 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARISE: A Repository-level Graph Representation and Toolset for Agentic Fault Localization and Program Repair
May 04, 2026Repository-level fault localization (FL) and automated program repair (APR) require an agent to identify the relevant code units across files, follow call and data dependencies, and generate a valid patch. Existing graph-based systems provide structural representations of repositories (files, classes, functions and their relationships) but do not model how variable values flow within procedures, leaving agents without the semantic precision needed for function- and line-level localization. We present ARISE (Agentic Repository-level Issue Solving Engine), which augments an LLM-based agent with a multi-granularity program graph that extends structural relationships down to statement-level nodes connected by intra-procedural definition-use edges. ARISE exposes this graph through a three-tier tool API, which brings data-flow slicing as a first-class, queryable agent primitive that allows the model to trace, in a single call, which statements define or consume a variable of interest. We evaluate on SWE-bench Lite (300 real GitHub issues, 11 Python repositories) using Qwen2.5-Coder-32B-Instruct as the backbone. Compared to the unmodified SWE-agent baseline, ARISE improves Function Recall@1 by 17.0 points and Line Recall@1 by 15.0 points. These localization gains translate directly into repair success, with ARISE achieving 22.0% Pass@1 (66/300), a 4.7 percentage-point improvement over SWE-agent. Controlled ablations confirm that the improvement is driven by the data-flow graph rather than the tool schema, and that large code models consume structured slice output directly without requiring a natural-language summarization layer. The graph builder and slicing API are designed as a framework-agnostic, drop-in toolset for future APR research.
Context-Augmented Code Generation Using Programming Knowledge Graphs
Jan 28, 2026Large Language Models (LLMs) excel at code generation but struggle with complex problems. Retrieval-Augmented Generation (RAG) mitigates this issue by integrating external knowledge, yet retrieval models often miss relevant context, and generation models hallucinate with irrelevant data. We propose Programming Knowledge Graph (PKG) for semantic representation and fine-grained retrieval of code and text. Our approach enhances retrieval precision through tree pruning and mitigates hallucinations via a re-ranking mechanism that integrates non-RAG solutions. Structuring external data into finer-grained nodes improves retrieval granularity. Evaluations on HumanEval and MBPP show up to 20% pass@1 accuracy gains and a 34% improvement over baselines on MBPP. Our findings demonstrate that our proposed PKG approach along with re-ranker effectively address complex problems while maintaining minimal negative impact on solutions that are already correct without RAG. The replication package is published at https://github.com/iamshahd/ProgrammingKnowledgeGraph
APIContext2Com: Code Comment Generation by Incorporating Pre-Defined API Documentation
Mar 03, 2023Code comments are significantly helpful in comprehending software programs and also aid developers to save a great deal of time in software maintenance. Code comment generation aims to automatically predict comments in natural language given a code snippet. Several works investigate the effect of integrating external knowledge on the quality of generated comments. In this study, we propose a solution, namely APIContext2Com, to improve the effectiveness of generated comments by incorporating the pre-defined Application Programming Interface (API) context. The API context includes the definition and description of the pre-defined APIs that are used within the code snippets. As the detailed API information expresses the functionality of a code snippet, it can be helpful in better generating the code summary. We introduce a seq-2-seq encoder-decoder neural network model with different sets of multiple encoders to effectively transform distinct inputs into target comments. A ranking mechanism is also developed to exclude non-informative APIs, so that we can filter out unrelated APIs. We evaluate our approach using the Java dataset from CodeSearchNet. The findings reveal that the proposed model improves the best baseline by 1.88 (8.24 %), 2.16 (17.58 %), 1.38 (18.3 %), 0.73 (14.17 %), 1.58 (14.98 %) and 1.9 (6.92 %) for BLEU1, BLEU2, BLEU3, BLEU4, METEOR, ROUGE-L respectively. Human evaluation and ablation studies confirm the quality of the generated comments and the effect of architecture and ranking APIs.
