 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Adapter-based Tuning for Pretrained Language Model Adaptation
Jun 06, 2021
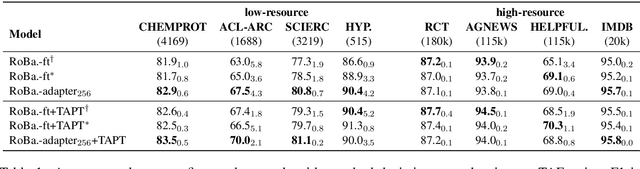
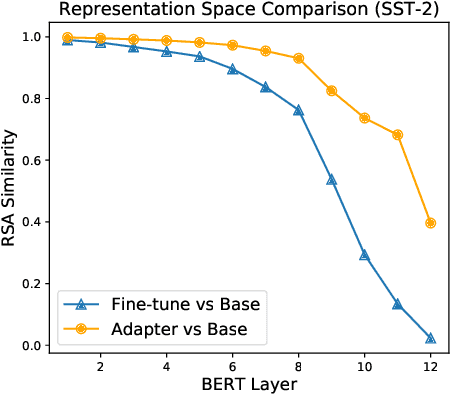
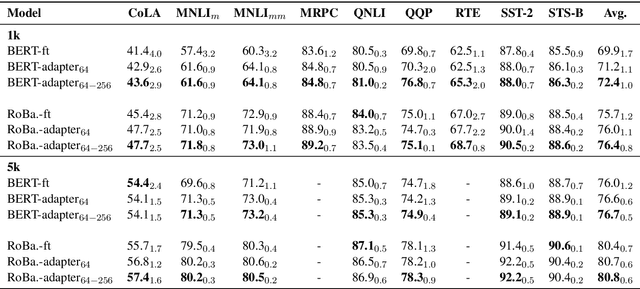
Adapter-based tuning has recently arisen as an alternative to fine-tuning. It works by adding light-weight adapter modules to a pretrained language model (PrLM) and only updating the parameters of adapter modules when learning on a downstream task. As such, it adds only a few trainable parameters per new task, allowing a high degree of parameter sharing. Prior studies have shown that adapter-based tuning often achieves comparable results to fine-tuning. However, existing work only focuses on the parameter-efficient aspect of adapter-based tuning while lacking further investigation on its effectiveness. In this paper, we study the latter. We first show that adapter-based tuning better mitigates forgetting issues than fine-tuning since it yields representations with less deviation from those generated by the initial PrLM. We then empirically compare the two tuning methods on several downstream NLP tasks and settings. We demonstrate that 1) adapter-based tuning outperforms fine-tuning on low-resource and cross-lingual tasks; 2) it is more robust to overfitting and less sensitive to changes in learning rates.
Collective Semi-Supervised Learning for User Profiling in Social Media
Jun 24, 2016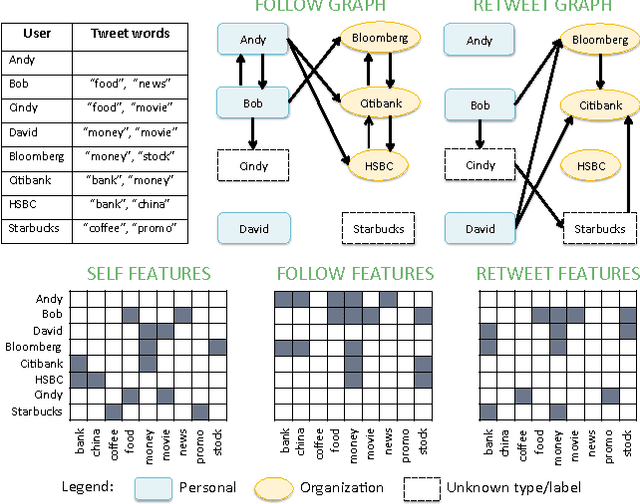

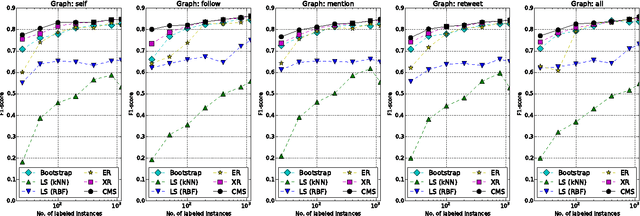
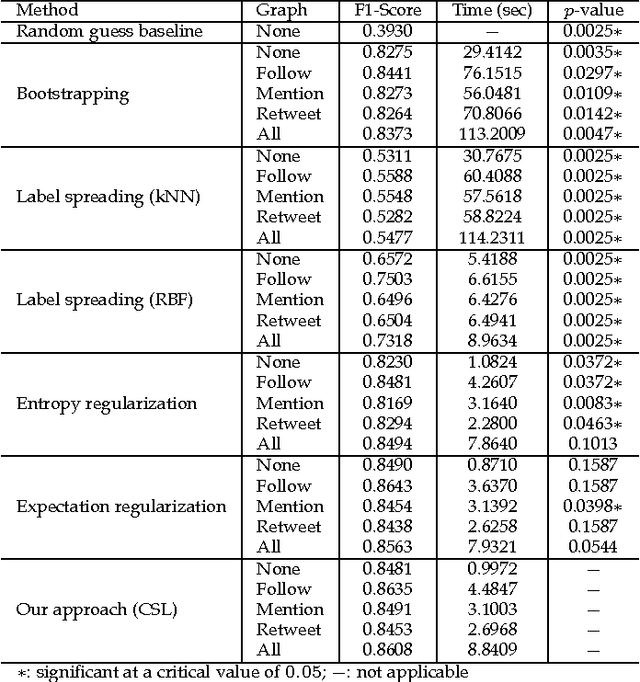
The abundance of user-generated data in social media has incentivized the development of methods to infer the latent attributes of users, which are crucially useful for personalization, advertising and recommendation. However, the current user profiling approaches have limited success, due to the lack of a principled way to integrate different types of social relationships of a user, and the reliance on scarcely-available labeled data in building a prediction model. In this paper, we present a novel solution termed Collective Semi-Supervised Learning (CSL), which provides a principled means to integrate different types of social relationship and unlabeled data under a unified computational framework. The joint learning from multiple relationships and unlabeled data yields a computationally sound and accurate approach to model user attributes in social media. Extensive experiments using Twitter data have demonstrated the efficacy of our CSL approach in inferring user attributes such as account type and marital status. We also show how CSL can be used to determine important user features, and to make inference on a larger user population.