 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeaLLMs -- Large Language Models for Southeast Asia
Dec 01, 2023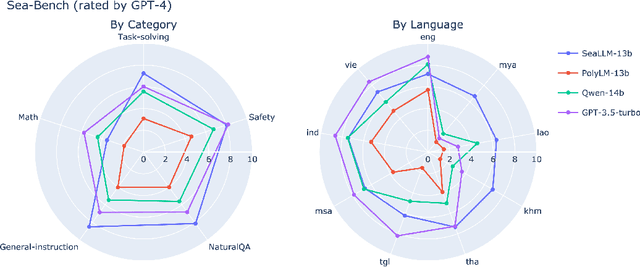
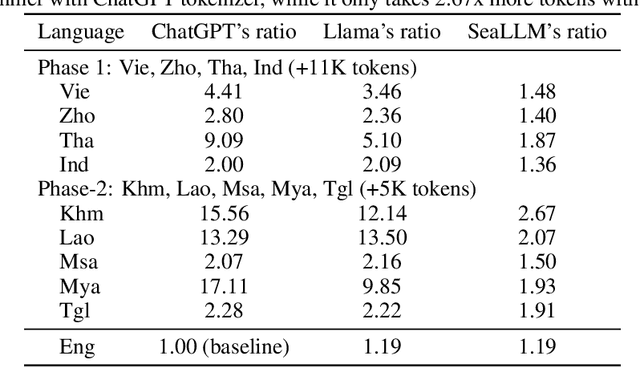
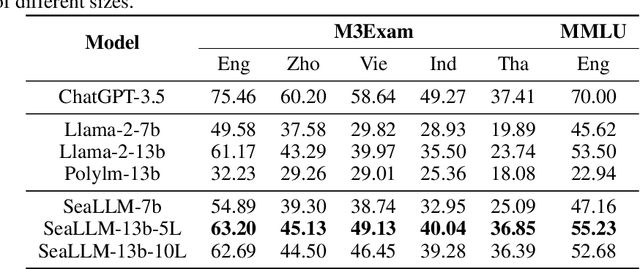
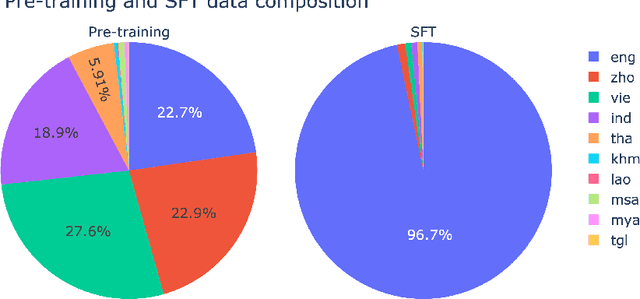
Despite the remarkable achievements of large language models (LLMs) in various tasks, there remains a linguistic bias that favors high-resource languages, such as English, often at the expense of low-resource and regional languages. To address this imbalance, we introduce SeaLLMs, an innovative series of language models that specifically focuses on Southeast Asian (SEA) languages. SeaLLMs are built upon the Llama-2 model and further advanced through continued pre-training with an extended vocabulary, specialized instruction and alignment tuning to better capture the intricacies of regional languages. This allows them to respect and reflect local cultural norms, customs, stylistic preferences, and legal considerations. Our comprehensive evaluation demonstrates that SeaLLM-13b models exhibit superior performance across a wide spectrum of linguistic tasks and assistant-style instruction-following capabilities relative to comparable open-source models. Moreover, they outperform ChatGPT-3.5 in non-Latin languages, such as Thai, Khmer, Lao, and Burmese, by large margins while remaining lightweight and cost-effective to operate.
