 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClarifyCoder: Clarification-Aware Fine-Tuning for Programmatic Problem Solving
Apr 23, 2025Large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, a significant gap remains between their current performance and that of expert software engineers. A key differentiator is that human engineers actively seek clarification when faced with ambiguous requirements, while LLMs typically generate code regardless of uncertainties in the problem description. We present ClarifyCoder, a novel framework with synthetic data generation and instruction-tuning that enables LLMs to identify ambiguities and request clarification before proceeding with code generation. While recent work has focused on LLM-based agents for iterative code generation, we argue that the fundamental ability to recognize and query ambiguous requirements should be intrinsic to the models themselves. Our approach consists of two main components: (1) a data synthesis technique that augments existing programming datasets with scenarios requiring clarification to generate clarification-aware training data, and (2) a fine-tuning strategy that teaches models to prioritize seeking clarification over immediate code generation when faced with incomplete or ambiguous requirements. We further provide an empirical analysis of integrating ClarifyCoder with standard fine-tuning for a joint optimization of both clarify-awareness and coding ability. Experimental results demonstrate that ClarifyCoder significantly improves the communication capabilities of Code LLMs through meaningful clarification dialogues while maintaining code generation capabilities.
Do Current Language Models Support Code Intelligence for R Programming Language?
Oct 10, 2024
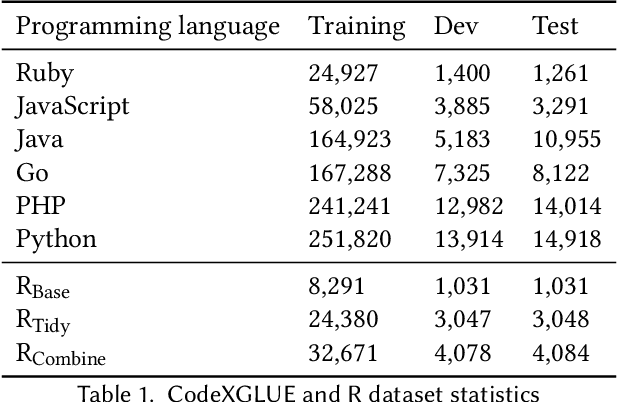
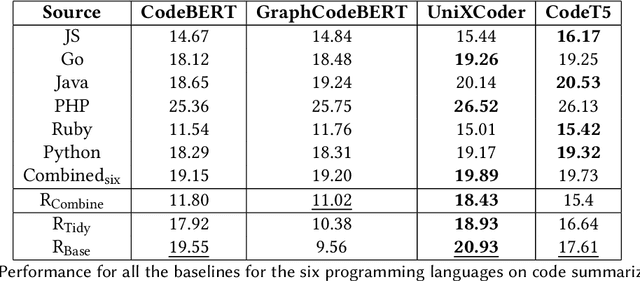
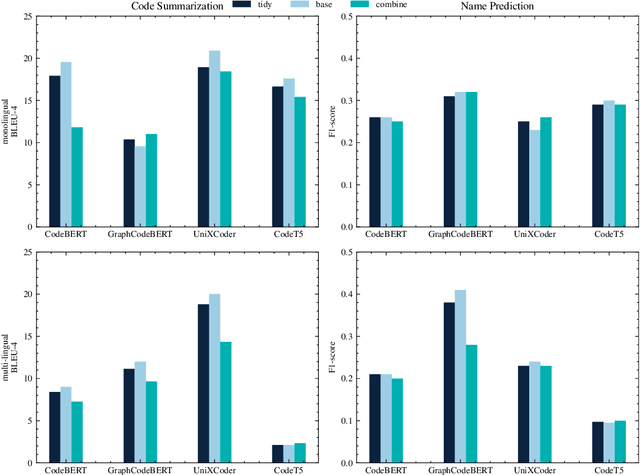
Recent advancements in developing Pre-trained Language Models for Code (Code-PLMs) have urged many areas of Software Engineering (SE) and brought breakthrough results for many SE tasks. Though these models have achieved the state-of-the-art performance for SE tasks for many popular programming languages, such as Java and Python, the Scientific Software and its related languages like R programming language have rarely benefited or even been evaluated with the Code-PLMs. Research has shown that R has many differences with other programming languages and requires specific techniques. In this study, we provide the first insights for code intelligence for R. For this purpose, we collect and open source an R dataset, and evaluate Code-PLMs for the two tasks of code summarization and method name prediction using several settings and strategies, including the differences in two R styles, Tidy-verse and Base R. Our results demonstrate that the studied models have experienced varying degrees of performance degradation when processing R programming language code, which is supported by human evaluation. Additionally, not all models show performance improvement in R-specific tasks even after multi-language fine-tuning. The dual syntax paradigms in R significantly impact the models' performance, particularly in code summarization tasks. Furthermore, the project-specific context inherent in R codebases significantly impacts the performance when attempting cross-project training.
