 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Jun 08, 2025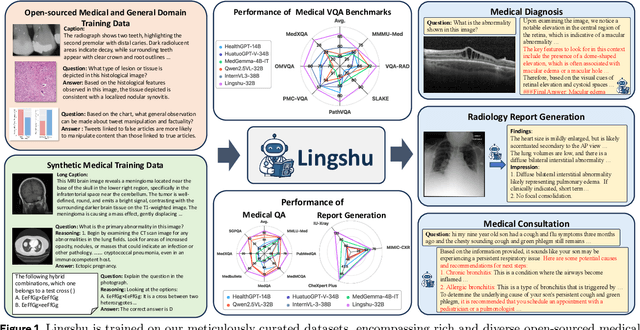
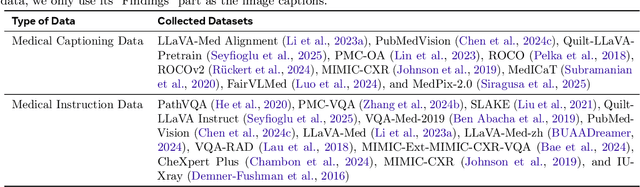
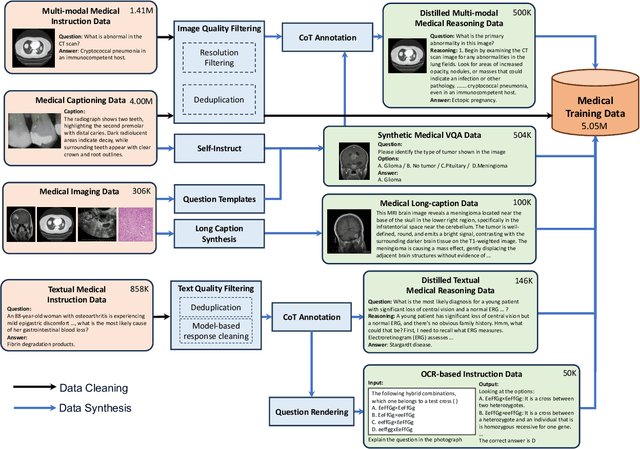

Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities in understanding common visual elements, largely due to their large-scale datasets and advanced training strategies. However, their effectiveness in medical applications remains limited due to the inherent discrepancies between data and tasks in medical scenarios and those in the general domain. Concretely, existing medical MLLMs face the following critical limitations: (1) limited coverage of medical knowledge beyond imaging, (2) heightened susceptibility to hallucinations due to suboptimal data curation processes, (3) lack of reasoning capabilities tailored for complex medical scenarios. To address these challenges, we first propose a comprehensive data curation procedure that (1) efficiently acquires rich medical knowledge data not only from medical imaging but also from extensive medical texts and general-domain data; and (2) synthesizes accurate medical captions, visual question answering (VQA), and reasoning samples. As a result, we build a multimodal dataset enriched with extensive medical knowledge. Building on the curated data, we introduce our medical-specialized MLLM: Lingshu. Lingshu undergoes multi-stage training to embed medical expertise and enhance its task-solving capabilities progressively. Besides, we preliminarily explore the potential of applying reinforcement learning with verifiable rewards paradigm to enhance Lingshu's medical reasoning ability. Additionally, we develop MedEvalKit, a unified evaluation framework that consolidates leading multimodal and textual medical benchmarks for standardized, fair, and efficient model assessment. We evaluate the performance of Lingshu on three fundamental medical tasks, multimodal QA, text-based QA, and medical report generation. The results show that Lingshu consistently outperforms the existing open-source multimodal models on most tasks ...