Towards Robust Temporal Reasoning of Large Language Models via a Multi-Hop QA Dataset and Pseudo-Instruction Tuning
Nov 16, 2023Knowledge in the real world is being updated constantly. However, it is costly to frequently update large language models (LLMs). Therefore, it is crucial for LLMs to understand the concept of temporal knowledge. However, prior works on temporal question answering did not emphasize multi-answer and multi-hop types of temporal reasoning. In this paper, we propose a complex temporal question-answering (QA) dataset Complex-TR that focuses on multi-answer and multi-hop temporal reasoning. Besides, we also propose a novel data augmentation strategy to improve the complex temporal reasoning capability and robustness of LLMs. We conducted experiments on multiple temporal QA datasets. Experimental results show that our method is able to improve LLMs' performance on temporal QA benchmarks by significant margins.
Towards Benchmarking and Improving the Temporal Reasoning Capability of Large Language Models
Jun 27, 2023



Reasoning about time is of fundamental importance. Many facts are time-dependent. For example, athletes change teams from time to time, and different government officials are elected periodically. Previous time-dependent question answering (QA) datasets tend to be biased in either their coverage of time spans or question types. In this paper, we introduce a comprehensive probing dataset \tempreason to evaluate the temporal reasoning capability of large language models. Our dataset includes questions of three temporal reasoning levels. In addition, we also propose a novel learning framework to improve the temporal reasoning capability of large language models, based on temporal span extraction and time-sensitive reinforcement learning. We conducted experiments in closed book QA, open book QA, and reasoning QA settings and demonstrated the effectiveness of our approach. Our code and data are released on https://github.com/DAMO-NLP-SG/TempReason.
Class-Adaptive Self-Training for Relation Extraction with Incompletely Annotated Training Data
Jun 16, 2023
