 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Pretrained Models for API Learning
Apr 05, 2022


Developers frequently use APIs to implement certain functionalities, such as parsing Excel Files, reading and writing text files line by line, etc. Developers can greatly benefit from automatic API usage sequence generation based on natural language queries for building applications in a faster and cleaner manner. Existing approaches utilize information retrieval models to search for matching API sequences given a query or use RNN-based encoder-decoder to generate API sequences. As it stands, the first approach treats queries and API names as bags of words. It lacks deep comprehension of the semantics of the queries. The latter approach adapts a neural language model to encode a user query into a fixed-length context vector and generate API sequences from the context vector. We want to understand the effectiveness of recent Pre-trained Transformer based Models (PTMs) for the API learning task. These PTMs are trained on large natural language corpora in an unsupervised manner to retain contextual knowledge about the language and have found success in solving similar Natural Language Processing (NLP) problems. However, the applicability of PTMs has not yet been explored for the API sequence generation task. We use a dataset that contains 7 million annotations collected from GitHub to evaluate the PTMs empirically. This dataset was also used to assess previous approaches. Based on our results, PTMs generate more accurate API sequences and outperform other related methods by around 11%. We have also identified two different tokenization approaches that can contribute to a significant boost in PTMs' performance for the API sequence generation task.
* 12 pages, 4 figures, ICPC 2022
Evaluating Pre-Trained Models for User Feedback Analysis in Software Engineering: A Study on Classification of App-Reviews
Apr 23, 2021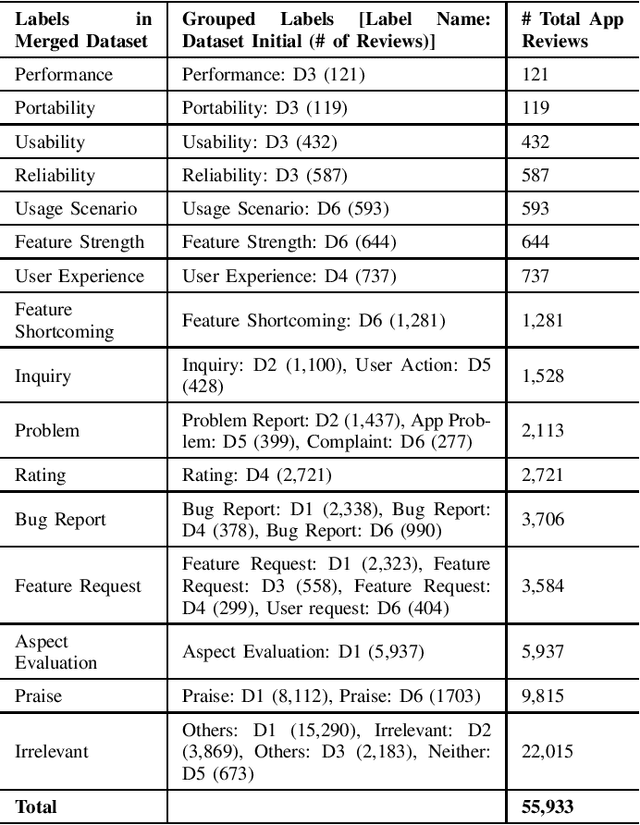
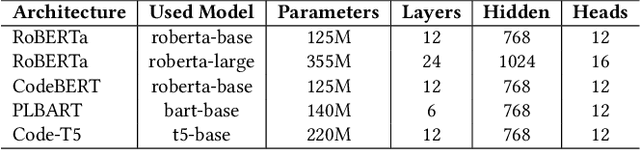
Context: Mobile app reviews written by users on app stores or social media are significant resources for app developers.Analyzing app reviews have proved to be useful for many areas of software engineering (e.g., requirement engineering, testing). Automatic classification of app reviews requires extensive efforts to manually curate a labeled dataset. When the classification purpose changes (e.g. identifying bugs versus usability issues or sentiment), new datasets should be labeled, which prevents the extensibility of the developed models for new desired classes/tasks in practice. Recent pre-trained neural language models (PTM) are trained on large corpora in an unsupervised manner and have found success in solving similar Natural Language Processing problems. However, the applicability of PTMs is not explored for app review classification Objective: We investigate the benefits of PTMs for app review classification compared to the existing models, as well as the transferability of PTMs in multiple settings. Method: We empirically study the accuracy and time efficiency of PTMs compared to prior approaches using six datasets from literature. In addition, we investigate the performance of the PTMs trained on app reviews (i.e. domain-specific PTMs) . We set up different studies to evaluate PTMs in multiple settings: binary vs. multi-class classification, zero-shot classification (when new labels are introduced to the model), multi-task setting, and classification of reviews from different resources. The datasets are manually labeled app review datasets from Google Play Store, Apple App Store, and Twitter data. In all cases, Micro and Macro Precision, Recall, and F1-scores will be used and we will report the time required for training and prediction with the models.