An Exploratory Study on Code Attention in BERT
Apr 05, 2022
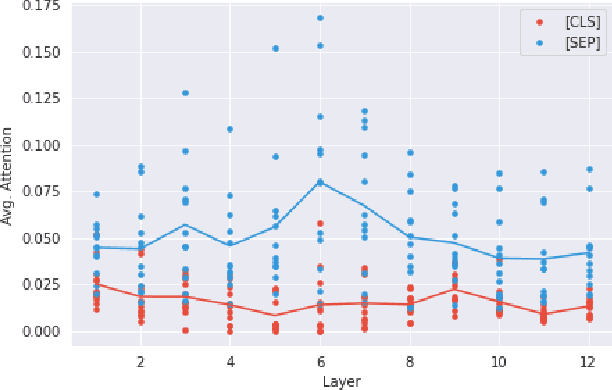

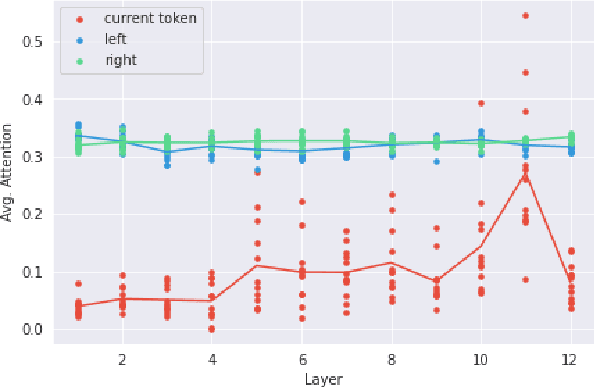
Many recent models in software engineering introduced deep neural models based on the Transformer architecture or use transformer-based Pre-trained Language Models (PLM) trained on code. Although these models achieve the state of the arts results in many downstream tasks such as code summarization and bug detection, they are based on Transformer and PLM, which are mainly studied in the Natural Language Processing (NLP) field. The current studies rely on the reasoning and practices from NLP for these models in code, despite the differences between natural languages and programming languages. There is also limited literature on explaining how code is modeled. Here, we investigate the attention behavior of PLM on code and compare it with natural language. We pre-trained BERT, a Transformer based PLM, on code and explored what kind of information it learns, both semantic and syntactic. We run several experiments to analyze the attention values of code constructs on each other and what BERT learns in each layer. Our analyses show that BERT pays more attention to syntactic entities, specifically identifiers and separators, in contrast to the most attended token [CLS] in NLP. This observation motivated us to leverage identifiers to represent the code sequence instead of the [CLS] token when used for code clone detection. Our results show that employing embeddings from identifiers increases the performance of BERT by 605% and 4% F1-score in its lower layers and the upper layers, respectively. When identifiers' embeddings are used in CodeBERT, a code-based PLM, the performance is improved by 21-24% in the F1-score of clone detection. The findings can benefit the research community by using code-specific representations instead of applying the common embeddings used in NLP, and open new directions for developing smaller models with similar performance.
On the Transferability of Pre-trained Language Models for Low-Resource Programming Languages
Apr 05, 2022
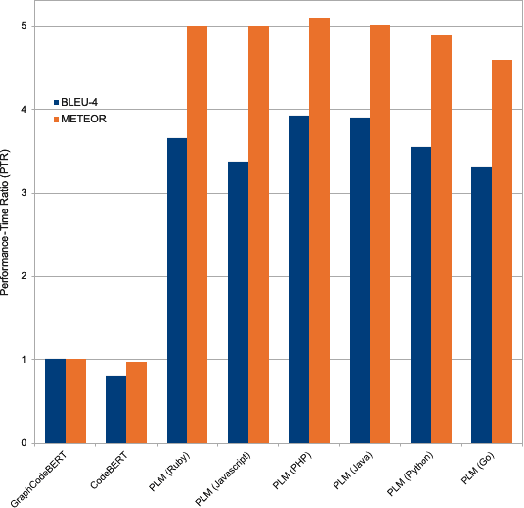
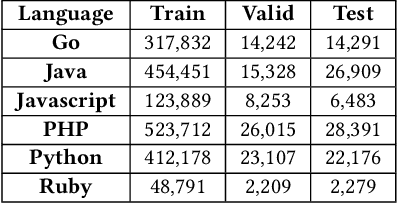
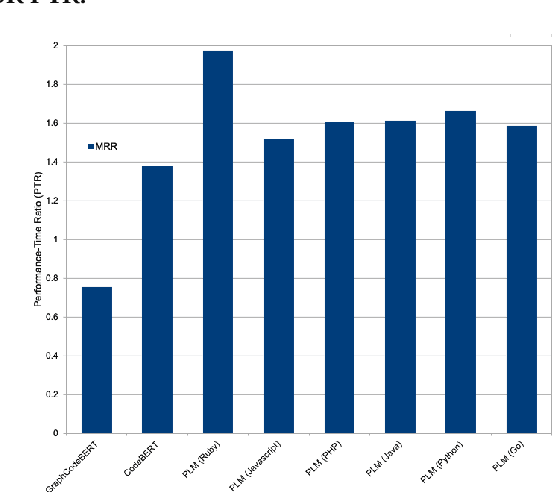
A recent study by Ahmed and Devanbu reported that using a corpus of code written in multilingual datasets to fine-tune multilingual Pre-trained Language Models (PLMs) achieves higher performance as opposed to using a corpus of code written in just one programming language. However, no analysis was made with respect to fine-tuning monolingual PLMs. Furthermore, some programming languages are inherently different and code written in one language usually cannot be interchanged with the others, i.e., Ruby and Java code possess very different structure. To better understand how monolingual and multilingual PLMs affect different programming languages, we investigate 1) the performance of PLMs on Ruby for two popular Software Engineering tasks: Code Summarization and Code Search, 2) the strategy (to select programming languages) that works well on fine-tuning multilingual PLMs for Ruby, and 3) the performance of the fine-tuned PLMs on Ruby given different code lengths. In this work, we analyze over a hundred of pre-trained and fine-tuned models. Our results show that 1) multilingual PLMs have a lower Performance-to-Time Ratio (the BLEU, METEOR, or MRR scores over the fine-tuning duration) as compared to monolingual PLMs, 2) our proposed strategy to select target programming languages to fine-tune multilingual PLMs is effective: it reduces the time to fine-tune yet achieves higher performance in Code Summarization and Code Search tasks, and 3) our proposed strategy consistently shows good performance on different code lengths.
