 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIAM: A Comprehensive and Large-Scale Dataset for Integrated Argument Mining Tasks
Mar 24, 2022

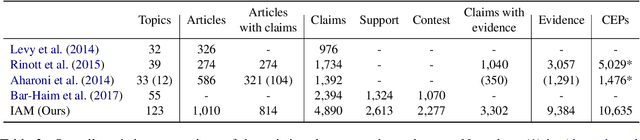
Traditionally, a debate usually requires a manual preparation process, including reading plenty of articles, selecting the claims, identifying the stances of the claims, seeking the evidence for the claims, etc. As the AI debate attracts more attention these years, it is worth exploring the methods to automate the tedious process involved in the debating system. In this work, we introduce a comprehensive and large dataset named IAM, which can be applied to a series of argument mining tasks, including claim extraction, stance classification, evidence extraction, etc. Our dataset is collected from over 1k articles related to 123 topics. Near 70k sentences in the dataset are fully annotated based on their argument properties (e.g., claims, stances, evidence, etc.). We further propose two new integrated argument mining tasks associated with the debate preparation process: (1) claim extraction with stance classification (CESC) and (2) claim-evidence pair extraction (CEPE). We adopt a pipeline approach and an end-to-end method for each integrated task separately. Promising experimental results are reported to show the values and challenges of our proposed tasks, and motivate future research on argument mining.
Document-Level Relation Extraction with Adaptive Focal Loss and Knowledge Distillation
Mar 21, 2022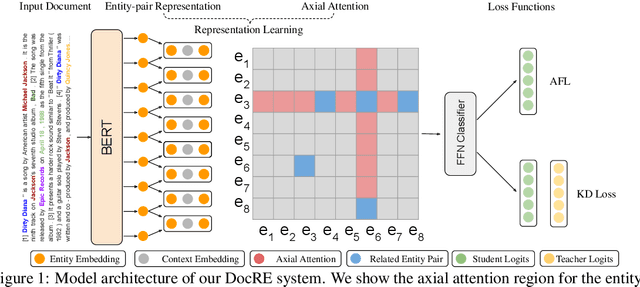
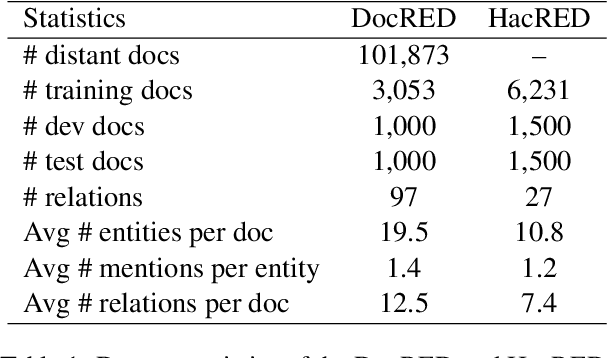
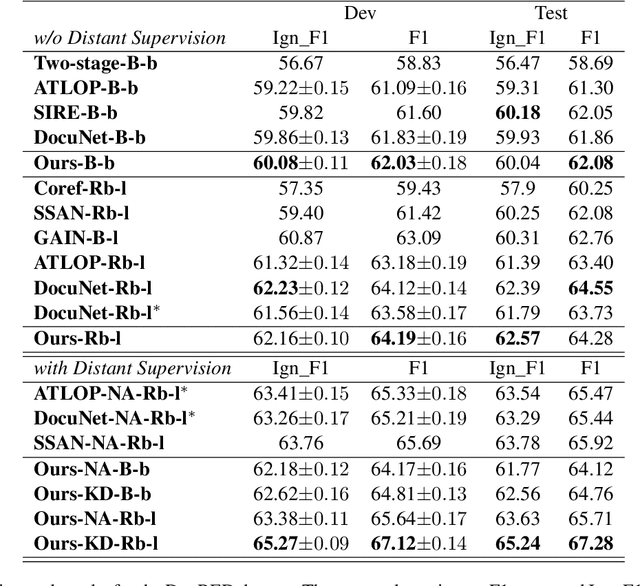
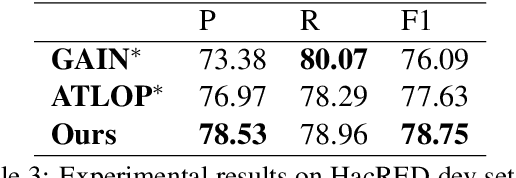
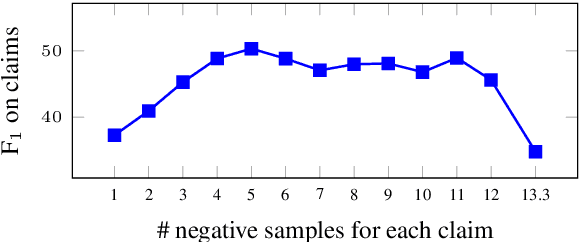
