 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeen2Act: Activity Recommendation in Online Social Collaborative Platforms
May 11, 2020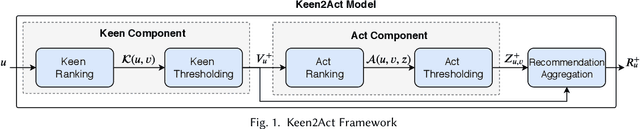
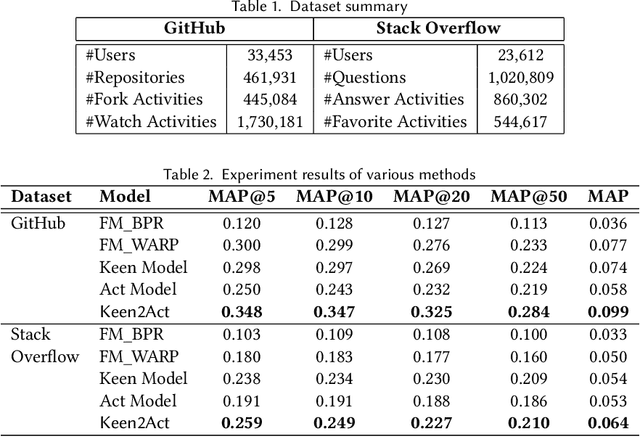
Social collaborative platforms such as GitHub and Stack Overflow have been increasingly used to improve work productivity via collaborative efforts. To improve user experiences in these platforms, it is desirable to have a recommender system that can suggest not only items (e.g., a GitHub repository) to a user, but also activities to be performed on the suggested items (e.g., forking a repository). To this end, we propose a new approach dubbed Keen2Act, which decomposes the recommendation problem into two stages: the Keen and Act steps. The Keen step identifies, for a given user, a (sub)set of items in which he/she is likely to be interested. The Act step then recommends to the user which activities to perform on the identified set of items. This decomposition provides a practical approach to tackling complex activity recommendation tasks while producing higher recommendation quality. We evaluate our proposed approach using two real-world datasets and obtain promising results whereby Keen2Act outperforms several baseline models.
PatchNet: A Tool for Deep Patch Classification
Mar 26, 2019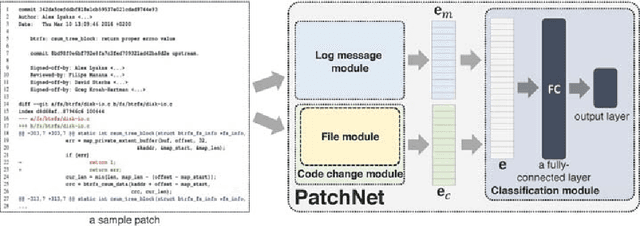
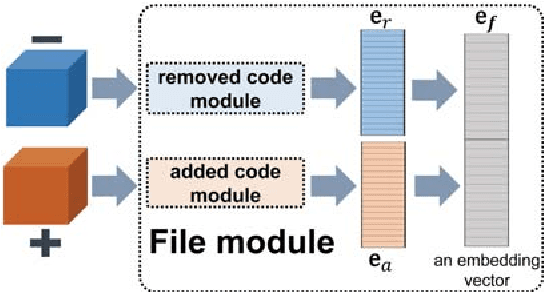
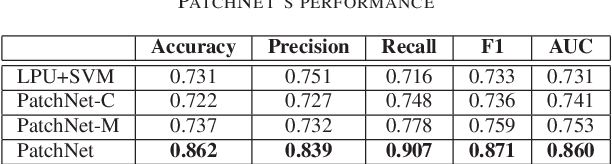
This work proposes PatchNet, an automated tool based on hierarchical deep learning for classifying patches by extracting features from commit messages and code changes. PatchNet contains a deep hierarchical structure that mirrors the hierarchical and sequential structure of a code change, differentiating it from the existing deep learning models on source code. PatchNet provides several options allowing users to select parameters for the training process. The tool has been validated in the context of automatic identification of stable-relevant patches in the Linux kernel and is potentially applicable to automate other software engineering tasks that can be formulated as patch classification problems. A video demonstrating PatchNet is available at https://goo.gl/CZjG6X. The PatchNet implementation is available at https://github.com/hvdthong/PatchNetTool.
