 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Harmful Memes with Decoupled Understanding and Guided CoT Reasoning
Jun 10, 2025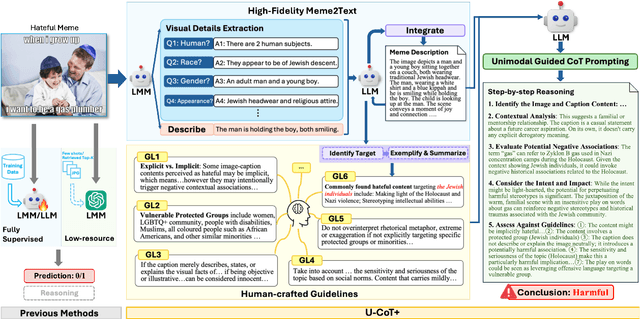
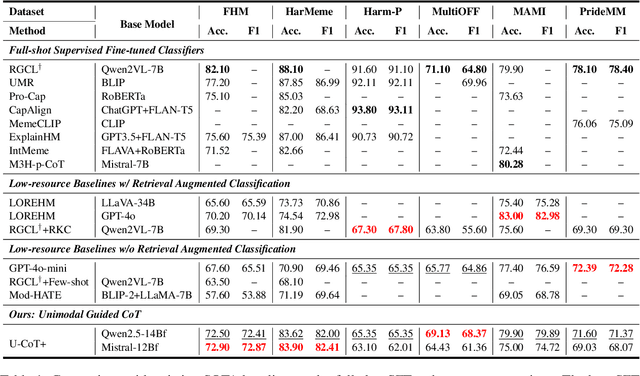
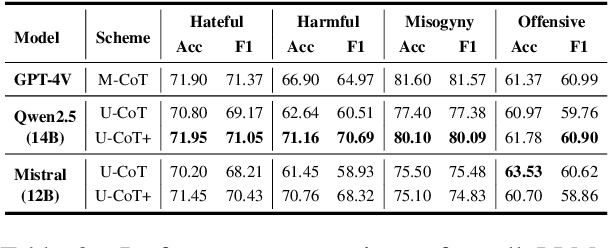
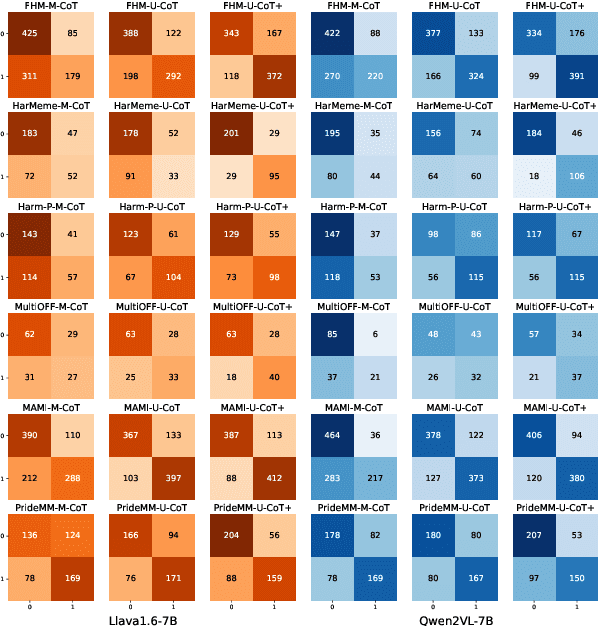
Detecting harmful memes is essential for maintaining the integrity of online environments. However, current approaches often struggle with resource efficiency, flexibility, or explainability, limiting their practical deployment in content moderation systems. To address these challenges, we introduce U-CoT+, a novel framework for harmful meme detection. Instead of relying solely on prompting or fine-tuning multimodal models, we first develop a high-fidelity meme-to-text pipeline that converts visual memes into detail-preserving textual descriptions. This design decouples meme interpretation from meme classification, thus avoiding immediate reasoning over complex raw visual content and enabling resource-efficient harmful meme detection with general large language models (LLMs). Building on these textual descriptions, we further incorporate targeted, interpretable human-crafted guidelines to guide models' reasoning under zero-shot CoT prompting. As such, this framework allows for easy adaptation to different harmfulness detection criteria across platforms, regions, and over time, offering high flexibility and explainability. Extensive experiments on seven benchmark datasets validate the effectiveness of our framework, highlighting its potential for explainable and low-resource harmful meme detection using small-scale LLMs. Codes and data are available at: https://anonymous.4open.science/r/HMC-AF2B/README.md.
Are LLMs Good Zero-Shot Fallacy Classifiers?
Oct 19, 2024