Survey on Code Generation for Low resource and Domain Specific Programming Languages
Oct 04, 2024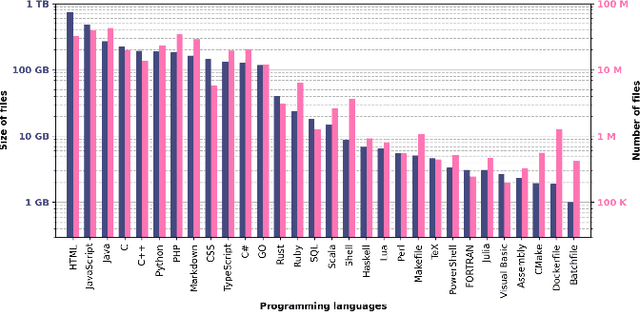
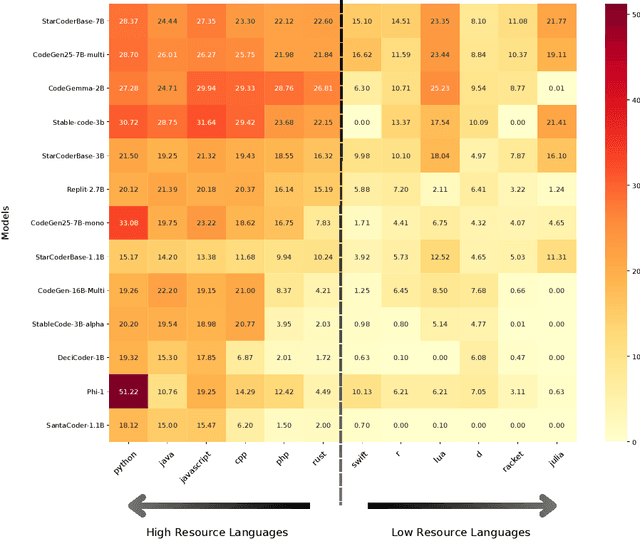

Large Language Models (LLMs) have shown impressive capabilities in code generation for popular programming languages. However, their performance on Low-Resource Programming Languages (LRPLs) and Domain-Specific Languages (DSLs) remains a significant challenge, affecting millions of developers-3.5 million users in Rust alone-who cannot fully utilize LLM capabilities. LRPLs and DSLs encounter unique obstacles, including data scarcity and, for DSLs, specialized syntax that is poorly represented in general-purpose datasets. Addressing these challenges is crucial, as LRPLs and DSLs enhance development efficiency in specialized domains, such as finance and science. While several surveys discuss LLMs in software engineering, none focus specifically on the challenges and opportunities associated with LRPLs and DSLs. Our survey fills this gap by systematically reviewing the current state, methodologies, and challenges in leveraging LLMs for code generation in these languages. We filtered 111 papers from over 27,000 published studies between 2020 and 2024 to evaluate the capabilities and limitations of LLMs in LRPLs and DSLs. We report the LLMs used, benchmarks, and metrics for evaluation, strategies for enhancing performance, and methods for dataset collection and curation. We identified four main evaluation techniques and several metrics for assessing code generation in LRPLs and DSLs. Our analysis categorizes improvement methods into six groups and summarizes novel architectures proposed by researchers. Despite various techniques and metrics, a standard approach and benchmark dataset for evaluating code generation in LRPLs and DSLs are lacking. This survey serves as a resource for researchers and practitioners at the intersection of LLMs, software engineering, and specialized programming languages, laying the groundwork for future advancements in code generation for LRPLs and DSLs.