ReviewViz: Assisting Developers Perform Empirical Study on Energy Consumption Related Reviews for Mobile Applications
Sep 13, 2020
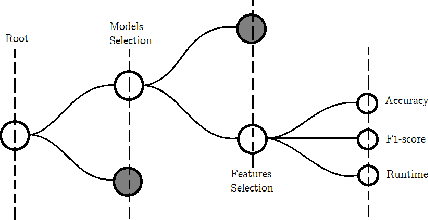
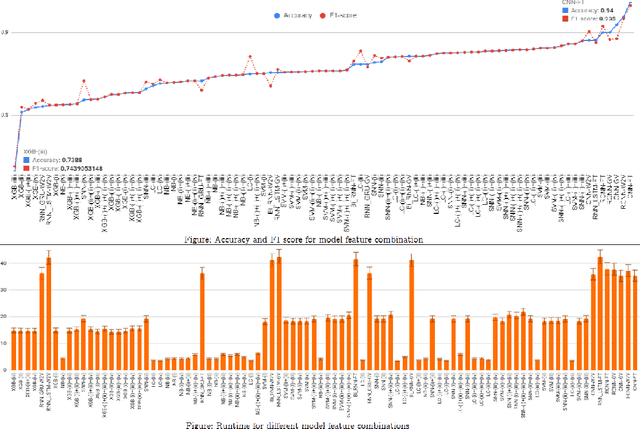
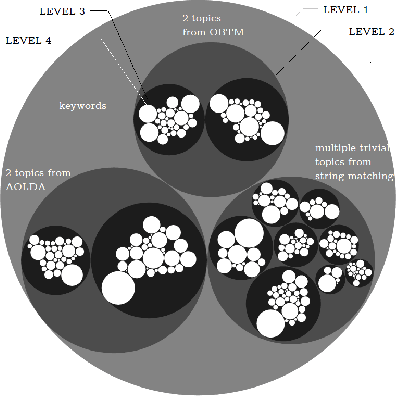
Improving the energy efficiency of mobile applications is a topic that has gained a lot of attention recently. It has been addressed in a number of ways such as identifying energy bugs and developing a catalog of energy patterns. Previous work shows that users discuss the battery-related issues (energy inefficiency or energy consumption) of the apps in their reviews. However, there is no work that addresses the automatic extraction of battery-related issues from users' feedback. In this paper, we report on a visualization tool that is developed to empirically study machine learning algorithms and text features to automatically identify the energy consumption specific reviews with the highest accuracy. Other than the common machine learning algorithms, we utilize deep learning models with different word embeddings to compare the results. Furthermore, to help the developers extract the main topics that are discussed in the reviews, two states of the art topic modeling algorithms are applied. The visualizations of the topics represent the keywords that are extracted for each topic along with a comparison with the results of string matching. The developed web-browser based interactive visualization tool is a novel framework developed with the intention of giving the app developers insights about running time and accuracy of machine learning and deep learning models as well as extracted topics. The tool makes it easier for the developers to traverse through the extensive result set generated by the text classification and topic modeling algorithms. The dynamic-data structure used for the tool stores the baseline-results of the discussed approaches and is updated when applied on new datasets. The tool is open-sourced to replicate the research results.