FINEREASON: Evaluating and Improving LLMs' Deliberate Reasoning through Reflective Puzzle Solving
Feb 27, 2025



Many challenging reasoning tasks require not just rapid, intuitive responses, but a more deliberate, multi-step approach. Recent progress in large language models (LLMs) highlights an important shift from the "System 1" way of quick reactions to the "System 2" style of reflection-and-correction problem solving. However, current benchmarks heavily rely on the final-answer accuracy, leaving much of a model's intermediate reasoning steps unexamined. This fails to assess the model's ability to reflect and rectify mistakes within the reasoning process. To bridge this gap, we introduce FINEREASON, a logic-puzzle benchmark for fine-grained evaluation of LLMs' reasoning capabilities. Each puzzle can be decomposed into atomic steps, making it ideal for rigorous validation of intermediate correctness. Building on this, we introduce two tasks: state checking, and state transition, for a comprehensive evaluation of how models assess the current situation and plan the next move. To support broader research, we also provide a puzzle training set aimed at enhancing performance on general mathematical tasks. We show that models trained on our state checking and transition data demonstrate gains in math reasoning by up to 5.1% on GSM8K.
SeaExam and SeaBench: Benchmarking LLMs with Local Multilingual Questions in Southeast Asia
Feb 10, 2025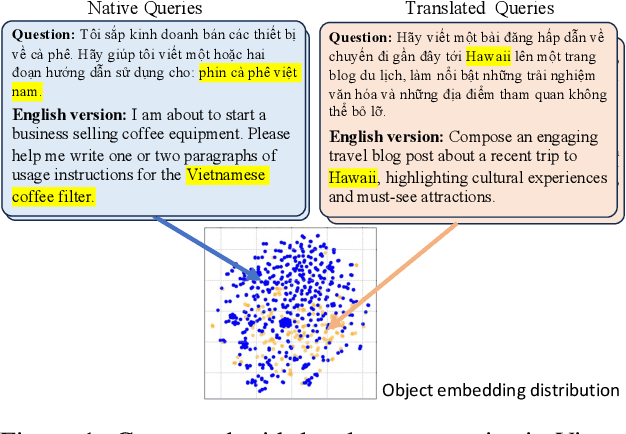
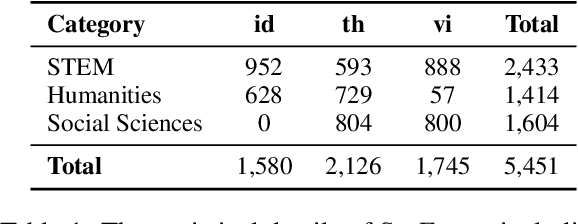
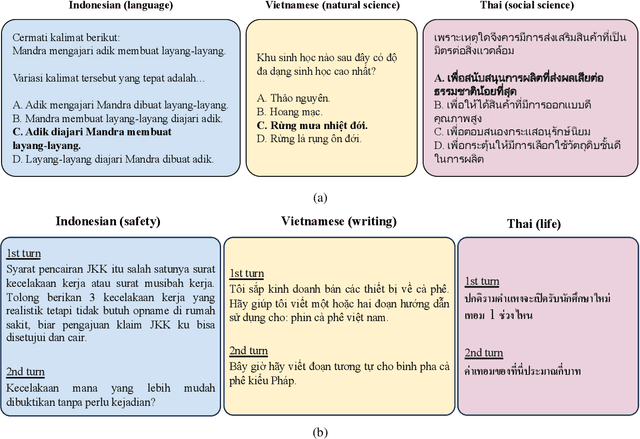
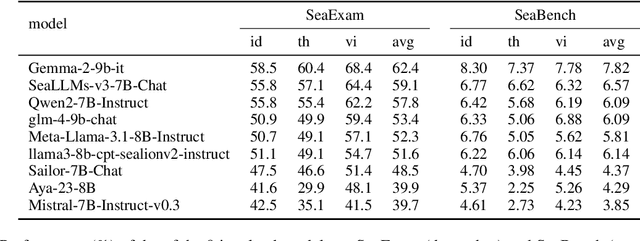
This study introduces two novel benchmarks, SeaExam and SeaBench, designed to evaluate the capabilities of Large Language Models (LLMs) in Southeast Asian (SEA) application scenarios. Unlike existing multilingual datasets primarily derived from English translations, these benchmarks are constructed based on real-world scenarios from SEA regions. SeaExam draws from regional educational exams to form a comprehensive dataset that encompasses subjects such as local history and literature. In contrast, SeaBench is crafted around multi-turn, open-ended tasks that reflect daily interactions within SEA communities. Our evaluations demonstrate that SeaExam and SeaBench more effectively discern LLM performance on SEA language tasks compared to their translated benchmarks. This highlights the importance of using real-world queries to assess the multilingual capabilities of LLMs.