MergeRepair: An Exploratory Study on Merging Task-Specific Adapters in Code LLMs for Automated Program Repair
Aug 18, 2024

[Context] Large Language Models (LLMs) have shown good performance in several software development-related tasks such as program repair, documentation, code refactoring, debugging, and testing. Adapters are specialized, small modules designed for parameter efficient fine-tuning of LLMs for specific tasks, domains, or applications without requiring extensive retraining of the entire model. These adapters offer a more efficient way to customize LLMs for particular needs, leveraging the pre-existing capabilities of the large model. Merging LLMs and adapters has shown promising results for various natural language domains and tasks, enabling the use of the learned models and adapters without additional training for a new task. [Objective] This research proposes continual merging and empirically studies the capabilities of merged adapters in Code LLMs, specially for the Automated Program Repair (APR) task. The goal is to gain insights into whether and how merging task-specific adapters can affect the performance of APR. [Method] In our framework, MergeRepair, we plan to merge multiple task-specific adapters using three different merging methods and evaluate the performance of the merged adapter for the APR task. Particularly, we will employ two main merging scenarios for all three techniques, (i) merging using equal-weight averaging applied on parameters of different adapters, where all adapters are of equal importance; and (ii) our proposed approach, continual merging, in which we sequentially merge the task-specific adapters and the order and weight of merged adapters matter. By exploratory study of merging techniques, we will investigate the improvement and generalizability of merged adapters for APR. Through continual merging, we will explore the capability of merged adapters and the effect of task order, as it occurs in real-world software projects.
StackRAG Agent: Improving Developer Answers with Retrieval-Augmented Generation
Jun 19, 2024Developers spend much time finding information that is relevant to their questions. Stack Overflow has been the leading resource, and with the advent of Large Language Models (LLMs), generative models such as ChatGPT are used frequently. However, there is a catch in using each one separately. Searching for answers is time-consuming and tedious, as shown by the many tools developed by researchers to address this issue. On the other, using LLMs is not reliable, as they might produce irrelevant or unreliable answers (i.e., hallucination). In this work, we present StackRAG, a retrieval-augmented Multiagent generation tool based on LLMs that combines the two worlds: aggregating the knowledge from SO to enhance the reliability of the generated answers. Initial evaluations show that the generated answers are correct, accurate, relevant, and useful.
