 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Low-Rank Latent Spaces with Simple Deterministic Autoencoder: Theoretical and Empirical Insights
Oct 24, 2023The autoencoder is an unsupervised learning paradigm that aims to create a compact latent representation of data by minimizing the reconstruction loss. However, it tends to overlook the fact that most data (images) are embedded in a lower-dimensional space, which is crucial for effective data representation. To address this limitation, we propose a novel approach called Low-Rank Autoencoder (LoRAE). In LoRAE, we incorporated a low-rank regularizer to adaptively reconstruct a low-dimensional latent space while preserving the basic objective of an autoencoder. This helps embed the data in a lower-dimensional space while preserving important information. It is a simple autoencoder extension that learns low-rank latent space. Theoretically, we establish a tighter error bound for our model. Empirically, our model's superiority shines through various tasks such as image generation and downstream classification. Both theoretical and practical outcomes highlight the importance of acquiring low-dimensional embeddings.
An Exploratory Study on Code Attention in BERT
Apr 05, 2022
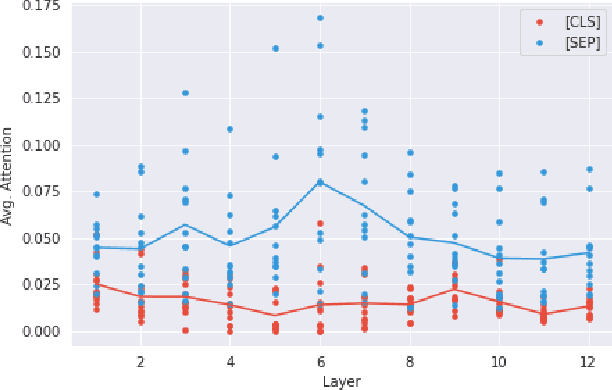

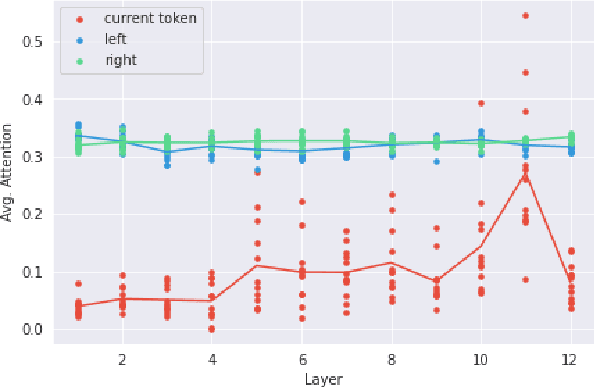
Many recent models in software engineering introduced deep neural models based on the Transformer architecture or use transformer-based Pre-trained Language Models (PLM) trained on code. Although these models achieve the state of the arts results in many downstream tasks such as code summarization and bug detection, they are based on Transformer and PLM, which are mainly studied in the Natural Language Processing (NLP) field. The current studies rely on the reasoning and practices from NLP for these models in code, despite the differences between natural languages and programming languages. There is also limited literature on explaining how code is modeled. Here, we investigate the attention behavior of PLM on code and compare it with natural language. We pre-trained BERT, a Transformer based PLM, on code and explored what kind of information it learns, both semantic and syntactic. We run several experiments to analyze the attention values of code constructs on each other and what BERT learns in each layer. Our analyses show that BERT pays more attention to syntactic entities, specifically identifiers and separators, in contrast to the most attended token [CLS] in NLP. This observation motivated us to leverage identifiers to represent the code sequence instead of the [CLS] token when used for code clone detection. Our results show that employing embeddings from identifiers increases the performance of BERT by 605% and 4% F1-score in its lower layers and the upper layers, respectively. When identifiers' embeddings are used in CodeBERT, a code-based PLM, the performance is improved by 21-24% in the F1-score of clone detection. The findings can benefit the research community by using code-specific representations instead of applying the common embeddings used in NLP, and open new directions for developing smaller models with similar performance.