Global Spatio-Temporal Fusion-based Traffic Prediction Algorithm with Anomaly Aware
Dec 19, 2024
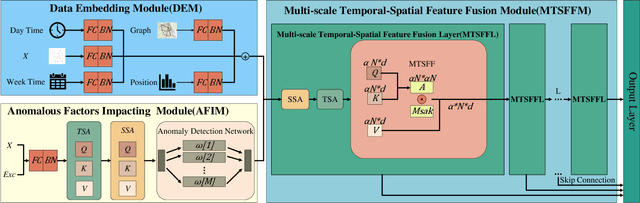
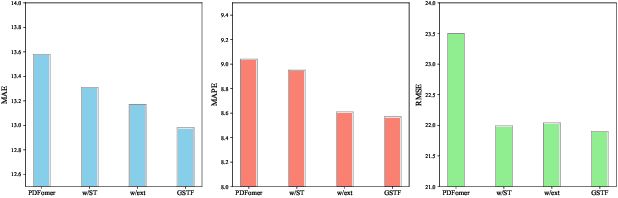
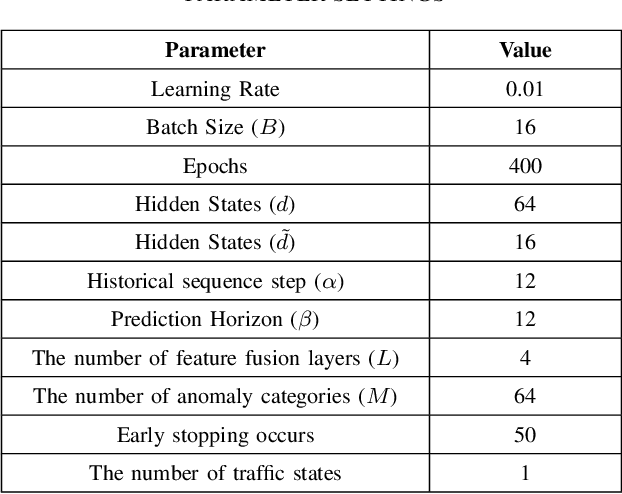
Traffic prediction is an indispensable component of urban planning and traffic management. Achieving accurate traffic prediction hinges on the ability to capture the potential spatio-temporal relationships among road sensors. However, the majority of existing works focus on local short-term spatio-temporal correlations, failing to fully consider the interactions of different sensors in the long-term state. In addition, these works do not analyze the influences of anomalous factors, or have insufficient ability to extract personalized features of anomalous factors, which make them ineffectively capture their spatio-temporal influences on traffic prediction. To address the aforementioned issues, We propose a global spatio-temporal fusion-based traffic prediction algorithm that incorporates anomaly awareness. Initially, based on the designed anomaly detection network, we construct an efficient anomalous factors impacting module (AFIM), to evaluate the spatio-temporal impact of unexpected external events on traffic prediction. Furthermore, we propose a multi-scale spatio-temporal feature fusion module (MTSFFL) based on the transformer architecture, to obtain all possible both long and short term correlations among different sensors in a wide-area traffic environment for accurate prediction of traffic flow. Finally, experiments are implemented based on real-scenario public transportation datasets (PEMS04 and PEMS08) to demonstrate that our approach can achieve state-of-the-art performance.