JobComposer: Career Path Optimization via Multicriteria Utility Learning
Sep 04, 2018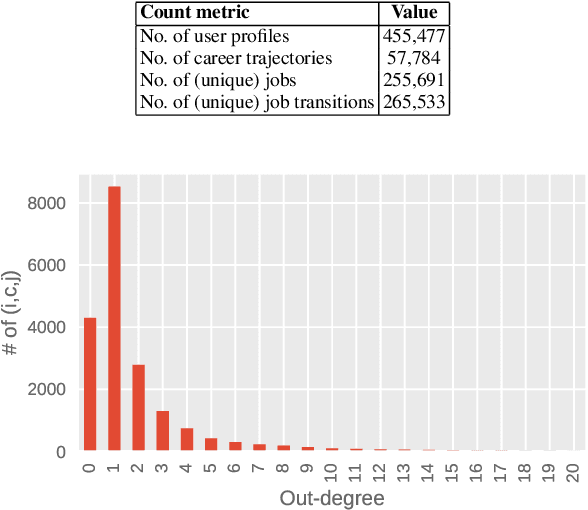
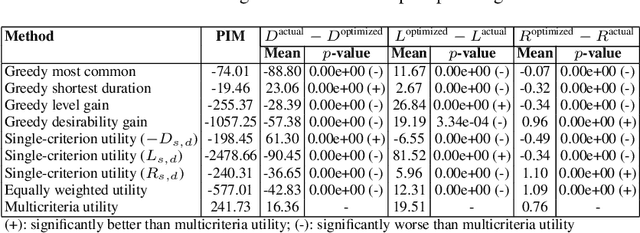
With online professional network platforms (OPNs, e.g., LinkedIn, Xing, etc.) becoming popular on the web, people are now turning to these platforms to create and share their professional profiles, to connect with others who share similar professional aspirations and to explore new career opportunities. These platforms however do not offer a long-term roadmap to guide career progression and improve workforce employability. The career trajectories of OPN users can serve as a reference but they are not always optimal. A career plan can also be devised through consultation with career coaches, whose knowledge may however be limited to a few industries. To address the above limitations, we present a novel data-driven approach dubbed JobComposer to automate career path planning and optimization. Its key premise is that the observed career trajectories in OPNs may not necessarily be optimal, and can be improved by learning to maximize the sum of payoffs attainable by following a career path. At its heart, JobComposer features a decomposition-based multicriteria utility learning procedure to achieve the best tradeoff among different payoff criteria in career path planning. Extensive studies using a city state-based OPN dataset demonstrate that JobComposer returns career paths better than other baseline methods and the actual career paths.
Network-Clustered Multi-Modal Bug Localization
Feb 27, 2018
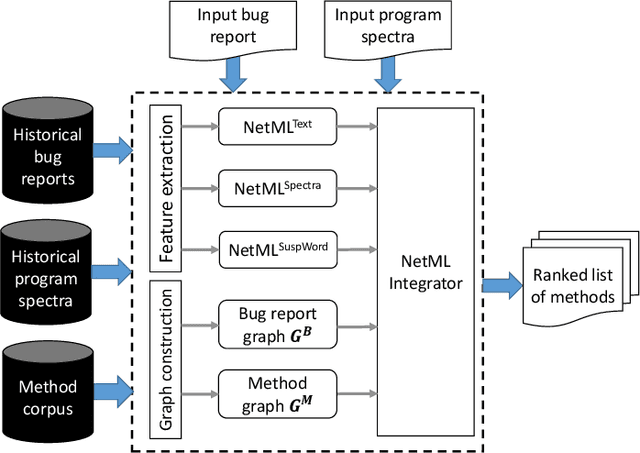
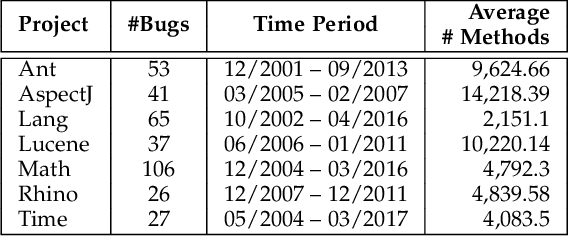
Developers often spend much effort and resources to debug a program. To help the developers debug, numerous information retrieval (IR)-based and spectrum-based bug localization techniques have been devised. IR-based techniques process textual information in bug reports, while spectrum-based techniques process program spectra (i.e., a record of which program elements are executed for each test case). While both techniques ultimately generate a ranked list of program elements that likely contain a bug, they only consider one source of information--either bug reports or program spectra--which is not optimal. In light of this deficiency, this paper presents a new approach dubbed Network-clustered Multi-modal Bug Localization (NetML), which utilizes multi-modal information from both bug reports and program spectra to localize bugs. NetML facilitates an effective bug localization by carrying out a joint optimization of bug localization error and clustering of both bug reports and program elements (i.e., methods). The clustering is achieved through the incorporation of network Lasso regularization, which incentivizes the model parameters of similar bug reports and similar program elements to be close together. To estimate the model parameters of both bug reports and methods, NetML employs an adaptive learning procedure based on Newton method that updates the parameters on a per-feature basis. Extensive experiments on 355 real bugs from seven software systems have been conducted to benchmark NetML against various state-of-the-art localization methods. The results show that NetML surpasses the best-performing baseline by 31.82%, 22.35%, 19.72%, and 19.24%, in terms of the number of bugs successfully localized when a developer inspects the top 1, 5, and 10 methods and Mean Average Precision (MAP), respectively.
