 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exploratory Study on Code Attention in BERT
Apr 05, 2022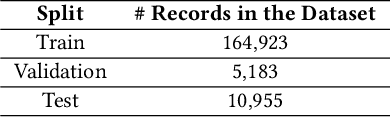
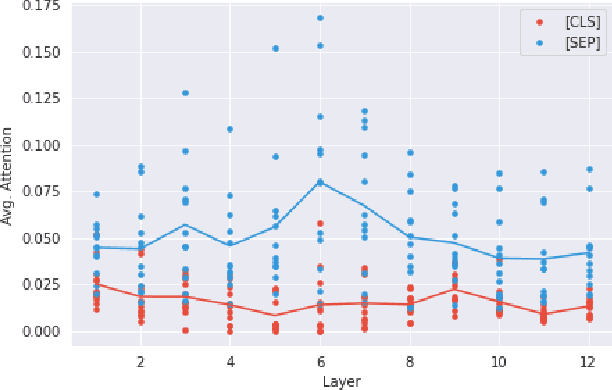

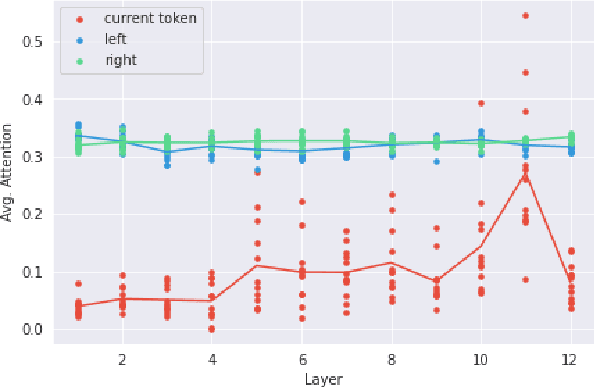
Many recent models in software engineering introduced deep neural models based on the Transformer architecture or use transformer-based Pre-trained Language Models (PLM) trained on code. Although these models achieve the state of the arts results in many downstream tasks such as code summarization and bug detection, they are based on Transformer and PLM, which are mainly studied in the Natural Language Processing (NLP) field. The current studies rely on the reasoning and practices from NLP for these models in code, despite the differences between natural languages and programming languages. There is also limited literature on explaining how code is modeled. Here, we investigate the attention behavior of PLM on code and compare it with natural language. We pre-trained BERT, a Transformer based PLM, on code and explored what kind of information it learns, both semantic and syntactic. We run several experiments to analyze the attention values of code constructs on each other and what BERT learns in each layer. Our analyses show that BERT pays more attention to syntactic entities, specifically identifiers and separators, in contrast to the most attended token [CLS] in NLP. This observation motivated us to leverage identifiers to represent the code sequence instead of the [CLS] token when used for code clone detection. Our results show that employing embeddings from identifiers increases the performance of BERT by 605% and 4% F1-score in its lower layers and the upper layers, respectively. When identifiers' embeddings are used in CodeBERT, a code-based PLM, the performance is improved by 21-24% in the F1-score of clone detection. The findings can benefit the research community by using code-specific representations instead of applying the common embeddings used in NLP, and open new directions for developing smaller models with similar performance.
On the Transferability of Pre-trained Language Models for Low-Resource Programming Languages
Apr 05, 2022
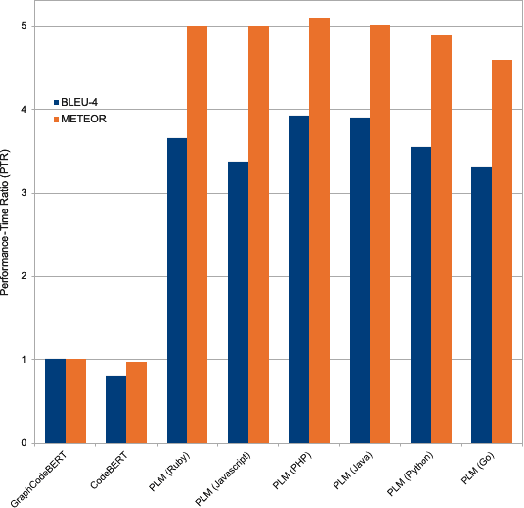
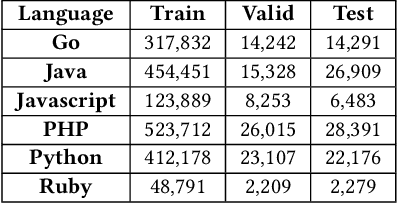
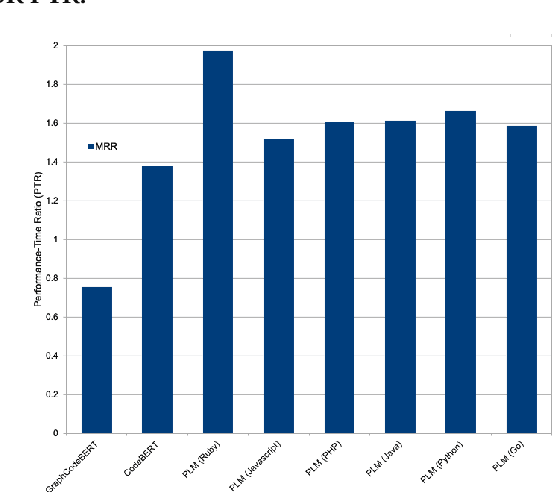
A recent study by Ahmed and Devanbu reported that using a corpus of code written in multilingual datasets to fine-tune multilingual Pre-trained Language Models (PLMs) achieves higher performance as opposed to using a corpus of code written in just one programming language. However, no analysis was made with respect to fine-tuning monolingual PLMs. Furthermore, some programming languages are inherently different and code written in one language usually cannot be interchanged with the others, i.e., Ruby and Java code possess very different structure. To better understand how monolingual and multilingual PLMs affect different programming languages, we investigate 