Document-level Relation Extraction (DocRE) is a more challenging task compared to its sentence-level counterpart. It aims to extract relations from multiple sentences at once. In this paper, we propose a semi-supervised framework for DocRE with three novel components. Firstly, we use an axial attention module for learning the interdependency among entity-pairs, which improves the performance on two-hop relations. Secondly, we propose an adaptive focal loss to tackle the class imbalance problem of DocRE. Lastly, we use knowledge distillation to overcome the differences between human annotated data and distantly supervised data. We conducted experiments on two DocRE datasets. Our model consistently outperforms strong baselines and its performance exceeds the previous SOTA by 1.36 F1 and 1.46 Ign_F1 score on the DocRED leaderboard. Our code and data will be released at https://github.com/tonytan48/KD-DocRE.
Knowledge Based Multilingual Language Model
Nov 22, 2021
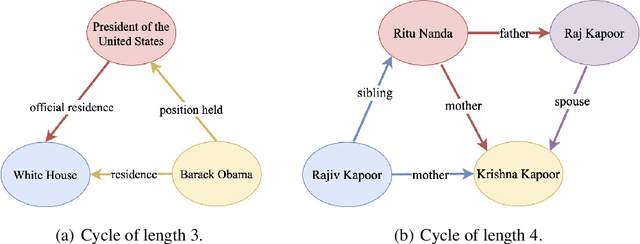
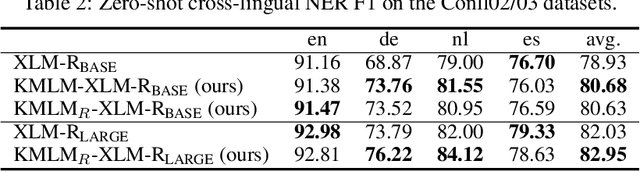
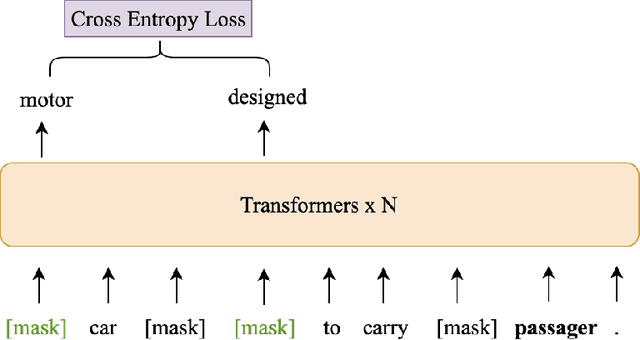
Knowledge enriched language representation learning has shown promising performance across various knowledge-intensive NLP tasks. However, existing knowledge based language models are all trained with monolingual knowledge graph data, which limits their application to more languages. In this work, we present a novel framework to pretrain knowledge based multilingual language models (KMLMs). We first generate a large amount of code-switched synthetic sentences and reasoning-based multilingual training data using the Wikidata knowledge graphs. Then based on the intra- and inter-sentence structures of the generated data, we design pretraining tasks to facilitate knowledge learning, which allows the language models to not only memorize the factual knowledge but also learn useful logical patterns. Our pretrained KMLMs demonstrate significant performance improvements on a wide range of knowledge-intensive cross-lingual NLP tasks, including named entity recognition, factual knowledge retrieval, relation classification, and a new task designed by us, namely, logic reasoning. Our code and pretrained language models will be made publicly available.