LAMNER: Code Comment Generation Using Character Language Model and Named Entity Recognition
Apr 05, 2022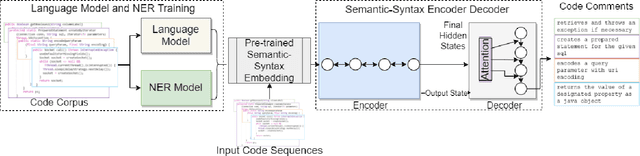
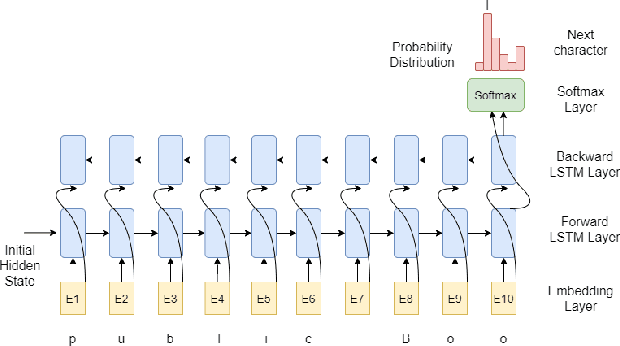
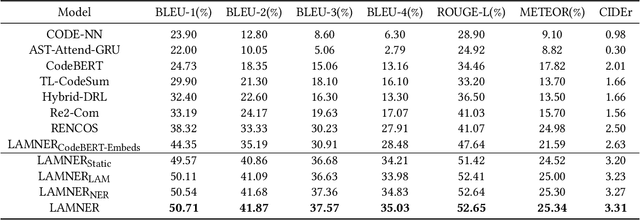
Code comment generation is the task of generating a high-level natural language description for a given code method or function. Although researchers have been studying multiple ways to generate code comments automatically, previous work mainly considers representing a code token in its entirety semantics form only (e.g., a language model is used to learn the semantics of a code token), and additional code properties such as the tree structure of a code are included as an auxiliary input to the model. There are two limitations: 1) Learning the code token in its entirety form may not be able to capture information succinctly in source code, and 2) The code token does not contain additional syntactic information, inherently important in programming languages. In this paper, we present LAnguage Model and Named Entity Recognition (LAMNER), a code comment generator capable of encoding code constructs effectively and capturing the structural property of a code token. A character-level language model is used to learn the semantic representation to encode a code token. For the structural property of a token, a Named Entity Recognition model is trained to learn the different types of code tokens. These representations are then fed into an encoder-decoder architecture to generate code comments. We evaluate the generated comments from LAMNER and other baselines on a popular Java dataset with four commonly used metrics. Our results show that LAMNER is effective and improves over the best baseline model in BLEU-1, BLEU-2, BLEU-3, BLEU-4, ROUGE-L, METEOR, and CIDEr by 14.34%, 18.98%, 21.55%, 23.00%, 10.52%, 1.44%, and 25.86%, respectively. Additionally, we fused LAMNER's code representation with the baseline models, and the fused models consistently showed improvement over the non-fused models. The human evaluation further shows that LAMNER produces high-quality code comments.
Salient Image Matting
Mar 23, 2021
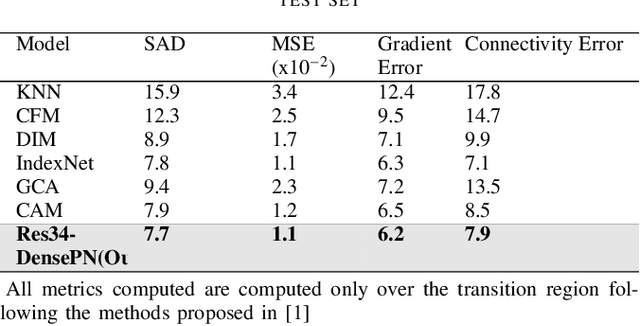

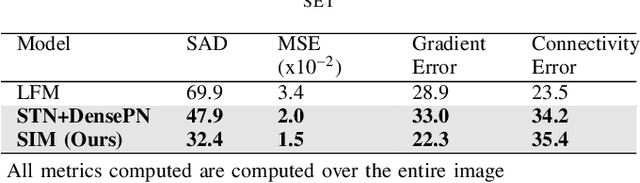
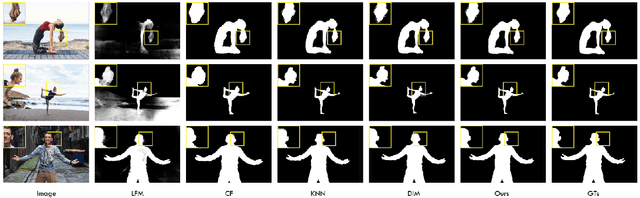
In this paper, we propose an image matting framework called Salient Image Matting to estimate the per-pixel opacity value of the most salient foreground in an image. To deal with a large amount of semantic diversity in images, a trimap is conventionally required as it provides important guidance about object semantics to the matting process. However, creating a good trimap is often expensive and timeconsuming. The SIM framework simultaneously deals with the challenge of learning a wide range of semantics and salient object types in a fully automatic and an end to end manner. Specifically, our framework is able to produce accurate alpha mattes for a wide range of foreground objects and cases where