1) the performance of PLMs on Ruby for two popular Software Engineering tasks: Code Summarization and Code Search, 2) the strategy (to select programming languages) that works well on fine-tuning multilingual PLMs for Ruby, and 3) the performance of the fine-tuned PLMs on Ruby given different code lengths. In this work, we analyze over a hundred of pre-trained and fine-tuned models. Our results show that 1) multilingual PLMs have a lower Performance-to-Time Ratio (the BLEU, METEOR, or MRR scores over the fine-tuning duration) as compared to monolingual PLMs, 2) our proposed strategy to select target programming languages to fine-tune multilingual PLMs is effective: it reduces the time to fine-tune yet achieves higher performance in Code Summarization and Code Search tasks, and 3) our proposed strategy consistently shows good performance on different code lengths.
LAMNER: Code Comment Generation Using Character Language Model and Named Entity Recognition
Apr 05, 2022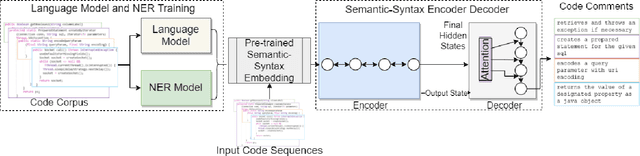
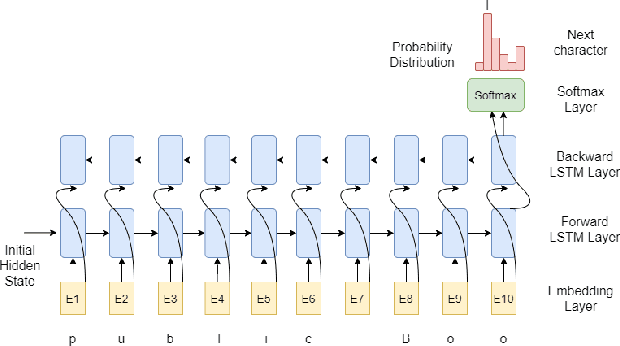
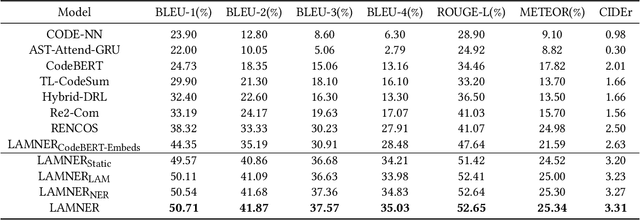
Code comment generation is the task of generating a high-level natural language description for a given code method or function. Although researchers have been studying multiple ways to generate code comments automatically, previous work mainly considers representing a code token in its entirety semantics form only (e.g., a language model is used to learn the semantics of a code token), and additional code properties such as the tree structure of a code are included as an auxiliary input to the model. There are two limitations: 1) Learning the code token in its entirety form may not be able to capture information succinctly in source code, and 2) The code token does not contain additional syntactic information, inherently important in programming languages. In this paper, we present LAnguage Model and Named Entity Recognition (LAMNER), a code comment generator capable of encoding code constructs effectively and capturing the structural property of a code token. A character-level language model is used to learn the semantic representation to encode a code token. For the structural property of a token, a Named Entity Recognition model is trained to learn the different types of code tokens. These representations are then fed into an encoder-decoder architecture to generate code comments. We evaluate the generated comments from LAMNER and other baselines on a popular Java dataset with four commonly used metrics. Our results show that LAMNER is effective and improves over the best baseline model in BLEU-1, BLEU-2, BLEU-3, BLEU-4, ROUGE-L, METEOR, and CIDEr by 14.34%, 18.98%, 21.55%, 23.00%, 10.52%, 1.44%, and 25.86%, respectively. Additionally, we fused LAMNER's code representation with the baseline models, and the fused models consistently showed improvement over the non-fused models. The human evaluation further shows that LAMNER produces high-quality code comments.