Studying Vulnerable Code Entities in R
Feb 06, 2024
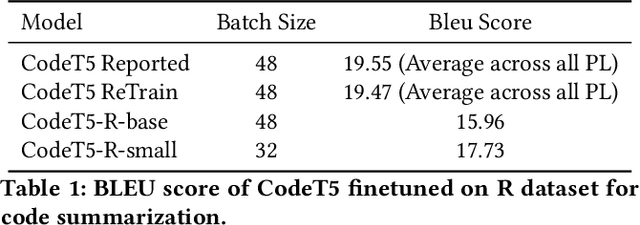
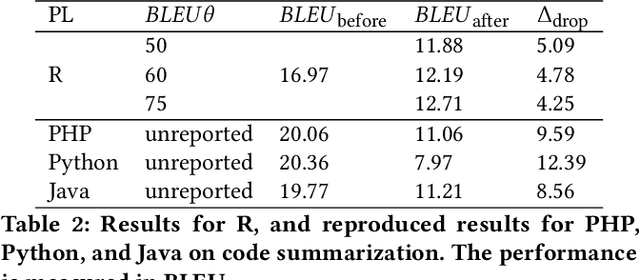

Pre-trained Code Language Models (Code-PLMs) have shown many advancements and achieved state-of-the-art results for many software engineering tasks in the past few years. These models are mainly targeted for popular programming languages such as Java and Python, leaving out many other ones like R. Though R has a wide community of developers and users, there is little known about the applicability of Code-PLMs for R. In this preliminary study, we aim to investigate the vulnerability of Code-PLMs for code entities in R. For this purpose, we use an R dataset of code and comment pairs and then apply CodeAttack, a black-box attack model that uses the structure of code to generate adversarial code samples. We investigate how the model can attack different entities in R. This is the first step towards understanding the importance of R token types, compared to popular programming languages (e.g., Java). We limit our study to code summarization. Our results show that the most vulnerable code entity is the identifier, followed by some syntax tokens specific to R. The results can shed light on the importance of token types and help in developing models for code summarization and method name prediction for the R language.
On The Cross-Modal Transfer from Natural Language to Code through Adapter Modules
Apr 19, 2022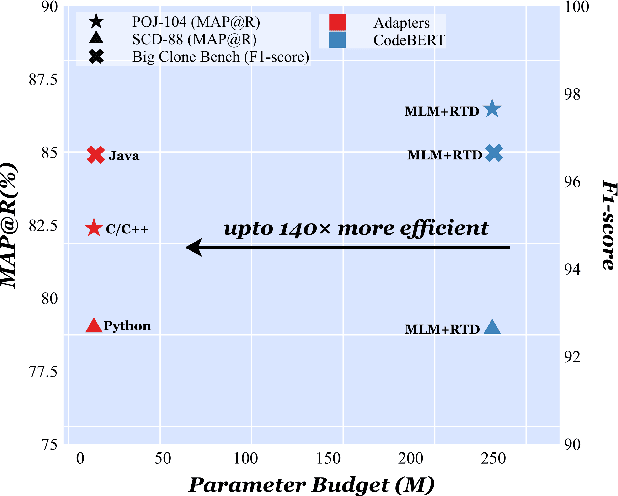

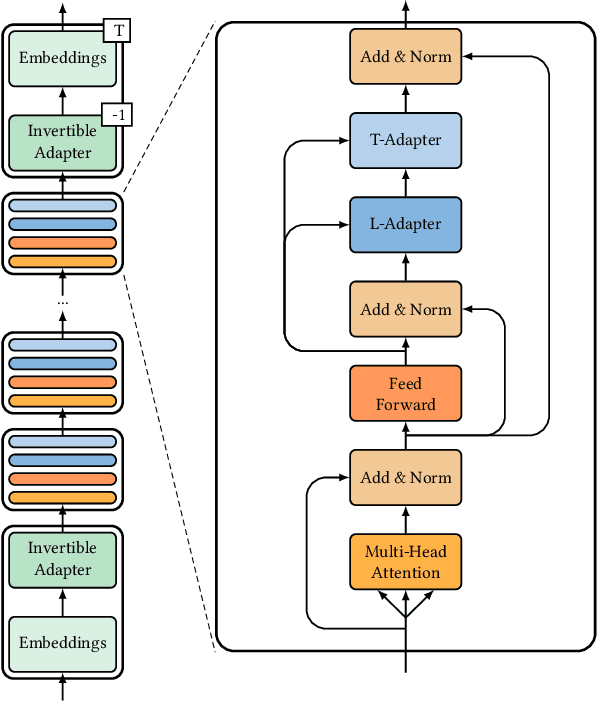
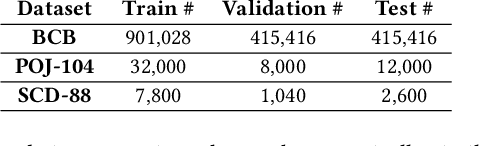
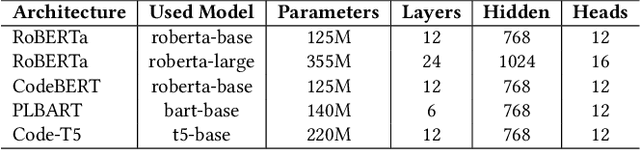
Pre-trained neural Language Models (PTLM), such as CodeBERT, are recently used in software engineering as models pre-trained on large source code corpora. Their knowledge is transferred to downstream tasks (e.g. code clone detection) via fine-tuning. In natural language processing (NLP), other alternatives for transferring the knowledge of PTLMs are explored through using adapters, compact, parameter efficient modules inserted in the layers of the PTLM. Although adapters are known to facilitate adapting to many downstream tasks compared to fine-tuning the model that require retraining all of the models' parameters -- which owes to the adapters' plug and play nature and being parameter efficient -- their usage in software engineering is not explored. Here, we explore the knowledge transfer using adapters and based on the Naturalness Hypothesis proposed by Hindle et. al \cite{hindle2016naturalness}. Thus, studying the bimodality of adapters for