the foreground class, such as human, appears in a very different context than the train data directly from an RGB input. This is done by employing a salient object detection model to produce a trimap of the most salient object in the image in order to guide the matting model about higher-level object semantics. Our framework leverages large amounts of coarse annotations coupled with a heuristic trimap generation scheme to train the trimap prediction network so it can produce trimaps for arbitrary foregrounds. Moreover, we introduce a multi-scale fusion architecture for the task of matting to better capture finer, low-level opacity semantics. With high-level guidance provided by the trimap network, our framework requires only a fraction of expensive matting data as compared to other automatic methods while being able to produce alpha mattes for a diverse range of inputs. We demonstrate our framework on a range of diverse images and experimental results show our framework compares favourably against state of art matting methods without the need for a trimap
API2Com: On the Improvement of Automatically Generated Code Comments Using API Documentations
Mar 19, 2021
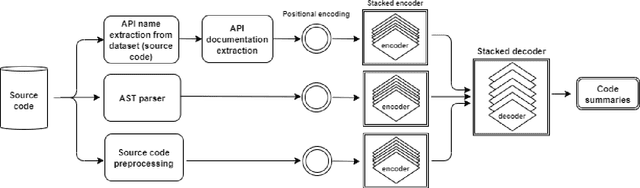

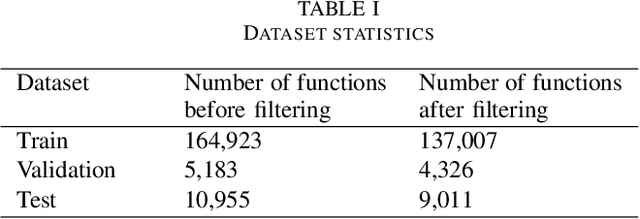
Code comments can help in program comprehension and are considered as important artifacts to help developers in software maintenance. However, the comments are mostly missing or are outdated, specially in complex software projects. As a result, several automatic comment generation models are developed as a solution. The recent models explore the integration of external knowledge resources such as Unified Modeling Language class diagrams to improve the generated comments. In this paper, we propose API2Com, a model that leverages the Application Programming Interface Documentations (API Docs) as a knowledge resource for comment generation. The API Docs include the description of the methods in more details and therefore, can provide better context in the generated comments. The API Docs are used along with the code snippets and Abstract Syntax Trees in our model. We apply the model on a large Java dataset of over 130,000 methods and evaluate it using both Transformer and RNN-base architectures. Interestingly, when API Docs are used, the performance increase is negligible. We therefore run different experiments to reason about the results. For methods that only contain one API, adding API Docs improves the results by 4% BLEU score on average (BLEU score is an automatic evaluation metric used in machine translation). However, as the number of APIs that are used in a method increases, the performance of the model in generating comments decreases due to long documentations used in the input. Our results confirm that the API Docs can be useful in generating better comments, but, new techniques are required to identify the most informative ones in a method rather than using all documentations simultaneously.