LAMNER: Code Comment Generation Using Character Language Model and Named Entity Recognition
Apr 05, 2022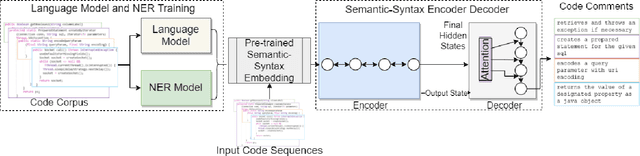
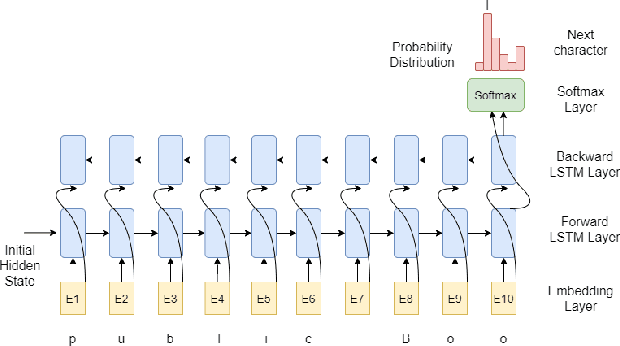
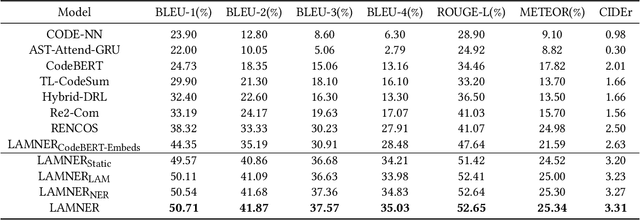
Code comment generation is the task of generating a high-level natural language description for a given code method or function. Although researchers have been studying multiple ways to generate code comments automatically, previous work mainly considers representing a code token in its entirety semantics form only (e.g., a language model is used to learn the semantics of a code token), and additional code properties such as the tree structure of a code are included as an auxiliary input to the model. There are two limitations: 1) Learning the code token in its entirety form may not be able to capture information succinctly in source code, and 2) The code token does not contain additional syntactic information, inherently important in programming languages. In this paper, we present LAnguage Model and Named Entity Recognition (LAMNER), a code comment generator capable of encoding code constructs effectively and capturing the structural property of a code token. A character-level language model is used to learn the semantic representation to encode a code token. For the structural property of a token, a Named Entity Recognition model is trained to learn the different types of code tokens. These representations are then fed into an encoder-decoder architecture to generate code comments. We evaluate the generated comments from LAMNER and other baselines on a popular Java dataset with four commonly used metrics. Our results show that LAMNER is effective and improves over the best baseline model in BLEU-1, BLEU-2, BLEU-3, BLEU-4, ROUGE-L, METEOR, and CIDEr by 14.34%, 18.98%, 21.55%, 23.00%, 10.52%, 1.44%, and 25.86%, respectively. Additionally, we fused LAMNER's code representation with the baseline models, and the fused models consistently showed improvement over the non-fused models. The human evaluation further shows that LAMNER produces high-quality code comments.
FACOS: Finding API Relevant Contents on Stack Overflow with Semantic and Syntactic Analysis
Nov 14, 2021



Collecting API examples, usages, and mentions relevant to a specific API method over discussions on venues such as Stack Overflow is not a trivial problem. It requires efforts to correctly recognize whether the discussion refers to the API method that developers/tools are searching for. The content of the thread, which consists of both text paragraphs describing the involvement of the API method in the discussion and the code snippets containing the API invocation, may refer to the given API method. Leveraging this observation, we develop FACOS, a context-specific algorithm to capture the semantic and syntactic information of the paragraphs and code snippets in a discussion. FACOS combines a syntactic word-based score with a score from a predictive model fine-tuned from CodeBERT. FACOS beats the state-of-the-art approach by 13.9% in terms of F1-score.