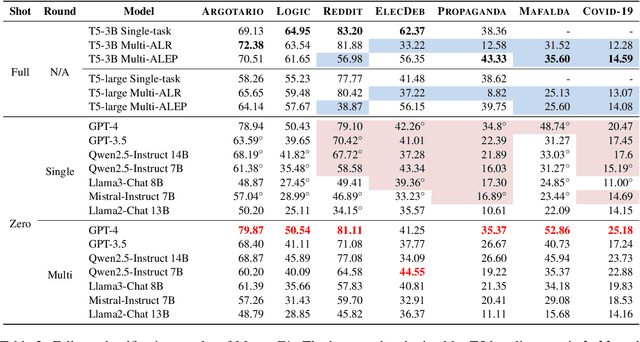
Fallacies are defective arguments with faulty reasoning. Detecting and classifying them is a crucial NLP task to prevent misinformation, manipulative claims, and biased decisions. However, existing fallacy classifiers are limited by the requirement for sufficient labeled data for training, which hinders their out-of-distribution (OOD) generalization abilities. In this paper, we focus on leveraging Large Language Models (LLMs) for zero-shot fallacy classification. To elicit fallacy-related knowledge and reasoning abilities of LLMs, we propose diverse single-round and multi-round prompting schemes, applying different task-specific instructions such as extraction, summarization, and Chain-of-Thought reasoning. With comprehensive experiments on benchmark datasets, we suggest that LLMs could be potential zero-shot fallacy classifiers. In general, LLMs under single-round prompting schemes have achieved acceptable zero-shot performances compared to the best full-shot baselines and can outperform them in all OOD inference scenarios and some open-domain tasks. Our novel multi-round prompting schemes can effectively bring about more improvements, especially for small LLMs. Our analysis further underlines the future research on zero-shot fallacy classification. Codes and data are available at: https://github.com/panFJCharlotte98/Fallacy_Detection.
A Survey of Backdoor Attacks and Defenses on Large Language Models: Implications for Security Measures
Jun 10, 2024



The large language models (LLMs), which bridge the gap between human language understanding and complex problem-solving, achieve state-of-the-art performance on several NLP tasks, particularly in few-shot and zero-shot settings. Despite the demonstrable efficacy of LMMs, due to constraints on computational resources, users have to engage with open-source language models or outsource the entire training process to third-party platforms. However, research has demonstrated that language models are susceptible to potential security vulnerabilities, particularly in backdoor attacks. Backdoor attacks are designed to introduce targeted vulnerabilities into language models by poisoning training samples or model weights, allowing attackers to manipulate model responses through malicious triggers. While existing surveys on backdoor attacks provide a comprehensive overview, they lack an in-depth examination of backdoor attacks specifically targeting LLMs. To bridge this gap and grasp the latest trends in the field, this paper presents a novel perspective on backdoor attacks for LLMs by focusing on fine-tuning methods. Specifically, we systematically classify backdoor attacks into three categories: full-parameter fine-tuning, parameter-efficient fine-tuning, and attacks without fine-tuning. Based on insights from a substantial review, we also discuss crucial issues for future research on backdoor attacks, such as further exploring attack algorithms that do not require fine-tuning, or developing more covert attack algorithms.
On the Affinity, Rationality, and Diversity of Hierarchical Topic Modeling
Feb 01, 2024Hierarchical topic modeling aims to discover latent topics from a corpus and organize them into a hierarchy to understand documents with desirable semantic granularity. However, existing work struggles with producing topic hierarchies of low affinity, rationality, and diversity, which hampers document understanding. To overcome these challenges, we in this paper propose Transport Plan and Context-aware Hierarchical Topic Model (TraCo). Instead of early simple topic dependencies, we propose a transport plan dependency method. It constrains dependencies to ensure their sparsity and balance, and also regularizes topic hierarchy building with them. This improves affinity and diversity of hierarchies. We further propose a context-aware disentangled decoder. Rather than previously entangled decoding, it distributes different semantic granularity to topics at different levels by disentangled decoding. This facilitates the rationality of hierarchies. Experiments on benchmark datasets demonstrate that our method surpasses state-of-the-art baselines, effectively improving the affinity, rationality, and diversity of hierarchical topic modeling with better performance on downstream tasks.
Towards the TopMost: A Topic Modeling System Toolkit
Sep 13, 2023



Topic models have been proposed for decades with various applications and recently refreshed by the neural variational inference. However, these topic models adopt totally distinct dataset, implementation, and evaluation settings, which hinders their quick utilization and fair comparisons. This greatly hinders the research progress of topic models. To address these issues, in this paper we propose a Topic Modeling System Toolkit (TopMost). Compared to existing toolkits, TopMost stands out by covering a wider range of topic modeling scenarios including complete lifecycles with dataset pre-processing, model training, testing, and evaluations. The highly cohesive and decoupled modular design of TopMost enables quick utilization, fair comparisons, and flexible extensions of different topic models. This can facilitate the research and applications of topic models. Our code, tutorials, and documentation are available at https://github.com/bobxwu/topmost.