 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalient Image Matting
Mar 23, 2021
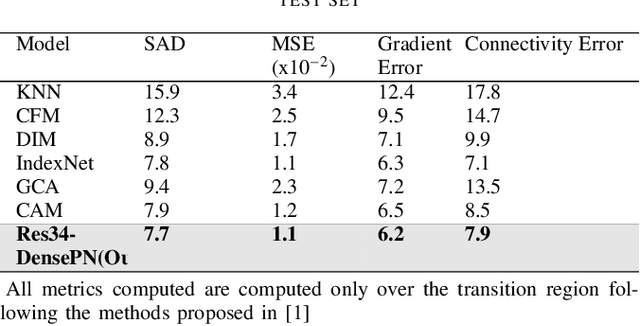

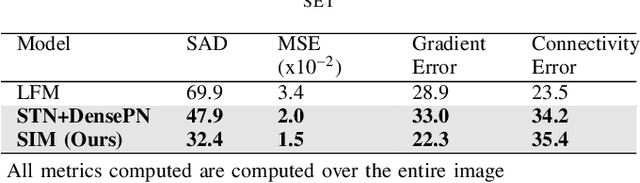
In this paper, we propose an image matting framework called Salient Image Matting to estimate the per-pixel opacity value of the most salient foreground in an image. To deal with a large amount of semantic diversity in images, a trimap is conventionally required as it provides important guidance about object semantics to the matting process. However, creating a good trimap is often expensive and timeconsuming. The SIM framework simultaneously deals with the challenge of learning a wide range of semantics and salient object types in a fully automatic and an end to end manner. Specifically, our framework is able to produce accurate alpha mattes for a wide range of foreground objects and cases where the foreground class, such as human, appears in a very different context than the train data directly from an RGB input. This is done by employing a salient object detection model to produce a trimap of the most salient object in the image in order to guide the matting model about higher-level object semantics. Our framework leverages large amounts of coarse annotations coupled with a heuristic trimap generation scheme to train the trimap prediction network so it can produce trimaps for arbitrary foregrounds. Moreover, we introduce a multi-scale fusion architecture for the task of matting to better capture finer, low-level opacity semantics. With high-level guidance provided by the trimap network, our framework requires only a fraction of expensive matting data as compared to other automatic methods while being able to produce alpha mattes for a diverse range of inputs. We demonstrate our framework on a range of diverse images and experimental results show our framework compares favourably against state of art matting methods without the need for a trimap
AlphaNet: An Attention Guided Deep Network for Automatic Image Matting
Mar 07, 2020
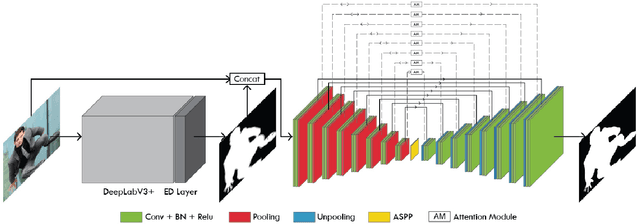
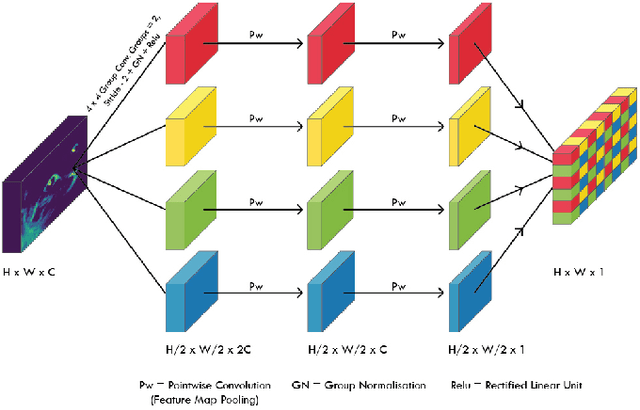
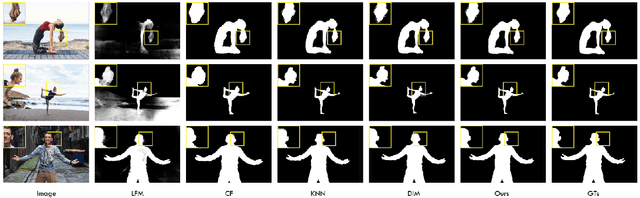
In this paper, we propose an end to end solution for image matting i.e high-precision extraction of foreground objects from natural images. Image matting and background detection can be achieved easily through chroma keying in a studio setting when the background is either pure green or blue. Nonetheless, image matting in natural scenes with complex and uneven depth backgrounds remains a tedious task that requires human intervention. To achieve complete automatic foreground extraction in natural scenes, we propose a method that assimilates semantic segmentation and deep image matting processes into a single network to generate detailed semantic mattes for image composition task. The contribution of our proposed method is two-fold, firstly it can be interpreted as a fully automated semantic image matting method and secondly as a refinement of existing semantic segmentation models. We propose a novel model architecture as a combination of segmentation and matting that unifies the function of upsampling and downsampling operators with the notion of attention. As shown in our work, attention guided downsampling and upsampling can extract high-quality boundary details, unlike other normal downsampling and upsampling techniques. For achieving the same, we utilized an attention guided encoder-decoder framework which does unsupervised learning for generating an attention map adaptively from the data to serve and direct the upsampling and downsampling operators. We also construct a fashion e-commerce focused dataset with high-quality alpha mattes to facilitate the training and evaluation for image matting.