MELM: Data Augmentation with Masked Entity Language Modeling for Cross-lingual NER
Aug 31, 2021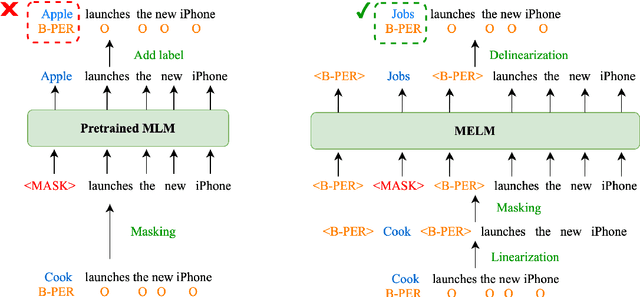
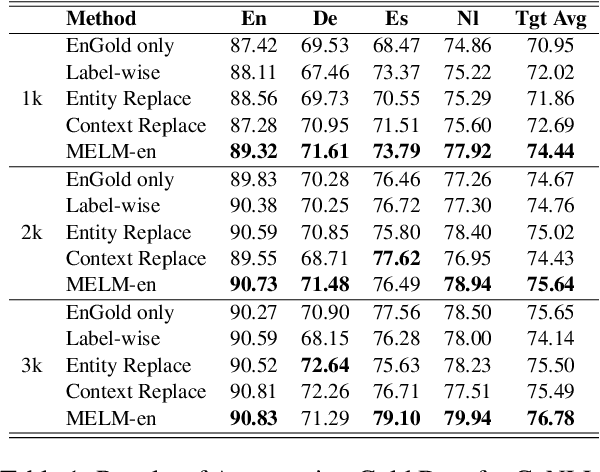
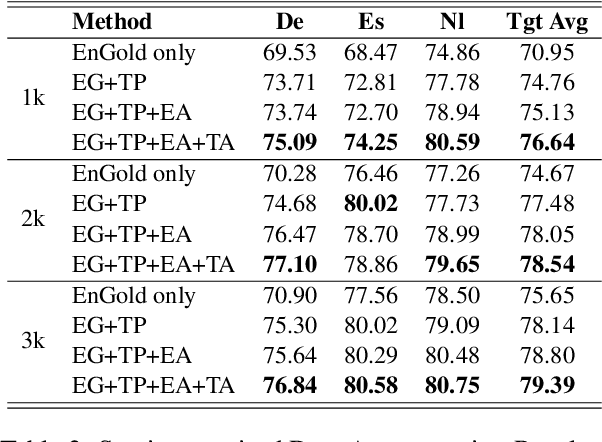

Data augmentation for cross-lingual NER requires fine-grained control over token labels of the augmented text. Existing augmentation approach based on masked language modeling may replace a labeled entity with words of a different class, which makes the augmented sentence incompatible with the original label sequence, and thus hurts the performance.We propose a data augmentation framework with Masked-Entity Language Modeling (MELM) which effectively ensures the replacing entities fit the original labels. Specifically, MELM linearizes NER labels into sentence context, and thus the fine-tuned MELM is able to predict masked tokens by explicitly conditioning on their labels. Our MELM is agnostic to the source of data to be augmented. Specifically, when MELM is applied to augment training data of the source language, it achieves up to 3.5% F1 score improvement for cross-lingual NER. When unlabeled target data is available and MELM can be further applied to augment pseudo-labeled target data, the performance gain reaches 5.7%. Moreover, MELM consistently outperforms multiple baseline methods for data augmentation.
