 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalient Image Matting
Mar 23, 2021
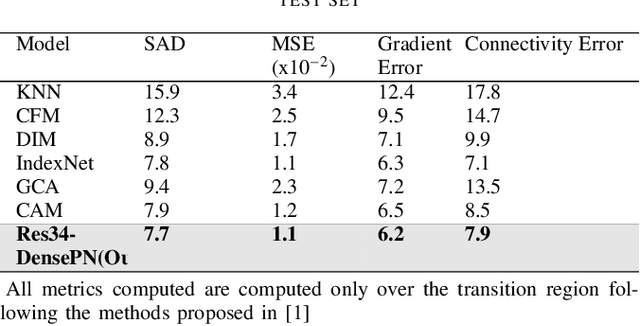

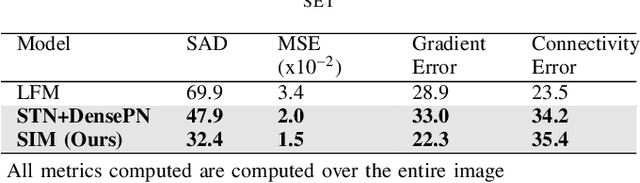
In this paper, we propose an image matting framework called Salient Image Matting to estimate the per-pixel opacity value of the most salient foreground in an image. To deal with a large amount of semantic diversity in images, a trimap is conventionally required as it provides important guidance about object semantics to the matting process. However, creating a good trimap is often expensive and timeconsuming. The SIM framework simultaneously deals with the challenge of learning a wide range of semantics and salient object types in a fully automatic and an end to end manner. Specifically, our framework is able to produce accurate alpha mattes for a wide range of foreground objects and cases where the foreground class, such as human, appears in a very different context than the train data directly from an RGB input. This is done by employing a salient object detection model to produce a trimap of the most salient object in the image in order to guide the matting model about higher-level object semantics. Our framework leverages large amounts of coarse annotations coupled with a heuristic trimap generation scheme to train the trimap prediction network so it can produce trimaps for arbitrary foregrounds. Moreover, we introduce a multi-scale fusion architecture for the task of matting to better capture finer, low-level opacity semantics. With high-level guidance provided by the trimap network, our framework requires only a fraction of expensive matting data as compared to other automatic methods while being able to produce alpha mattes for a diverse range of inputs. We demonstrate our framework on a range of diverse images and experimental results show our framework compares favourably against state of art matting methods without the need for a trimap