Local Gaussian Processes for Efficient Fine-Grained Traffic Speed Prediction
Aug 27, 2017
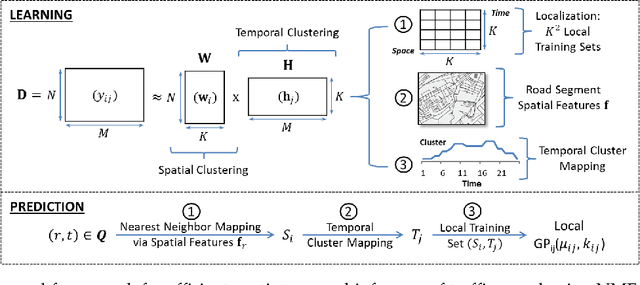
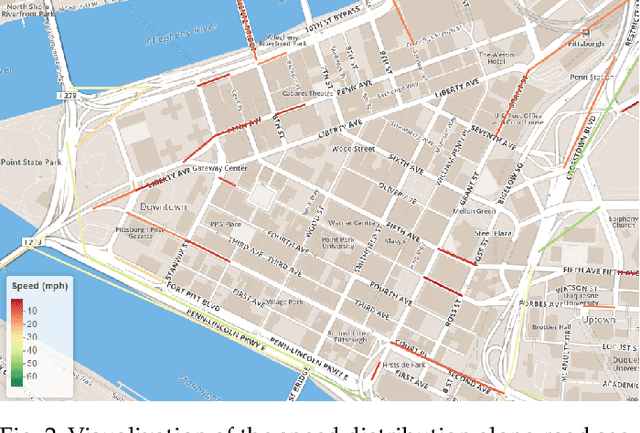

Traffic speed is a key indicator for the efficiency of an urban transportation system. Accurate modeling of the spatiotemporally varying traffic speed thus plays a crucial role in urban planning and development. This paper addresses the problem of efficient fine-grained traffic speed prediction using big traffic data obtained from static sensors. Gaussian processes (GPs) have been previously used to model various traffic phenomena, including flow and speed. However, GPs do not scale with big traffic data due to their cubic time complexity. In this work, we address their efficiency issues by proposing local GPs to learn from and make predictions for correlated subsets of data. The main idea is to quickly group speed variables in both spatial and temporal dimensions into a finite number of clusters, so that future and unobserved traffic speed queries can be heuristically mapped to one of such clusters. A local GP corresponding to that cluster can then be trained on the fly to make predictions in real-time. We call this method localization. We use non-negative matrix factorization for localization and propose simple heuristics for cluster mapping. We additionally leverage on the expressiveness of GP kernel functions to model road network topology and incorporate side information. Extensive experiments using real-world traffic data collected in the two U.S. cities of Pittsburgh and Washington, D.C., show that our proposed local GPs significantly improve both runtime performances and prediction accuracies compared to the baseline global and local GPs.
WebAPIRec: Recommending Web APIs to Software Projects via Personalized Ranking
May 01, 2017


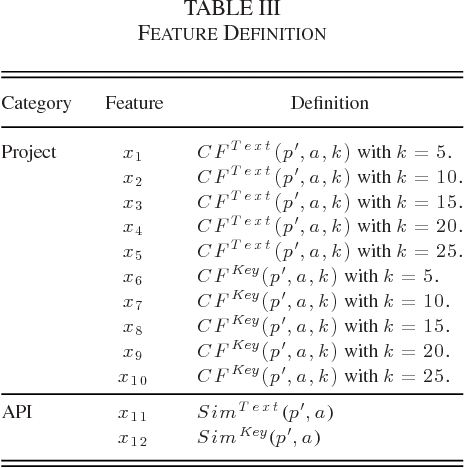
Application programming interfaces (APIs) offer a plethora of functionalities for developers to reuse without reinventing the wheel. Identifying the appropriate APIs given a project requirement is critical for the success of a project, as many functionalities can be reused to achieve faster development. However, the massive number of APIs would often hinder the developers' ability to quickly find the right APIs. In this light, we propose a new, automated approach called WebAPIRec that takes as input a project profile and outputs a ranked list of {web} APIs that can be used to implement the project. At its heart, WebAPIRec employs a personalized ranking model that ranks web APIs specific (personalized) to a project. Based on the historical data of {web} API usages, WebAPIRec learns a model that minimizes the incorrect ordering of web APIs, i.e., when a used {web} API is ranked lower than an unused (or a not-yet-used) web API. We have evaluated our approach on a dataset comprising 9,883 web APIs and 4,315 web application projects from ProgrammableWeb with promising results. For 84.0% of the projects, WebAPIRec is able to successfully return correct APIs that are used to implement the projects in the top-5 positions. This is substantially better than the recommendations provided by ProgrammableWeb's native search functionality. WebAPIRec also outperforms McMillan et al.'s application search engine and popularity-based recommendation.