On the Effectiveness of Adapter-based Tuning for Pretrained Language Model Adaptation
Jun 06, 2021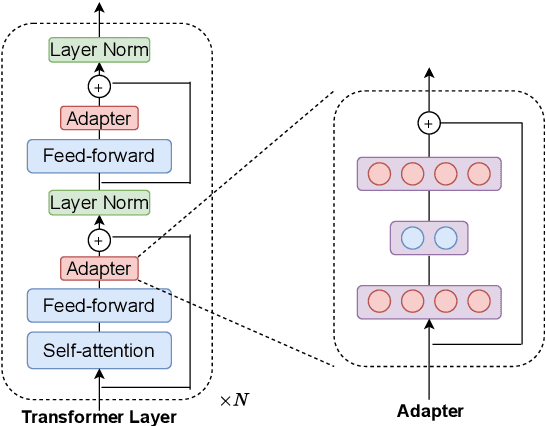
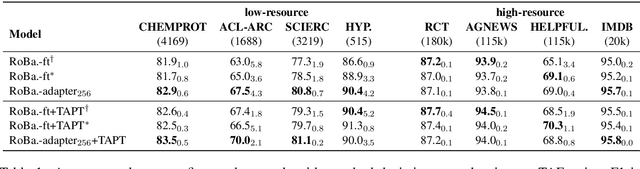
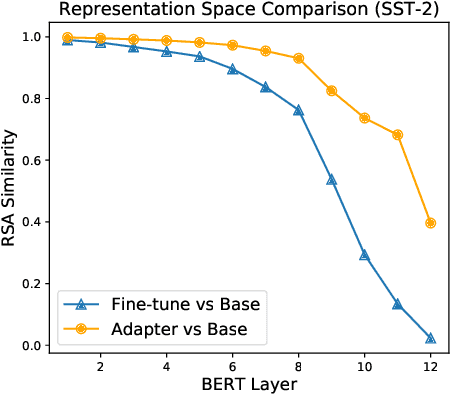
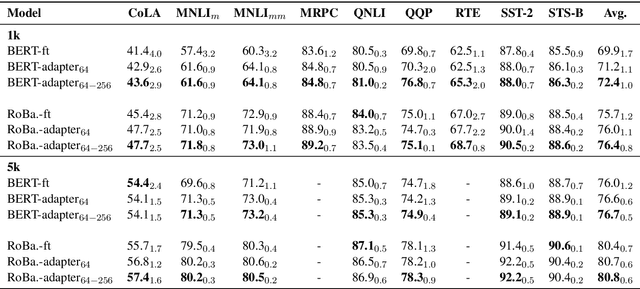
Adapter-based tuning has recently arisen as an alternative to fine-tuning. It works by adding light-weight adapter modules to a pretrained language model (PrLM) and only updating the parameters of adapter modules when learning on a downstream task. As such, it adds only a few trainable parameters per new task, allowing a high degree of parameter sharing. Prior studies have shown that adapter-based tuning often achieves comparable results to fine-tuning. However, existing work only focuses on the parameter-efficient aspect of adapter-based tuning while lacking further investigation on its effectiveness. In this paper, we study the latter. We first show that adapter-based tuning better mitigates forgetting issues than fine-tuning since it yields representations with less deviation from those generated by the initial PrLM. We then empirically compare the two tuning methods on several downstream NLP tasks and settings. We demonstrate that 1) adapter-based tuning outperforms fine-tuning on low-resource and cross-lingual tasks; 2) it is more robust to overfitting and less sensitive to changes in learning rates.
Unsupervised Domain Adaptation of a Pretrained Cross-Lingual Language Model
Nov 23, 2020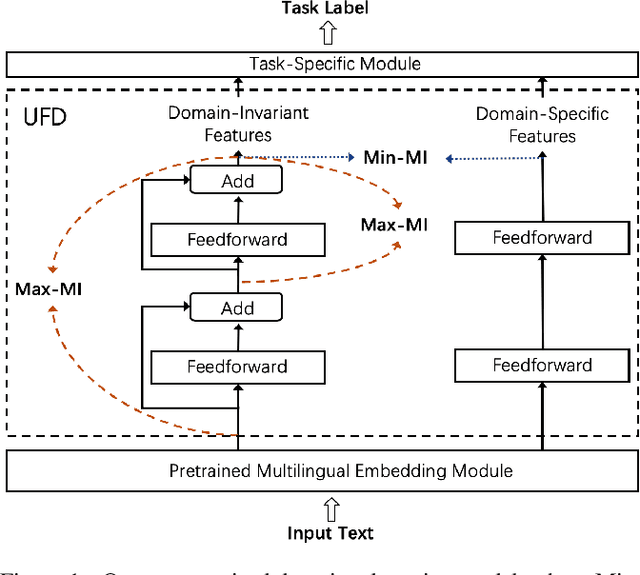



Recent research indicates that pretraining cross-lingual language models on large-scale unlabeled texts yields significant performance improvements over various cross-lingual and low-resource tasks. Through training on one hundred languages and terabytes of texts, cross-lingual language models have proven to be effective in leveraging high-resource languages to enhance low-resource language processing and outperform monolingual models. In this paper, we further investigate the cross-lingual and cross-domain (CLCD) setting when a pretrained cross-lingual language model needs to adapt to new domains. Specifically, we propose a novel unsupervised feature decomposition method that can automatically extract domain-specific features and domain-invariant features from the entangled pretrained cross-lingual representations, given unlabeled raw texts in the source language. Our proposed model leverages mutual information estimation to decompose the representations computed by a cross-lingual model into domain-invariant and domain-specific parts. Experimental results show that our proposed method achieves significant performance improvements over the state-of-the-art pretrained cross-lingual language model in the CLCD setting. The source code of this paper is publicly available at https://github.com/lijuntaopku/UFD.