two tasks of cloze test and code clone detection, compared to their benchmarks from the CodeXGLUE platform. These adapters are trained using programming languages and are inserted in a PTLM that is pre-trained on English corpora (N-PTLM). Three programming languages, C/C++, Python, and Java, are studied along with extensive experiments on the best setup used for adapters. Improving the results of the N-PTLM confirms the success of the adapters in knowledge transfer to software engineering, which sometimes are in par with or exceed the results of a PTLM trained on source code; while being more efficient in terms of the number of parameters, memory usage, and inference time. Our results can open new directions to build smaller models for more software engineering tasks. We open source all the scripts and the trained adapters.
On the Effectiveness of Pretrained Models for API Learning
Apr 05, 2022


Developers frequently use APIs to implement certain functionalities, such as parsing Excel Files, reading and writing text files line by line, etc. Developers can greatly benefit from automatic API usage sequence generation based on natural language queries for building applications in a faster and cleaner manner. Existing approaches utilize information retrieval models to search for matching API sequences given a query or use RNN-based encoder-decoder to generate API sequences. As it stands, the first approach treats queries and API names as bags of words. It lacks deep comprehension of the semantics of the queries. The latter approach adapts a neural language model to encode a user query into a fixed-length context vector and generate API sequences from the context vector. We want to understand the effectiveness of recent Pre-trained Transformer based Models (PTMs) for the API learning task. These PTMs are trained on large natural language corpora in an unsupervised manner to retain contextual knowledge about the language and have found success in solving similar Natural Language Processing (NLP) problems. However, the applicability of PTMs has not yet been explored for the API sequence generation task. We use a dataset that contains 7 million annotations collected from GitHub to evaluate the PTMs empirically. This dataset was also used to assess previous approaches. Based on our results, PTMs generate more accurate API sequences and outperform other related methods by around 11%. We have also identified two different tokenization approaches that can contribute to a significant boost in PTMs' performance for the API sequence generation task.