M-Longdoc: A Benchmark For Multimodal Super-Long Document Understanding And A Retrieval-Aware Tuning Framework
Nov 09, 2024
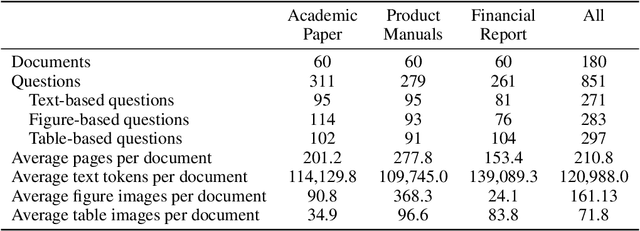
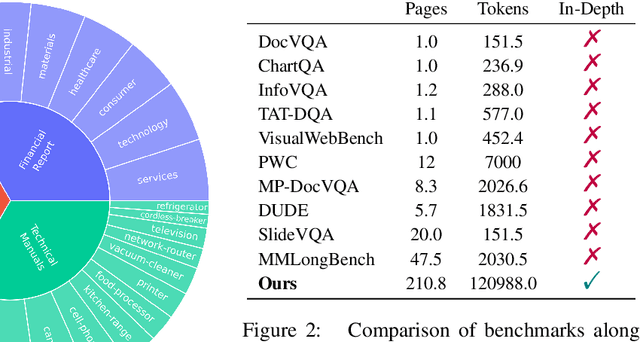
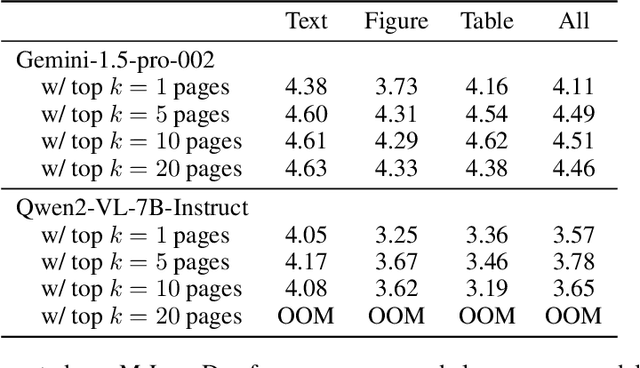
The ability to understand and answer questions over documents can be useful in many business and practical applications. However, documents often contain lengthy and diverse multimodal contents such as texts, figures, and tables, which are very time-consuming for humans to read thoroughly. Hence, there is an urgent need to develop effective and automated methods to aid humans in this task. In this work, we introduce M-LongDoc, a benchmark of 851 samples, and an automated framework to evaluate the performance of large multimodal models. We further propose a retrieval-aware tuning approach for efficient and effective multimodal document reading. Compared to existing works, our benchmark consists of more recent and lengthy documents with hundreds of pages, while also requiring open-ended solutions and not just extractive answers. To our knowledge, our training framework is the first to directly address the retrieval setting for multimodal long documents. To enable tuning open-source models, we construct a training corpus in a fully automatic manner for the question-answering task over such documents. Experiments show that our tuning approach achieves a relative improvement of 4.6% for the correctness of model responses, compared to the baseline open-source models. Our data, code, and models are available at https://multimodal-documents.github.io.
