 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaNet: An Attention Guided Deep Network for Automatic Image Matting
Mar 07, 2020
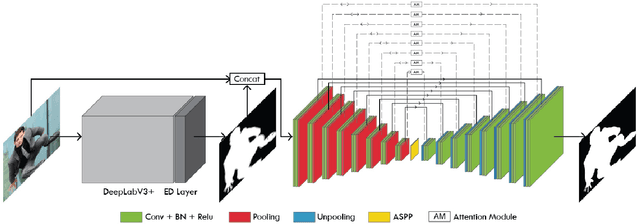
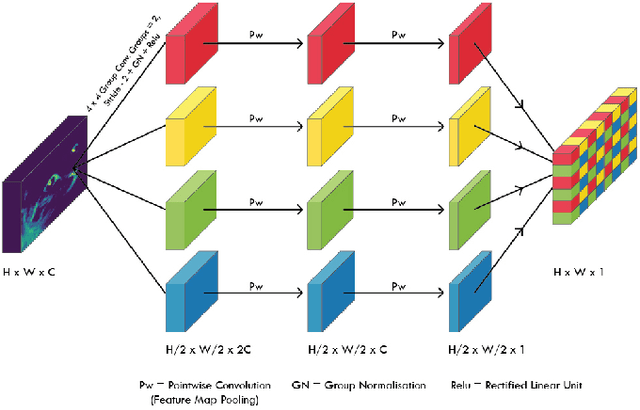
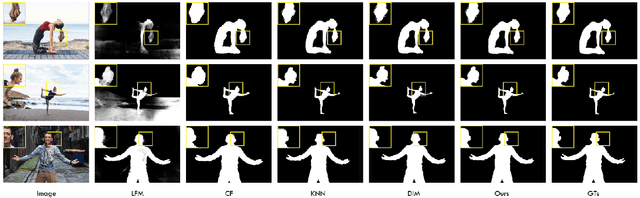
In this paper, we propose an end to end solution for image matting i.e high-precision extraction of foreground objects from natural images. Image matting and background detection can be achieved easily through chroma keying in a studio setting when the background is either pure green or blue. Nonetheless, image matting in natural scenes with complex and uneven depth backgrounds remains a tedious task that requires human intervention. To achieve complete automatic foreground extraction in natural scenes, we propose a method that assimilates semantic segmentation and deep image matting processes into a single network to generate detailed semantic mattes for image composition task. The contribution of our proposed method is two-fold, firstly it can be interpreted as a fully automated semantic image matting method and secondly as a refinement of existing semantic segmentation models. We propose a novel model architecture as a combination of segmentation and matting that unifies the function of upsampling and downsampling operators with the notion of attention. As shown in our work, attention guided downsampling and upsampling can extract high-quality boundary details, unlike other normal downsampling and upsampling techniques. For achieving the same, we utilized an attention guided encoder-decoder framework which does unsupervised learning for generating an attention map adaptively from the data to serve and direct the upsampling and downsampling operators. We also construct a fashion e-commerce focused dataset with high-quality alpha mattes to facilitate the training and evaluation for image matting.
MILDNet: A Lightweight Single Scaled Deep Ranking Architecture
Mar 14, 2019



Multi-scale deep CNN architecture [1, 2, 3] successfully captures both fine and coarse level image descriptors for visual similarity task, but they come up with expensive memory overhead and latency. In this paper, we propose a competing novel CNN architecture, called MILDNet, which merits by being vastly compact (about 3 times). Inspired by the fact that successive CNN layers represent the image with increasing levels of abstraction, we compressed our deep ranking model to a single CNN by coupling activations from multiple intermediate layers along with the last layer. Trained on the famous Street2shop dataset [4], we demonstrate that our approach performs as good as the current state-of-the-art models with only one third of the parameters, model size, training time and significant reduction in inference time. The significance of intermediate layers on image retrieval task has also been shown to be performing on popular datasets Holidays, Oxford, Paris [5]. So even though our experiments are done on ecommerce domain, it is applicable to other domains as well. We further did an ablation study to validate our hypothesis by checking the impact on adding each intermediate layer. With this we also present two more useful variants of MILDNet, a mobile model (12 times smaller) for on-edge devices and a compactly featured model (512-d feature embeddings) for systems with less RAMs and to reduce the ranking cost. Further we present an intuitive way to automatically create a tailored in-house triplet training dataset, which is very hard to create manually. This solution too can also be deployed as an all-inclusive visual similarity solution. Finally, we present our entire production level architecture which currently powers visual similarity at Fynd.
Retrieving Similar E-Commerce Images Using Deep Learning
Jan 11, 2019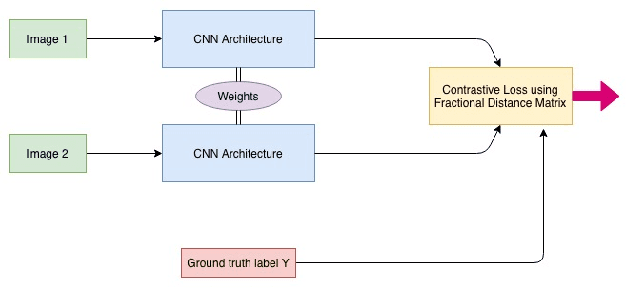
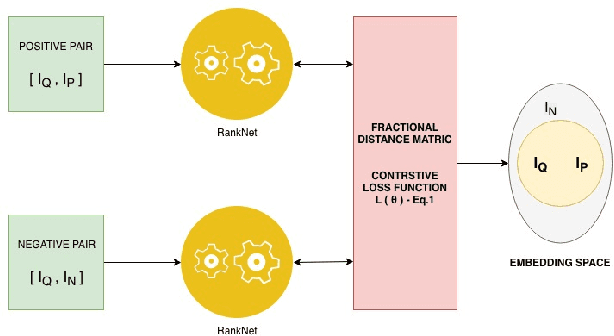
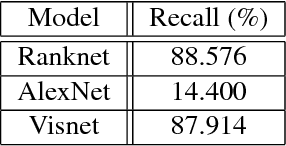
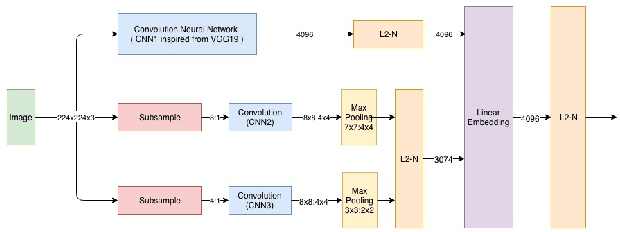
In this paper, we propose a deep convolutional neural network for learning the embeddings of images in order to capture the notion of visual similarity. We present a deep siamese architecture that when trained on positive and negative pairs of images learn an embedding that accurately approximates the ranking of images in order of visual similarity notion. We also implement a novel loss calculation method using an angular loss metrics based on the problems requirement. The final embedding of the image is combined representation of the lower and top-level embeddings. We used fractional distance matrix to calculate the distance between the learned embeddings in n-dimensional space. In the end, we compare our architecture with other existing deep architecture and go on to demonstrate the superiority of our solution in terms of image retrieval by testing the architecture on four datasets. We also show how our suggested network is better than the other traditional deep CNNs used for capturing fine-grained image similarities by learning an optimum embedding.