 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Transferability of Pre-trained Language Models for Low-Resource Programming Languages
Paper and Code
Apr 05, 2022
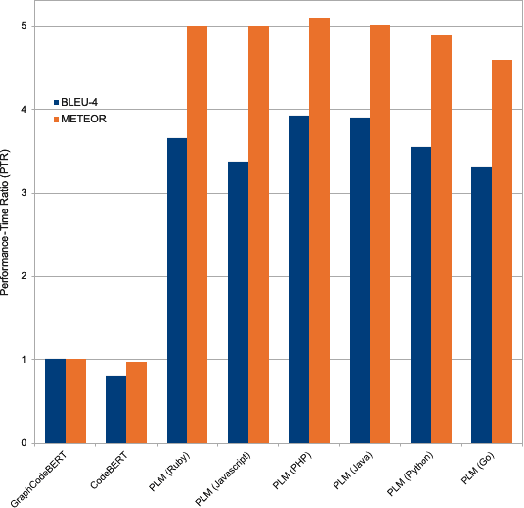
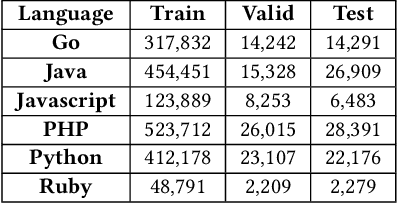
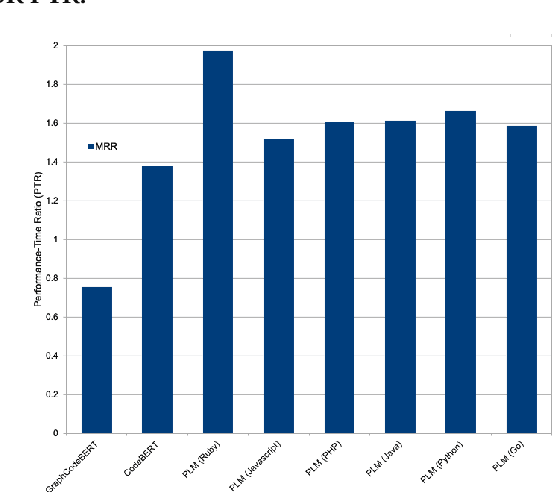
A recent study by Ahmed and Devanbu reported that using a corpus of code written in multilingual datasets to fine-tune multilingual Pre-trained Language Models (PLMs) achieves higher performance as opposed to using a corpus of code written in just one programming language. However, no analysis was made with respect to fine-tuning monolingual PLMs. Furthermore, some programming languages are inherently different and code written in one language usually cannot be interchanged with the others, i.e., Ruby and Java code possess very different structure. To better understand how monolingual and multilingual PLMs affect different programming languages, we investigate 1) the performance of PLMs on Ruby for two popular Software Engineering tasks: Code Summarization and Code Search, 2) the strategy (to select programming languages) that works well on fine-tuning multilingual PLMs for Ruby, and 3) the performance of the fine-tuned PLMs on Ruby given different code lengths. In this work, we analyze over a hundred of pre-trained and fine-tuned models. Our results show that 1) multilingual PLMs have a lower Performance-to-Time Ratio (the BLEU, METEOR, or MRR scores over the fine-tuning duration) as compared to monolingual PLMs, 2) our proposed strategy to select target programming languages to fine-tune multilingual PLMs is effective: it reduces the time to fine-tune yet achieves higher performance in Code Summarization and Code Search tasks, and 3) our proposed strategy consistently shows good performance on different code lengths.