AlphaNet: An Attention Guided Deep Network for Automatic Image Matting
Mar 07, 2020
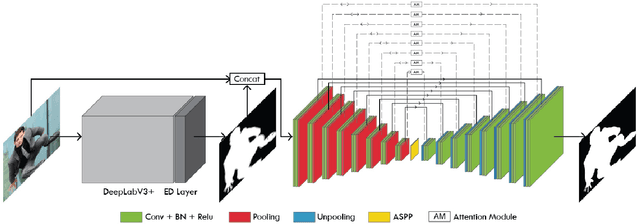
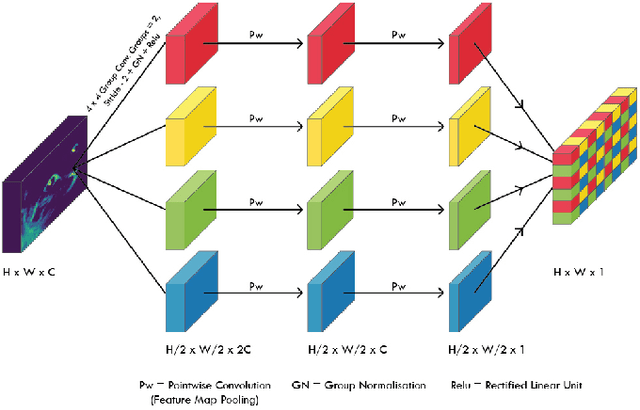
In this paper, we propose an end to end solution for image matting i.e high-precision extraction of foreground objects from natural images. Image matting and background detection can be achieved easily through chroma keying in a studio setting when the background is either pure green or blue. Nonetheless, image matting in natural scenes with complex and uneven depth backgrounds remains a tedious task that requires human intervention. To achieve complete automatic foreground extraction in natural scenes, we propose a method that assimilates semantic segmentation and deep image matting processes into a single network to generate detailed semantic mattes for image composition task. The contribution of our proposed method is two-fold, firstly it can be interpreted as a fully automated semantic image matting method and secondly as a refinement of existing semantic segmentation models. We propose a novel model architecture as a combination of segmentation and matting that unifies the function of upsampling and downsampling operators with the notion of attention. As shown in our work, attention guided downsampling and upsampling can extract high-quality boundary details, unlike other normal downsampling and upsampling techniques. For achieving the same, we utilized an attention guided encoder-decoder framework which does unsupervised learning for generating an attention map adaptively from the data to serve and direct the upsampling and downsampling operators. We also construct a fashion e-commerce focused dataset with high-quality alpha mattes to facilitate the training and evaluation for image matting.
Retrieving Similar E-Commerce Images Using Deep Learning
Jan 11, 2019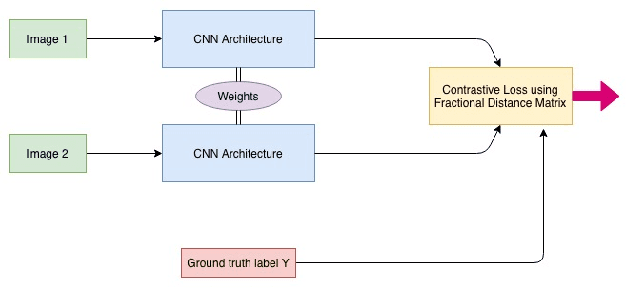
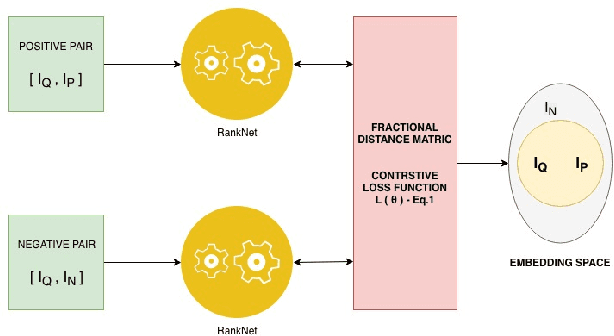
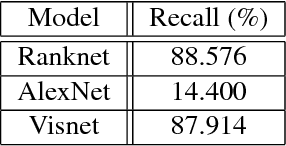
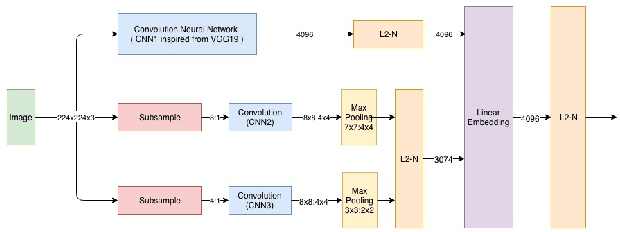
In this paper, we propose a deep convolutional neural network for learning the embeddings of images in order to capture the notion of visual similarity. We present a deep siamese architecture that when trained on positive and negative pairs of images learn an embedding that accurately approximates the ranking of images in order of visual similarity notion. We also implement a novel loss calculation method using an angular loss metrics based on the problems requirement. The final embedding of the image is combined representation of the lower and top-level embeddings. We used fractional distance matrix to calculate the distance between the learned embeddings in n-dimensional space. In the end, we compare our architecture with other existing deep architecture and go on to demonstrate the superiority of our solution in terms of image retrieval by testing the architecture on four datasets. We also show how our suggested network is better than the other traditional deep CNNs used for capturing fine-grained image similarities by learning an optimum embedding.