Feature Adaptation of Pre-Trained Language Models across Languages and Domains with Robust Self-Training
Oct 06, 2020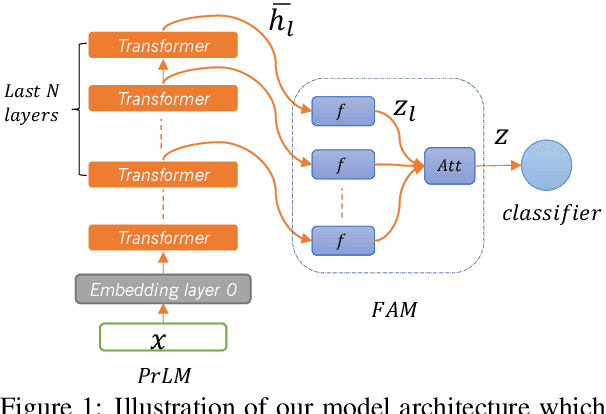
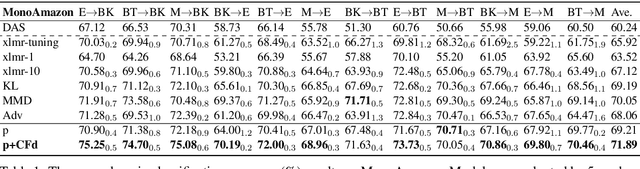
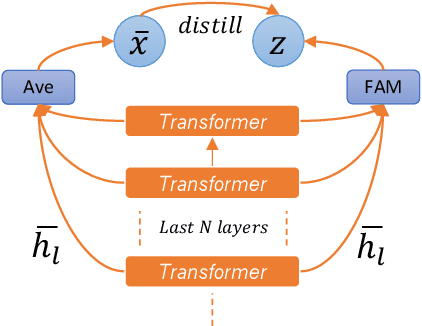

Adapting pre-trained language models (PrLMs) (e.g., BERT) to new domains has gained much attention recently. Instead of fine-tuning PrLMs as done in most previous work, we investigate how to adapt the features of PrLMs to new domains without fine-tuning. We explore unsupervised domain adaptation (UDA) in this paper. With the features from PrLMs, we adapt the models trained with labeled data from the source domain to the unlabeled target domain. Self-training is widely used for UDA which predicts pseudo labels on the target domain data for training. However, the predicted pseudo labels inevitably include noise, which will negatively affect training a robust model. To improve the robustness of self-training, in this paper we present class-aware feature self-distillation (CFd) to learn discriminative features from PrLMs, in which PrLM features are self-distilled into a feature adaptation module and the features from the same class are more tightly clustered. We further extend CFd to a cross-language setting, in which language discrepancy is studied. Experiments on two monolingual and multilingual Amazon review datasets show that CFd can consistently improve the performance of self-training in cross-domain and cross-language settings.