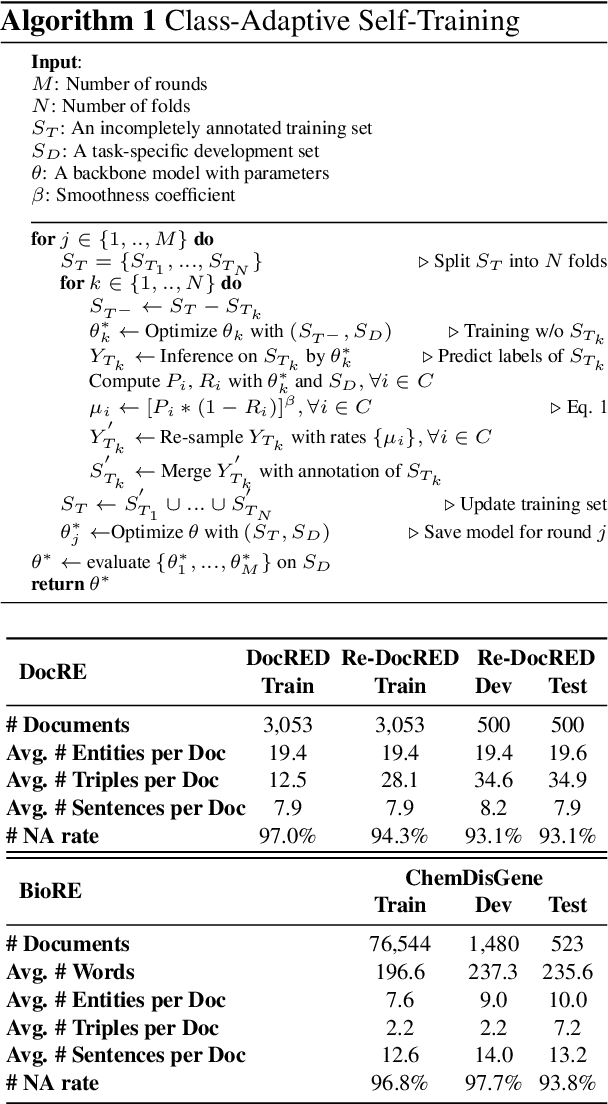
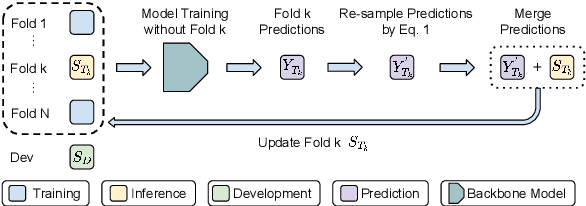
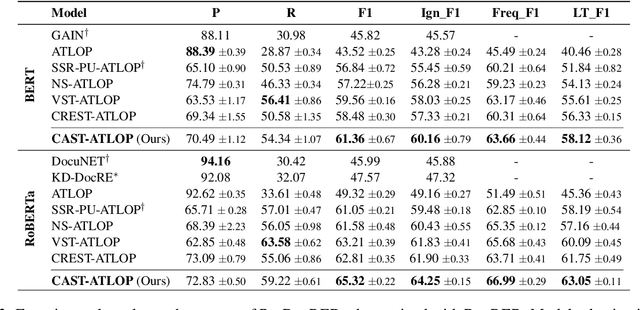
Relation extraction (RE) aims to extract relations from sentences and documents. Existing relation extraction models typically rely on supervised machine learning. However, recent studies showed that many RE datasets are incompletely annotated. This is known as the false negative problem in which valid relations are falsely annotated as 'no_relation'. Models trained with such data inevitably make similar mistakes during the inference stage. Self-training has been proven effective in alleviating the false negative problem. However, traditional self-training is vulnerable to confirmation bias and exhibits poor performance in minority classes. To overcome this limitation, we proposed a novel class-adaptive re-sampling self-training framework. Specifically, we re-sampled the pseudo-labels for each class by precision and recall scores. Our re-sampling strategy favored the pseudo-labels of classes with high precision and low recall, which improved the overall recall without significantly compromising precision. We conducted experiments on document-level and biomedical relation extraction datasets, and the results showed that our proposed self-training framework consistently outperforms existing competitive methods on the Re-DocRED and ChemDisgene datasets when the training data are incompletely annotated. Our code is released at https://github.com/DAMO-NLP-SG/CAST.
Unlocking Temporal Question Answering for Large Language Models Using Code Execution
May 24, 2023Large language models (LLMs) have made significant progress in natural language processing (NLP), and are utilized extensively in various applications. Recent works, such as chain-of-thought (CoT), have shown that intermediate reasoning steps can improve the performance of LLMs for complex reasoning tasks, such as math problems and symbolic question-answering tasks. However, we notice the challenge that LLMs face when it comes to temporal reasoning. Our preliminary experiments show that generating intermediate reasoning