* IEEE Transactions on Emerging Topics in Computational Intelligence, 2017
Collective Semi-Supervised Learning for User Profiling in Social Media
Jun 24, 2016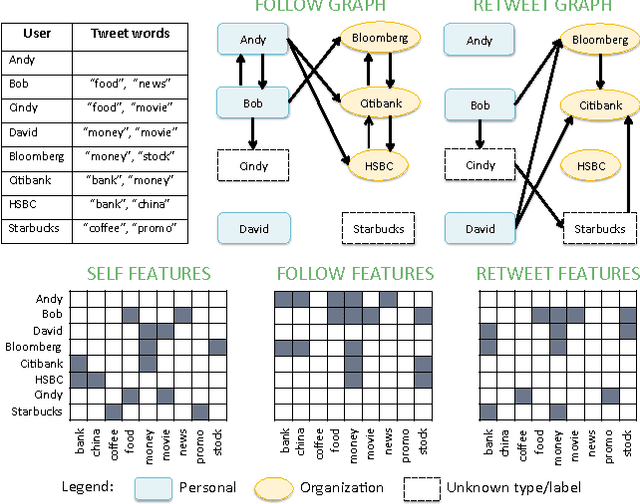

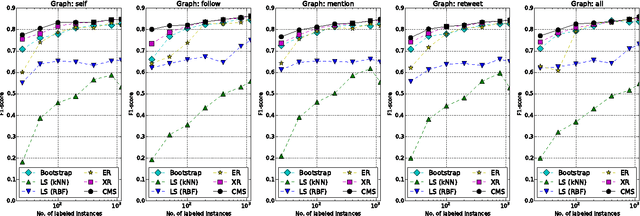
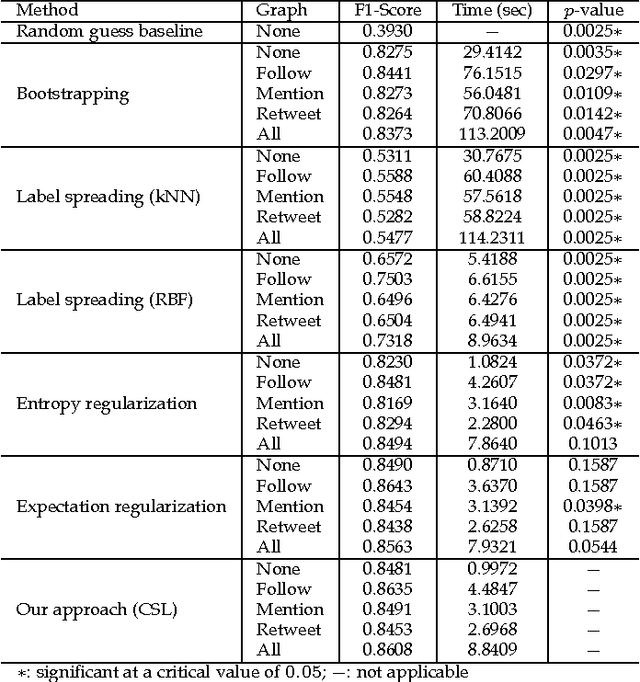
The abundance of user-generated data in social media has incentivized the development of methods to infer the latent attributes of users, which are crucially useful for personalization, advertising and recommendation. However, the current user profiling approaches have limited success, due to the lack of a principled way to integrate different types of social relationships of a user, and the reliance on scarcely-available labeled data in building a prediction model. In this paper, we present a novel solution termed Collective Semi-Supervised Learning (CSL), which provides a principled means to integrate different types of social relationship and unlabeled data under a unified computational framework. The joint learning from multiple relationships and unlabeled data yields a computationally sound and accurate approach to model user attributes in social media. Extensive experiments using Twitter data have demonstrated the efficacy of our CSL approach in inferring user attributes such as account type and marital status. We also show how CSL can be used to determine important user features, and to make inference on a larger user population.