* 12 pages, 4 figures, ICPC 2022
Pre-Trained Neural Language Models for Automatic Mobile App User Feedback Answer Generation
Feb 04, 2022



Studies show that developers' answers to the mobile app users' feedbacks on app stores can increase the apps' star rating. To help app developers generate answers that are related to the users' issues, recent studies develop models to generate the answers automatically. Aims: The app response generation models use deep neural networks and require training data. Pre-Trained neural language Models (PTM) used in Natural Language Processing (NLP) take advantage of the information they learned from a large corpora in an unsupervised manner, and can reduce the amount of required training data. In this paper, we evaluate PTMs to generate replies to the mobile app user feedbacks. Method: We train a Transformer model from scratch and fine-tune two PTMs to evaluate the generated responses, which are compared to RRGEN, a current app response model. We also evaluate the models with different portions of the training data. Results: The results on a large dataset evaluated by automatic metrics show that PTMs obtain lower scores than the baselines. However, our human evaluation confirms that PTMs can generate more relevant and meaningful responses to the posted feedbacks. Moreover, the performance of PTMs has less drop compared to other models when the amount of training data is reduced to 1/3. Conclusion: PTMs are useful in generating responses to app reviews and are more robust models to the amount of training data provided. However, the prediction time is 19X than RRGEN. This study can provide new avenues for research in adapting the PTMs for analyzing mobile app user feedbacks. Index Terms-mobile app user feedback analysis, neural pre-trained language models, automatic answer generation
Evaluating Pre-Trained Models for User Feedback Analysis in Software Engineering: A Study on Classification of App-Reviews
Apr 23, 2021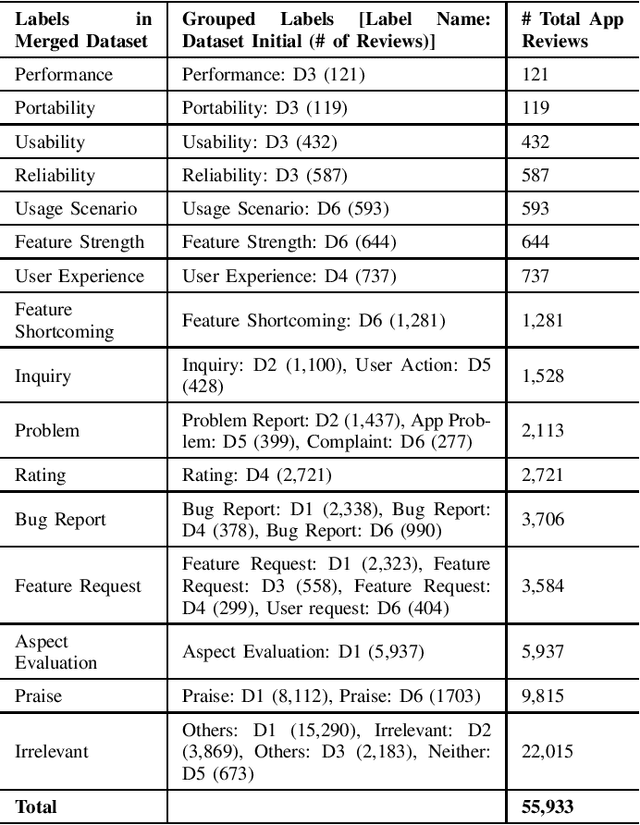
Context: Mobile app reviews written by users on app stores or social media are significant resources for app developers.Analyzing app reviews have proved to be useful for many areas of software engineering (e.g., requirement engineering, testing). Automatic classification of app reviews requires extensive efforts to manually curate a labeled dataset. When the classification purpose changes (e.g. identifying bugs versus usability issues or sentiment), new datasets should be labeled, which prevents the extensibility of the developed models for new desired classes/tasks in practice. Recent pre-trained neural language models (PTM) are trained on large corpora in an unsupervised manner and have found success in solving similar Natural Language Processing problems. However, the applicability of PTMs is not explored for app review classification Objective: We investigate the benefits of PTMs for app review classification compared to the existing models, as well as the transferability of PTMs in multiple settings. Method: We empirically study the accuracy and time efficiency of PTMs compared to prior approaches using six datasets from literature. In addition, we investigate the performance of the PTMs trained on app reviews (i.e. domain-specific PTMs) . We set up different studies to evaluate PTMs in multiple settings: binary vs. multi-class classification, zero-shot classification (when new labels are introduced to the model), multi-task setting, and classification of reviews from different resources. The datasets are manually labeled app review datasets from Google Play Store, Apple App Store, and Twitter data. In all cases, Micro and Macro Precision, Recall, and F1-scores will be used and we will report the time required for training and prediction with the models.