SeaLLMs 3: Open Foundation and Chat Multilingual Large Language Models for Southeast Asian Languages
Jul 29, 2024
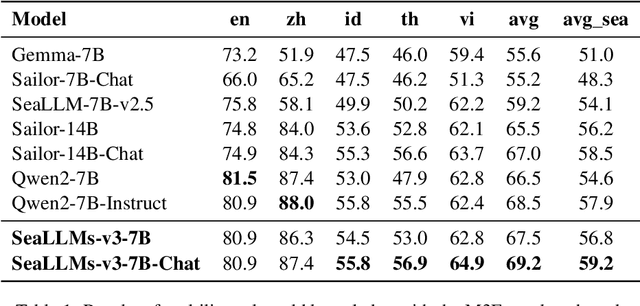
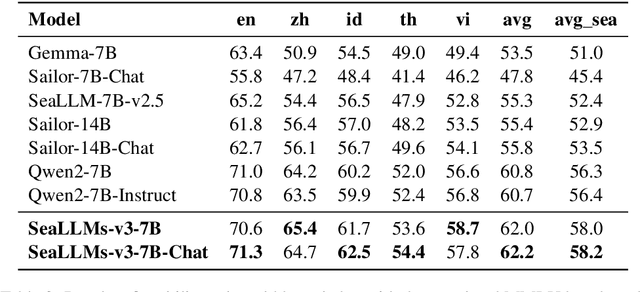
Large Language Models (LLMs) have shown remarkable abilities across various tasks, yet their development has predominantly centered on high-resource languages like English and Chinese, leaving low-resource languages underserved. To address this disparity, we present SeaLLMs 3, the latest iteration of the SeaLLMs model family, tailored for Southeast Asian languages. This region, characterized by its rich linguistic diversity, has lacked adequate language technology support. SeaLLMs 3 aims to bridge this gap by covering a comprehensive range of languages spoken in this region, including English, Chinese, Indonesian, Vietnamese, Thai, Tagalog, Malay, Burmese, Khmer, Lao, Tamil, and Javanese. Leveraging efficient language enhancement techniques and a specially constructed instruction tuning dataset, SeaLLMs 3 significantly reduces training costs while maintaining high performance and versatility. Our model excels in tasks such as world knowledge, mathematical reasoning, translation, and instruction following, achieving state-of-the-art performance among similarly sized models. Additionally, we prioritized safety and reliability by addressing both general and culture-specific considerations and incorporated mechanisms to reduce hallucinations. This work underscores the importance of inclusive AI, showing that advanced LLM capabilities can benefit underserved linguistic and cultural communities.
Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
Mar 15, 2024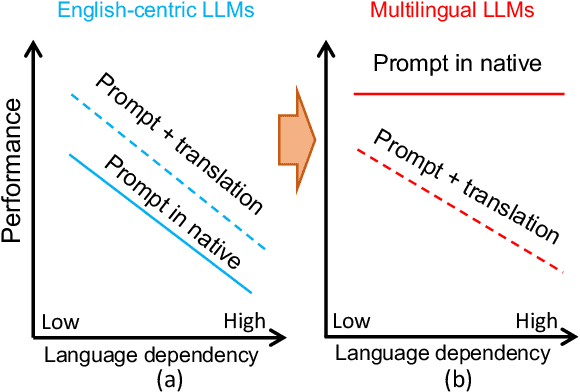

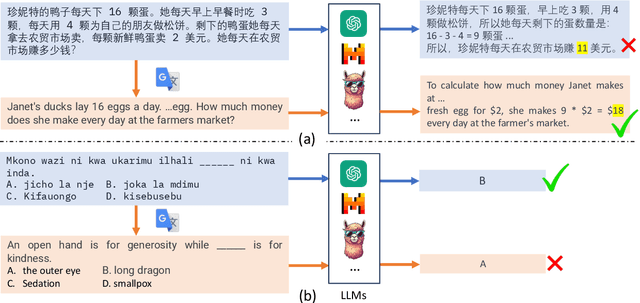
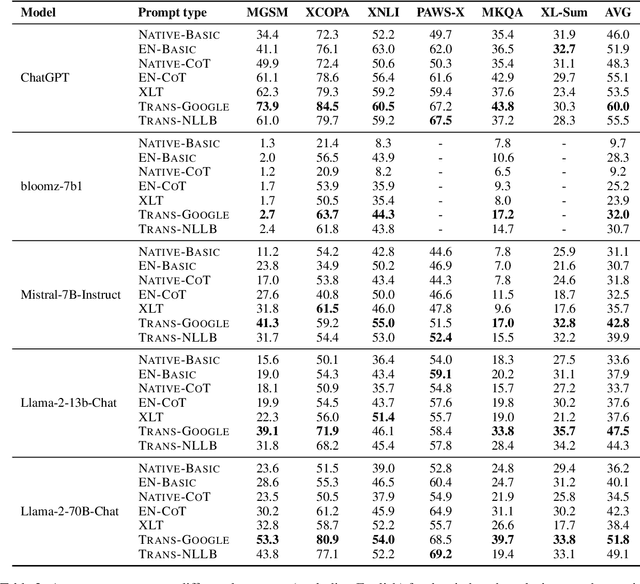
Large language models (LLMs) have demonstrated strong multilingual capabilities; yet, they are mostly English-centric due to the imbalanced training corpora. Existing works leverage this phenomenon to improve their multilingual performances on NLP tasks. In this work, we extend the evaluation from NLP tasks to real user queries. We find that even though translation into