An Unsupervised Sentence Embedding Method byMutual Information Maximization
Sep 25, 2020
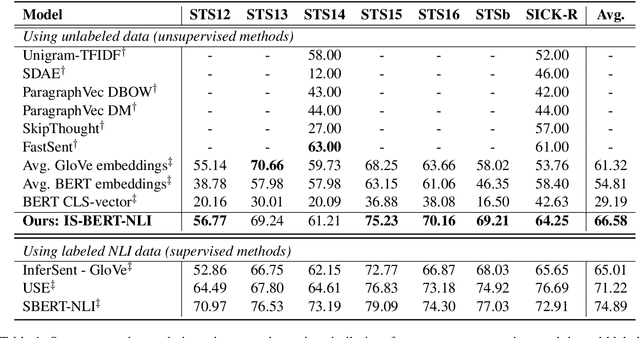

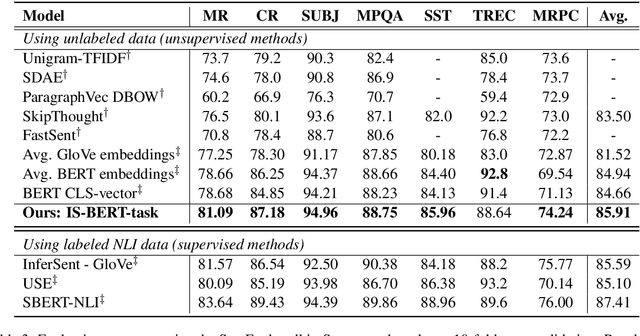
BERT is inefficient for sentence-pair tasks such as clustering or semantic search as it needs to evaluate combinatorially many sentence pairs which is very time-consuming. Sentence BERT (SBERT) attempted to solve this challenge by learning semantically meaningful representations of single sentences, such that similarity comparison can be easily accessed. However, SBERT is trained on corpus with high-quality labeled sentence pairs, which limits its application to tasks where labeled data is extremely scarce. In this paper, we propose a lightweight extension on top of BERT and a novel self-supervised learning objective based on mutual information maximization strategies to derive meaningful sentence embeddings in an unsupervised manner. Unlike SBERT, our method is not restricted by the availability of labeled data, such that it can be applied on different domain-specific corpus. Experimental results show that the proposed method significantly outperforms other unsupervised sentence embedding baselines on common semantic textual similarity (STS) tasks and downstream supervised tasks. It also outperforms SBERT in a setting where in-domain labeled data is not available, and achieves performance competitive with supervised methods on various tasks.
An Interactive Multi-Task Learning Network for End-to-End Aspect-Based Sentiment Analysis
Jun 17, 2019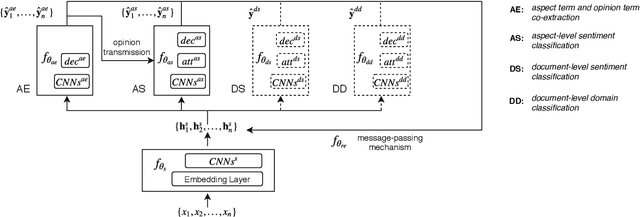

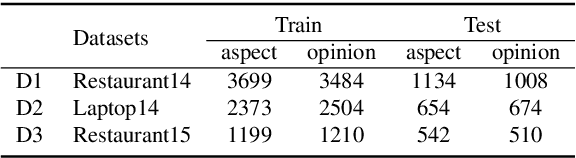
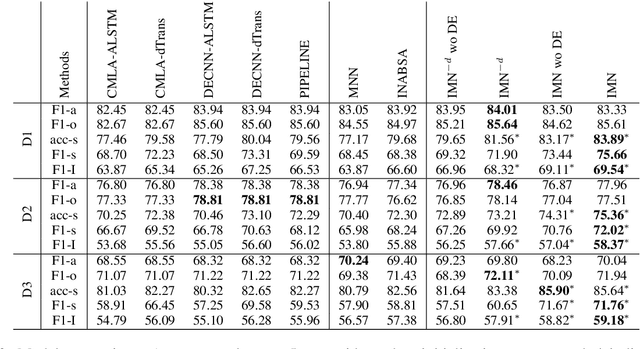
Aspect-based sentiment analysis produces a list of aspect terms and their corresponding sentiments for a natural language sentence. This task is usually done in a pipeline manner, with aspect term extraction performed first, followed by sentiment predictions toward the extracted aspect terms. While easier to develop, such an approach does not fully exploit joint information from the two subtasks and does not use all available sources of training information that might be helpful, such as document-level labeled sentiment corpus. In this paper, we propose an interactive multi-task learning network (IMN) which is able to jointly learn multiple related tasks simultaneously at both the token level as well as the document level. Unlike conventional multi-task learning methods that rely on learning common features for the different tasks, IMN introduces a message passing architecture where information is iteratively passed to different tasks through a shared set of latent variables. Experimental results demonstrate superior performance of the proposed method against multiple baselines on three benchmark datasets.