steps does not always boost the performance of complex temporal question-answering tasks. Therefore, we propose a novel framework that combines the extraction capability of LLMs and the logical reasoning capability of a Python solver to tackle this issue. Extensive experiments and analysis demonstrate the effectiveness of our framework in handling intricate time-bound reasoning tasks.
Revisiting DocRED -- Addressing the Overlooked False Negative Problem in Relation Extraction
May 25, 2022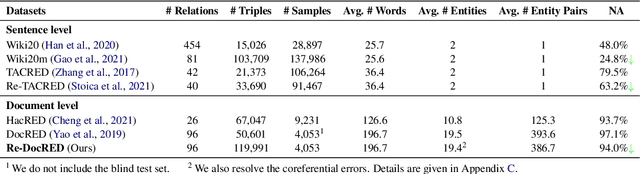
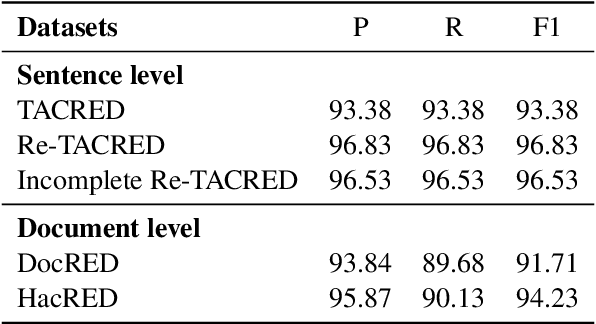
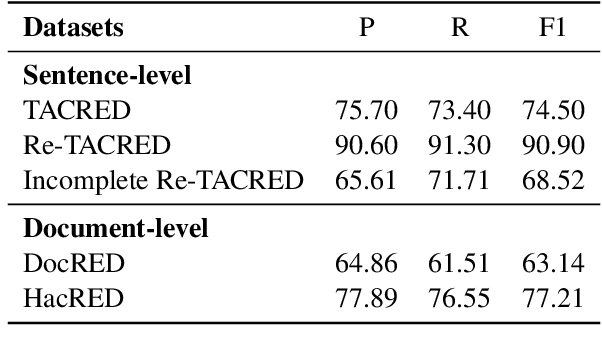
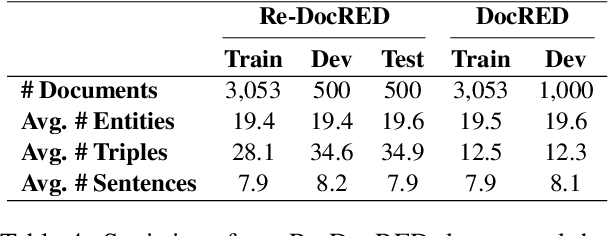
The DocRED dataset is one of the most popular and widely used benchmarks for document-level relation extraction (RE). It adopts a recommend-revise annotation scheme so as to have a large-scale annotated dataset. However, we find that the annotation of DocRED is incomplete, i.e., the false negative samples are prevalent. We analyze the causes and effects of the overwhelming false negative problem in the DocRED dataset. To address the shortcoming, we re-annotate 4,053 documents in the DocRED dataset by adding the missed relation triples back to the original DocRED. We name our revised DocRED dataset Re-DocRED. We conduct extensive experiments with state-of-the-art neural models on both datasets, and the experimental results show that the models trained and evaluated on our Re-DocRED achieve performance improvements of around 13 F1 points. Moreover, we propose different metrics to comprehensively evaluate the document-level RE task. We make our data publicly available at https://github.com/tonytan48/Re-DocRED.
Document-Level Relation Extraction with Adaptive Focal Loss and Knowledge Distillation
Mar 21, 2022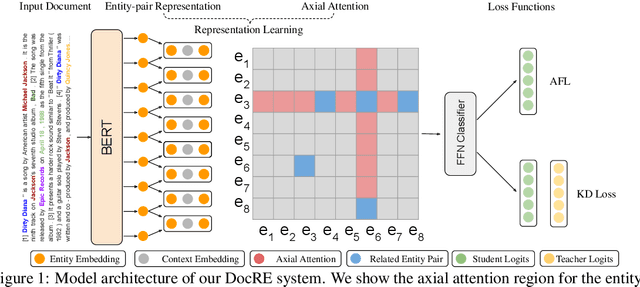
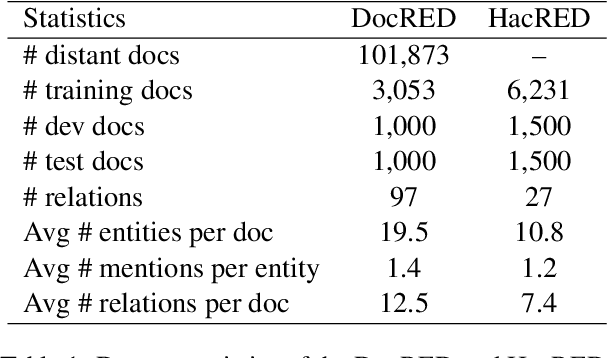
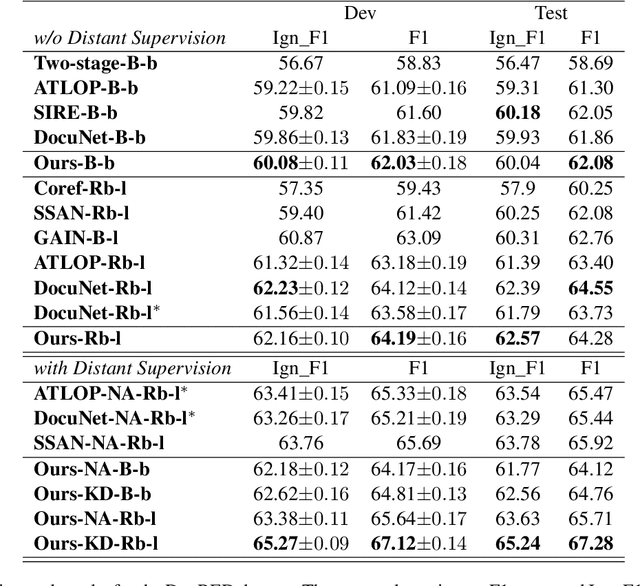
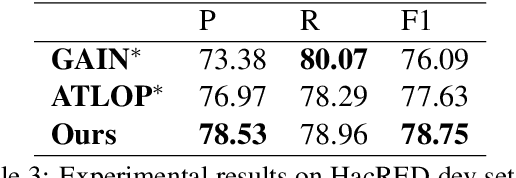