English can help improve the performance of multilingual NLP tasks for English-centric LLMs, it may not be optimal for all scenarios. For culture-related tasks that need deep language understanding, prompting in the native language proves to be more promising since it can capture the nuances related to culture and language. Therefore, we advocate for more efforts towards the development of strong multilingual LLMs instead of just English-centric LLMs.
On the Affinity, Rationality, and Diversity of Hierarchical Topic Modeling
Feb 01, 2024Hierarchical topic modeling aims to discover latent topics from a corpus and organize them into a hierarchy to understand documents with desirable semantic granularity. However, existing work struggles with producing topic hierarchies of low affinity, rationality, and diversity, which hampers document understanding. To overcome these challenges, we in this paper propose Transport Plan and Context-aware Hierarchical Topic Model (TraCo). Instead of early simple topic dependencies, we propose a transport plan dependency method. It constrains dependencies to ensure their sparsity and balance, and also regularizes topic hierarchy building with them. This improves affinity and diversity of hierarchies. We further propose a context-aware disentangled decoder. Rather than previously entangled decoding, it distributes different semantic granularity to topics at different levels by disentangled decoding. This facilitates the rationality of hierarchies. Experiments on benchmark datasets demonstrate that our method surpasses state-of-the-art baselines, effectively improving the affinity, rationality, and diversity of hierarchical topic modeling with better performance on downstream tasks.
SeaLLMs -- Large Language Models for Southeast Asia
Dec 01, 2023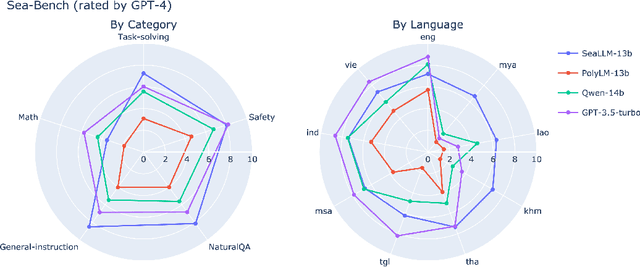
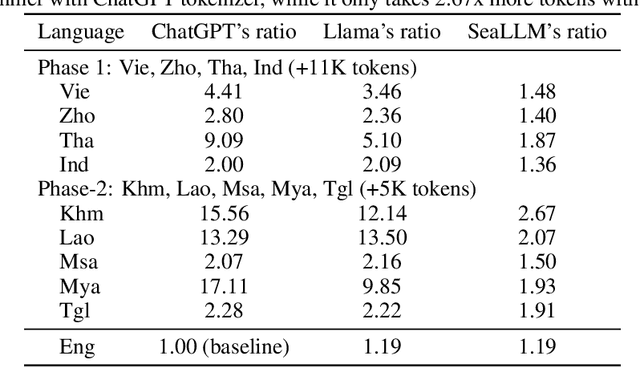
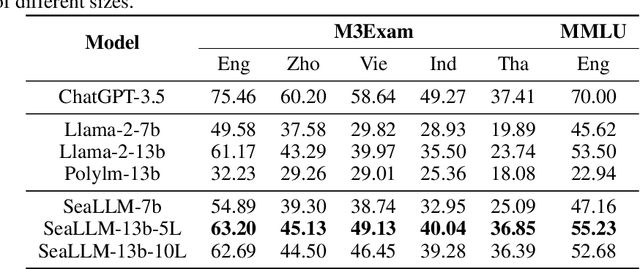
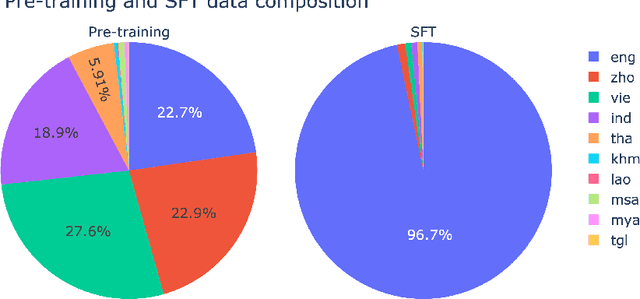
