-target binding affinity prediction is a fundamental task for drug discovery. It has been extensively explored in literature and promising results are reported. However, in this paper, we demonstrate that the results may be misleading and cannot be well generalized to real practice. The core observation is that the canonical randomized split of a test set in conventional evaluation leaves the test set dominated by samples with high similarity to the training set. The performance of models is severely degraded on samples with lower similarity to the training set but the drawback is highly overlooked in current evaluation. As a result, the performance can hardly be trusted when the model meets low-similarity samples in real practice. To address this problem, we propose a framework of similarity aware evaluation in which a novel split methodology is proposed to adapt to any desired distribution. This is achieved by a formulation of optimization problems which are approximately and efficiently solved by gradient descent. We perform extensive experiments across five representative methods in four datasets for two typical target evaluations and compare them with various counterpart methods. Results demonstrate that the proposed split methodology can significantly better fit desired distributions and guide the development of models. Code is released at https://github.com/Amshoreline/SAE/tree/main.
Breaking the Memory Barrier: Near Infinite Batch Size Scaling for Contrastive Loss
Oct 22, 2024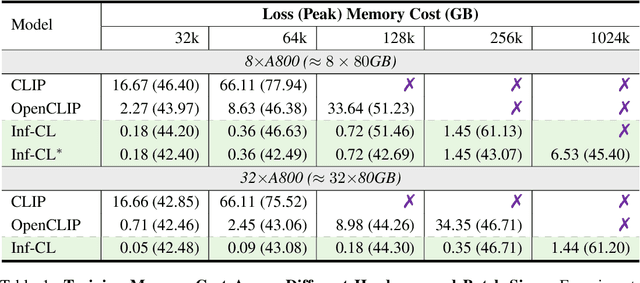
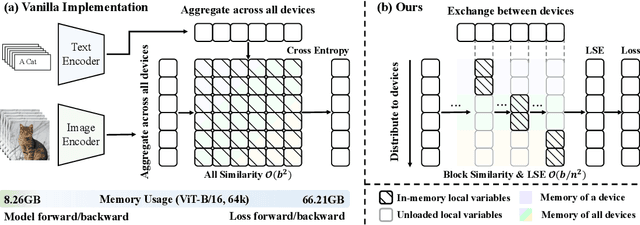
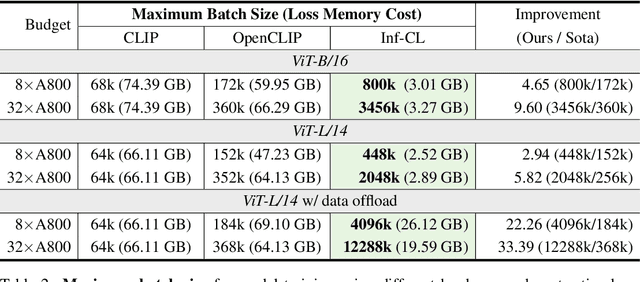
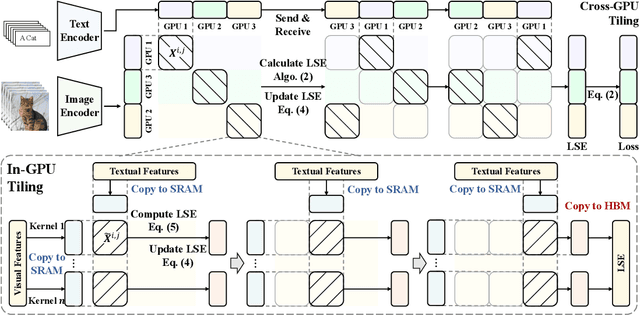
Contrastive loss is a powerful approach for representation learning, where larger batch sizes enhance performance by providing more negative samples to better distinguish between similar and dissimilar data. However, scaling batch sizes is constrained by the quadratic growth in GPU memory consumption, primarily due to the full instantiation of the similarity matrix. To address this, we propose a tile-based computation strategy that partitions the contrastive loss calculation into arbitrary small blocks, avoiding full materialization of the similarity matrix. Furthermore, we introduce a multi-level tiling strategy to leverage the hierarchical structure of distributed systems, employing ring-based communication at the GPU level to optimize synchronization and fused kernels at the CUDA core level to reduce I/O overhead. Experimental results show that the proposed method scales batch sizes to unprecedented levels. For instance, it enables contrastive training of a CLIP-ViT-L/14 model with a batch size of 4M or 12M using 8 or 32 A800 80GB without sacrificing any accuracy. Compared to SOTA memory-efficient solutions, it achieves a two-order-of-magnitude reduction in memory while maintaining comparable speed. The code will be made publicly available.