 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025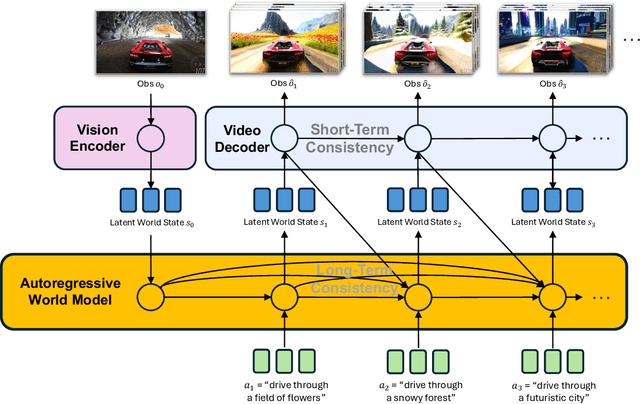
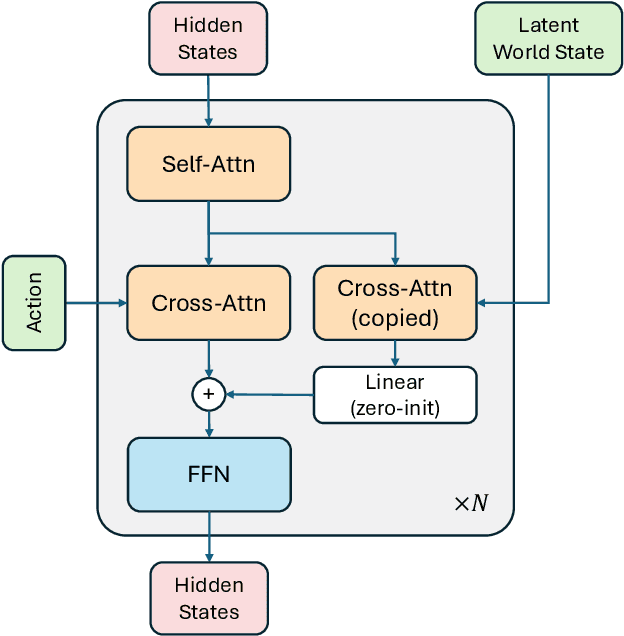
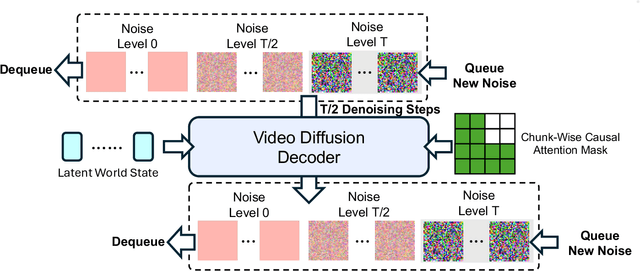
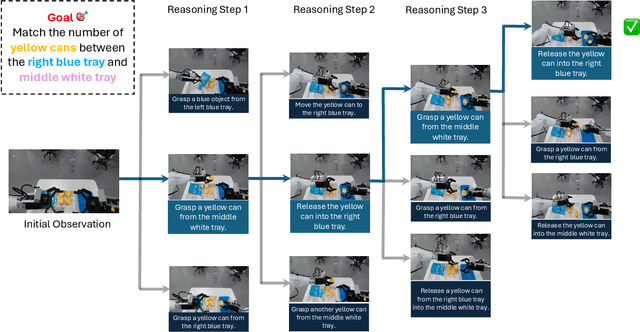
A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
ClarifyCoder: Clarification-Aware Fine-Tuning for Programmatic Problem Solving
Apr 23, 2025Large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, a significant gap remains between their current performance and that of expert software engineers. A key differentiator is that human engineers actively seek clarification when faced with ambiguous requirements, while LLMs typically generate code regardless of uncertainties in the problem description. We present ClarifyCoder, a novel framework with synthetic data generation and instruction-tuning that enables LLMs to identify ambiguities and request clarification before proceeding with code generation. While recent work has focused on LLM-based agents for iterative code generation, we argue that the fundamental ability to recognize and query ambiguous requirements should be intrinsic to the models themselves. Our approach consists of two main components: (1) a data synthesis technique that augments existing programming datasets with scenarios requiring clarification to generate clarification-aware training data, and (2) a fine-tuning strategy that teaches models to prioritize seeking clarification over immediate code generation when faced with incomplete or ambiguous requirements. We further provide an empirical analysis of integrating ClarifyCoder with standard fine-tuning for a joint optimization of both clarify-awareness and coding ability. Experimental results demonstrate that ClarifyCoder significantly improves the communication capabilities of Code LLMs through meaningful clarification dialogues while maintaining code generation capabilities.
StackRAG Agent: Improving Developer Answers with Retrieval-Augmented Generation
Jun 19, 2024Developers spend much time finding information that is relevant to their questions. Stack Overflow has been the leading resource, and with the advent of Large Language Models (LLMs), generative models such as ChatGPT are used frequently. However, there is a catch in using each one separately. Searching for answers is time-consuming and tedious, as shown by the many tools developed by researchers to address this issue. On the other, using LLMs is not reliable, as they might produce irrelevant or unreliable answers (i.e., hallucination). In this work, we present StackRAG, a retrieval-augmented Multiagent generation tool based on LLMs that combines the two worlds: aggregating the knowledge from SO to enhance the reliability of the generated answers. Initial evaluations show that the generated answers are correct, accurate, relevant, and useful.