 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Pretrained Models for API Learning
Apr 05, 2022
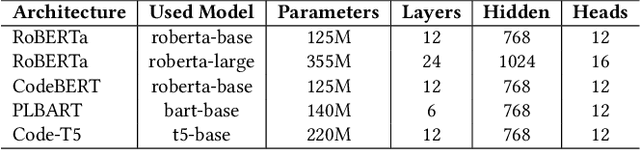


Developers frequently use APIs to implement certain functionalities, such as parsing Excel Files, reading and writing text files line by line, etc. Developers can greatly benefit from automatic API usage sequence generation based on natural language queries for building applications in a faster and cleaner manner. Existing approaches utilize information retrieval models to search for matching API sequences given a query or use RNN-based encoder-decoder to generate API sequences. As it stands, the first approach treats queries and API names as bags of words. It lacks deep comprehension of the semantics of the queries. The latter approach adapts a neural language model to encode a user query into a fixed-length context vector and generate API sequences from the context vector. We want to understand the effectiveness of recent Pre-trained Transformer based Models (PTMs) for the API learning task. These PTMs are trained on large natural language corpora in an unsupervised manner to retain contextual knowledge about the language and have found success in solving similar Natural Language Processing (NLP) problems. However, the applicability of PTMs has not yet been explored for the API sequence generation task. We use a dataset that contains 7 million annotations collected from GitHub to evaluate the PTMs empirically. This dataset was also used to assess previous approaches. Based on our results, PTMs generate more accurate API sequences and outperform other related methods by around 11%. We have also identified two different tokenization approaches that can contribute to a significant boost in PTMs' performance for the API sequence generation task.
* 12 pages, 4 figures, ICPC 2022
FACOS: Finding API Relevant Contents on Stack Overflow with Semantic and Syntactic Analysis
Nov 14, 2021



Collecting API examples, usages, and mentions relevant to a specific API method over discussions on venues such as Stack Overflow is not a trivial problem. It requires efforts to correctly recognize whether the discussion refers to the API method that developers/tools are searching for. The content of the thread, which consists of both text paragraphs describing the involvement of the API method in the discussion and the code snippets containing the API invocation, may refer to the given API method. Leveraging this observation, we develop FACOS, a context-specific algorithm to capture the semantic and syntactic information of the paragraphs and code snippets in a discussion. FACOS combines a syntactic word-based score with a score from a predictive model fine-tuned from CodeBERT. FACOS beats the state-of-the-art approach by 13.9% in terms of F1-score.
WebAPIRec: Recommending Web APIs to Software Projects via Personalized Ranking
May 01, 2017


Application programming interfaces (APIs) offer a plethora of functionalities for developers to reuse without reinventing the wheel. Identifying the appropriate APIs given a project requirement is critical for the success of a project, as many functionalities can be reused to achieve faster development. However, the massive number of APIs would often hinder the developers' ability to quickly find the right APIs. In this light, we propose a new, automated approach called WebAPIRec that takes as input a project profile and outputs a ranked list of {web} APIs that can be used to implement the project. At its heart, WebAPIRec employs a personalized ranking model that ranks web APIs specific (personalized) to a project. Based on the historical data of {web} API usages, WebAPIRec learns a model that minimizes the incorrect ordering of web APIs, i.e., when a used {web} API is ranked lower than an unused (or a not-yet-used) web API. We have evaluated our approach on a dataset comprising 9,883 web APIs and 4,315 web application projects from ProgrammableWeb with promising results. For 84.0% of the projects, WebAPIRec is able to successfully return correct APIs that are used to implement the projects in the top-5 positions. This is substantially better than the recommendations provided by ProgrammableWeb's native search functionality. WebAPIRec also outperforms McMillan et al.'s application search engine and popularity-based recommendation.
* IEEE Transactions on Emerging Topics in Computational Intelligence, 2017