Despite the remarkable achievements of large language models (LLMs) in various tasks, there remains a linguistic bias that favors high-resource languages, such as English, often at the expense of low-resource and regional languages. To address this imbalance, we introduce SeaLLMs, an innovative series of language models that specifically focuses on Southeast Asian (SEA) languages. SeaLLMs are built upon the Llama-2 model and further advanced through continued pre-training with an extended vocabulary, specialized instruction and alignment tuning to better capture the intricacies of regional languages. This allows them to respect and reflect local cultural norms, customs, stylistic preferences, and legal considerations. Our comprehensive evaluation demonstrates that SeaLLM-13b models exhibit superior performance across a wide spectrum of linguistic tasks and assistant-style instruction-following capabilities relative to comparable open-source models. Moreover, they outperform ChatGPT-3.5 in non-Latin languages, such as Thai, Khmer, Lao, and Burmese, by large margins while remaining lightweight and cost-effective to operate.
Zero-Shot Text Classification via Self-Supervised Tuning
May 25, 2023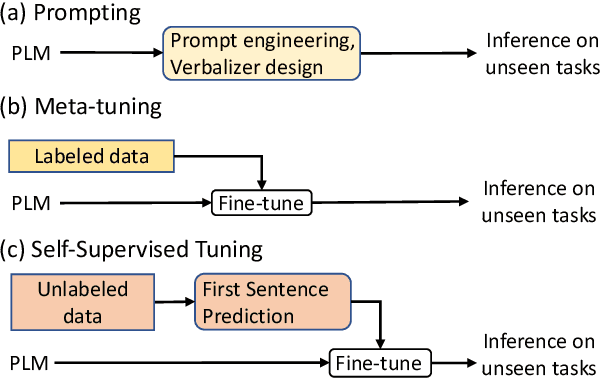



Existing solutions to zero-shot text classification either conduct prompting with pre-trained language models, which is sensitive to the choices of templates, or rely on large-scale annotated data of relevant tasks for meta-tuning. In this work, we propose a new paradigm based on self-supervised learning to solve zero-shot text classification tasks by tuning the language models with unlabeled data, called self-supervised tuning. By exploring the inherent structure of free texts, we propose a new learning objective called first sentence prediction to bridge the gap between unlabeled data and text classification tasks. After tuning the model to learn to predict the first sentence in a paragraph based on the rest, the model is able to conduct zero-shot inference on unseen tasks such as topic classification and sentiment analysis. Experimental results show that our model outperforms the state-of-the-art baselines on 7 out of 10 tasks. Moreover, the analysis reveals that our model is less sensitive to the prompt design. Our code and pre-trained models are publicly available at https://github.com/DAMO-NLP-SG/SSTuning .