Adaptive Semi-supervised Learning for Cross-domain Sentiment Classification
Sep 03, 2018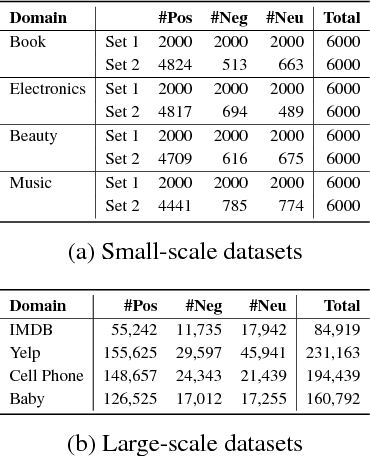
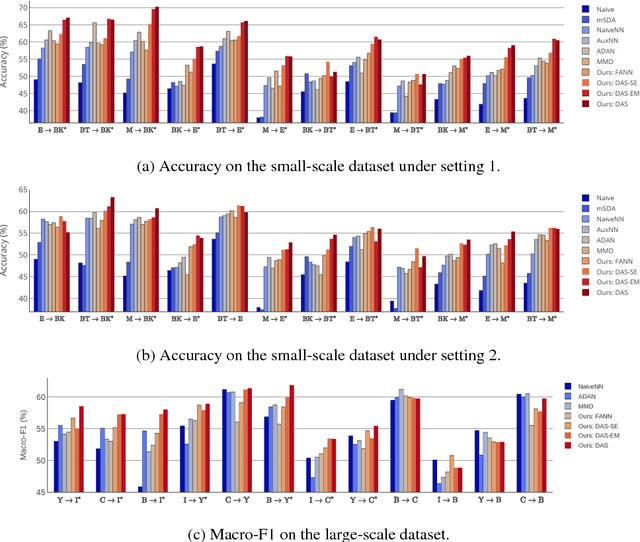
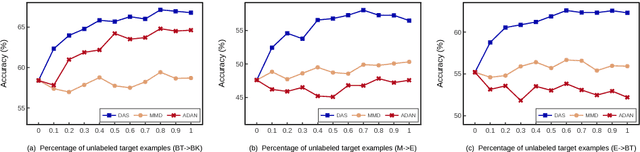
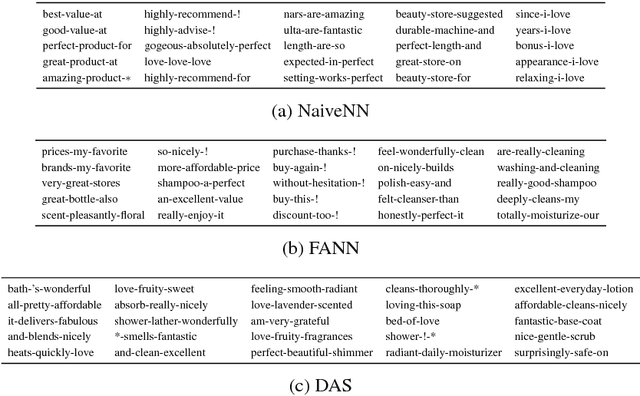
We consider the cross-domain sentiment classification problem, where a sentiment classifier is to be learned from a source domain and to be generalized to a target domain. Our approach explicitly minimizes the distance between the source and the target instances in an embedded feature space. With the difference between source and target minimized, we then exploit additional information from the target domain by consolidating the idea of semi-supervised learning, for which, we jointly employ two regularizations -- entropy minimization and self-ensemble bootstrapping -- to incorporate the unlabeled target data for classifier refinement. Our experimental results demonstrate that the proposed approach can better leverage unlabeled data from the target domain and achieve substantial improvements over baseline methods in various experimental settings.