AOBTM: Adaptive Online Biterm Topic Modeling for Version Sensitive Short-texts Analysis
Sep 13, 2020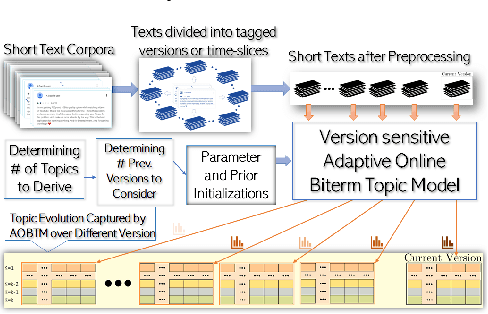
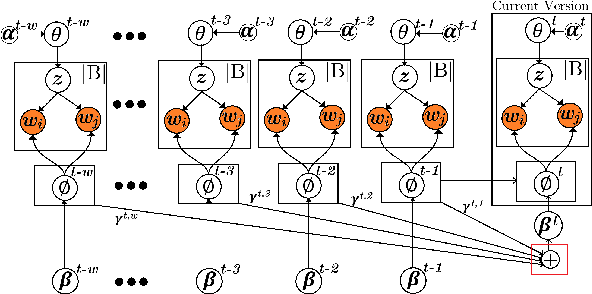
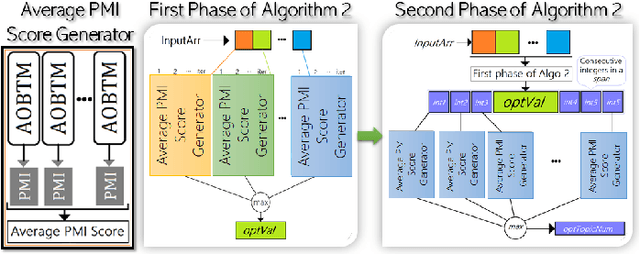
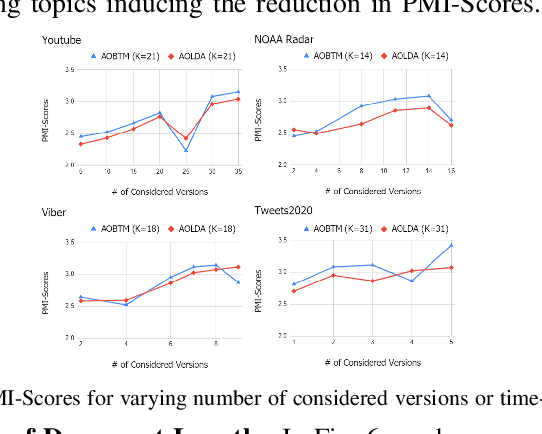
Analysis of mobile app reviews has shown its important role in requirement engineering, software maintenance and evolution of mobile apps. Mobile app developers check their users' reviews frequently to clarify the issues experienced by users or capture the new issues that are introduced due to a recent app update. App reviews have a dynamic nature and their discussed topics change over time. The changes in the topics among collected reviews for different versions of an app can reveal important issues about the app update. A main technique in this analysis is using topic modeling algorithms. However, app reviews are short texts and it is challenging to unveil their latent topics over time. Conventional topic models suffer from the sparsity of word co-occurrence patterns while inferring topics for short texts. Furthermore, these algorithms cannot capture topics over numerous consecutive time-slices. Online topic modeling algorithms speed up the inference of topic models for the texts collected in the latest time-slice by saving a fraction of data from the previous time-slice. But these algorithms do not analyze the statistical-data of all the previous time-slices, which can confer contributions to the topic distribution of the current time-slice. We propose Adaptive Online Biterm Topic Model (AOBTM) to model topics in short texts adaptively. AOBTM alleviates the sparsity problem in short-texts and considers the statistical-data for an optimal number of previous time-slices. We also propose parallel algorithms to automatically determine the optimal number of topics and the best number of previous versions that should be considered in topic inference phase. Automatic evaluation on collections of app reviews and real-world short text datasets confirm that AOBTM can find more coherent topics and outperforms the state-of-the-art baselines.