Document-level Relation Extraction (DocRE) is a more challenging task compared to its sentence-level counterpart. It aims to extract relations from multiple sentences at once. In this paper, we propose a semi-supervised framework for DocRE with three novel components. Firstly, we use an axial attention module for learning the interdependency among entity-pairs, which improves the performance on two-hop relations. Secondly, we propose an adaptive focal loss to tackle the class imbalance problem of DocRE. Lastly, we use knowledge distillation to overcome the differences between human annotated data and distantly supervised data. We conducted experiments on two DocRE datasets. Our model consistently outperforms strong baselines and its performance exceeds the previous SOTA by 1.36 F1 and 1.46 Ign_F1 score on the DocRED leaderboard. Our code and data will be released at https://github.com/tonytan48/KD-DocRE.
On the Effectiveness of Adapter-based Tuning for Pretrained Language Model Adaptation
Jun 06, 2021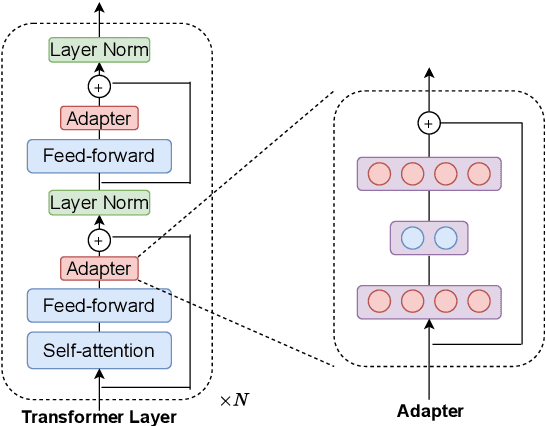
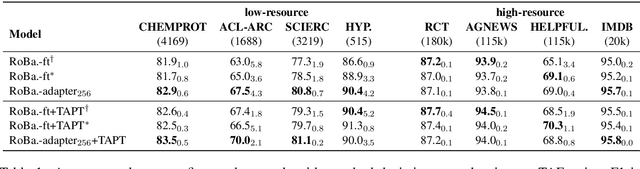
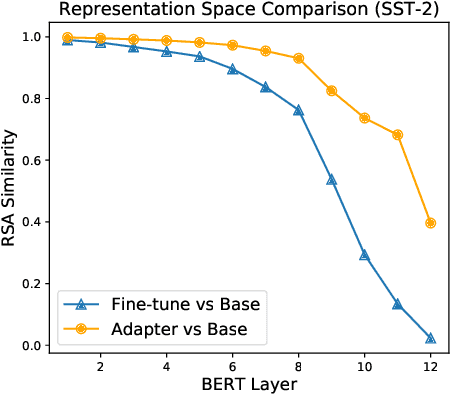
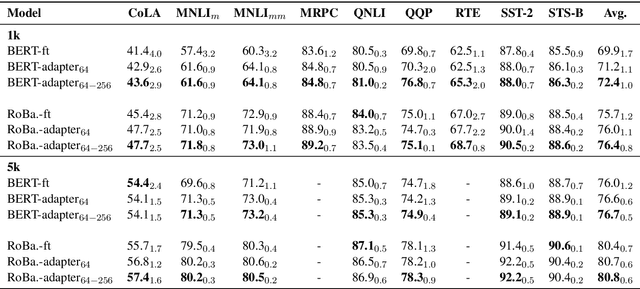
Adapter-based tuning has recently arisen as an alternative to fine-tuning. It works by adding light-weight adapter modules to a pretrained language model (PrLM) and only updating the parameters of adapter modules when learning on a downstream task. As such, it adds only a few trainable parameters per new task, allowing a high degree of parameter sharing. Prior studies have shown that adapter-based tuning often achieves comparable results to fine-tuning. However, existing work only focuses on the parameter-efficient aspect of adapter-based tuning while lacking further investigation on its effectiveness. In this paper, we study the latter. We first show that adapter-based tuning better mitigates forgetting issues than fine-tuning since it yields representations with less deviation from those generated by the initial PrLM. We then empirically compare the two tuning methods on several downstream NLP tasks and settings. We demonstrate that 1) adapter-based tuning outperforms fine-tuning on low-resource and cross-lingual tasks; 2) it is more robust to overfitting and less sensitive to changes in learning rates.
Feature Adaptation of Pre-Trained Language Models across Languages and Domains with Robust Self-Training
Oct 06, 2020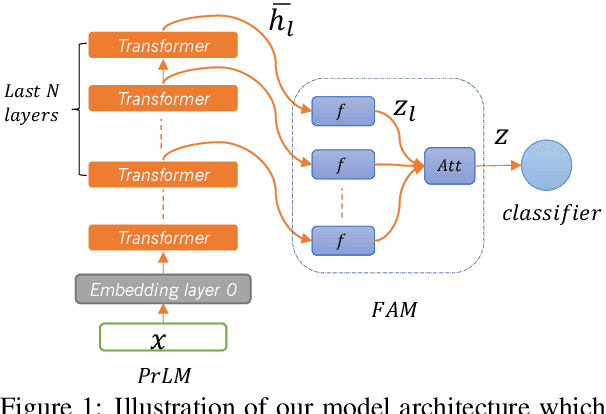
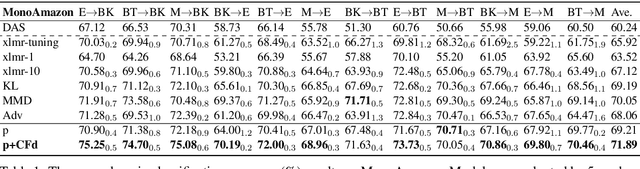
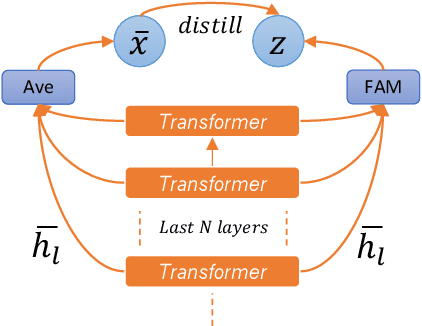

Adapting pre-trained language models (PrLMs) (e.g., BERT) to new domains has gained much attention recently. Instead of fine-tuning PrLMs as done in most previous work, we investigate how to adapt the features of PrLMs to new domains without fine-tuning. We explore unsupervised domain adaptation (UDA) in this paper. With the features from PrLMs, we adapt the models trained with labeled data from the source domain to the unlabeled target domain. Self-training is widely used for UDA which predicts pseudo labels on the target domain data for training. However, the predicted pseudo labels inevitably include noise, which will negatively affect training a robust model. To improve the robustness of self-training, in this paper we present class-aware feature self-distillation (CFd) to learn discriminative features from PrLMs, in which PrLM features are self-distilled into a feature adaptation module and the features from the same class are more tightly clustered. We further extend CFd to a cross-language setting, in which language discrepancy is studied. Experiments on two monolingual and multilingual Amazon review datasets show that CFd can consistently improve the performance of self-training in cross-domain and cross-language settings.