 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClarifyCoder: Clarification-Aware Fine-Tuning for Programmatic Problem Solving
Apr 23, 2025Large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, a significant gap remains between their current performance and that of expert software engineers. A key differentiator is that human engineers actively seek clarification when faced with ambiguous requirements, while LLMs typically generate code regardless of uncertainties in the problem description. We present ClarifyCoder, a novel framework with synthetic data generation and instruction-tuning that enables LLMs to identify ambiguities and request clarification before proceeding with code generation. While recent work has focused on LLM-based agents for iterative code generation, we argue that the fundamental ability to recognize and query ambiguous requirements should be intrinsic to the models themselves. Our approach consists of two main components: (1) a data synthesis technique that augments existing programming datasets with scenarios requiring clarification to generate clarification-aware training data, and (2) a fine-tuning strategy that teaches models to prioritize seeking clarification over immediate code generation when faced with incomplete or ambiguous requirements. We further provide an empirical analysis of integrating ClarifyCoder with standard fine-tuning for a joint optimization of both clarify-awareness and coding ability. Experimental results demonstrate that ClarifyCoder significantly improves the communication capabilities of Code LLMs through meaningful clarification dialogues while maintaining code generation capabilities.
Survey on Code Generation for Low resource and Domain Specific Programming Languages
Oct 04, 2024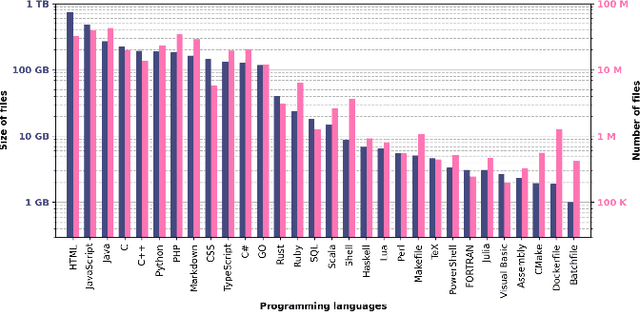
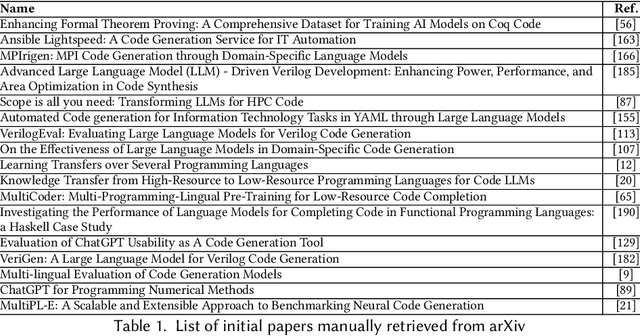
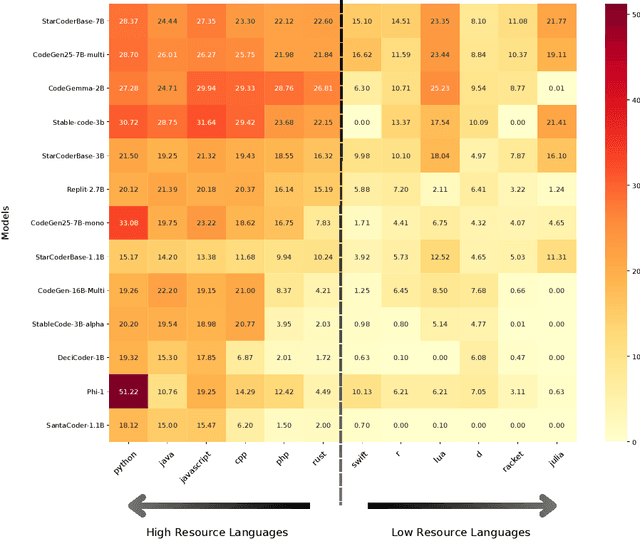

Large Language Models (LLMs) have shown impressive capabilities in code generation for popular programming languages. However, their performance on Low-Resource Programming Languages (LRPLs) and Domain-Specific Languages (DSLs) remains a significant challenge, affecting millions of developers-3.5 million users in Rust alone-who cannot fully utilize LLM capabilities. LRPLs and DSLs encounter unique obstacles, including data scarcity and, for DSLs, specialized syntax that is poorly represented in general-purpose datasets. Addressing these challenges is crucial, as LRPLs and DSLs enhance development efficiency in specialized domains, such as finance and science. While several surveys discuss LLMs in software engineering, none focus specifically on the challenges and opportunities associated with LRPLs and DSLs. Our survey fills this gap by systematically reviewing the current state, methodologies, and challenges in leveraging LLMs for code generation in these languages. We filtered 111 papers from over 27,000 published studies between 2020 and 2024 to evaluate the capabilities and limitations of LLMs in LRPLs and DSLs. We report the LLMs used, benchmarks, and metrics for evaluation, strategies for enhancing performance, and methods for dataset collection and curation. We identified four main evaluation techniques and several metrics for assessing code generation in LRPLs and DSLs. Our analysis categorizes improvement methods into six groups and summarizes novel architectures proposed by researchers. Despite various techniques and metrics, a standard approach and benchmark dataset for evaluating code generation in LRPLs and DSLs are lacking. This survey serves as a resource for researchers and practitioners at the intersection of LLMs, software engineering, and specialized programming languages, laying the groundwork for future advancements in code generation for LRPLs and DSLs.
MergeRepair: An Exploratory Study on Merging Task-Specific Adapters in Code LLMs for Automated Program Repair
Aug 18, 2024

[Context] Large Language Models (LLMs) have shown good performance in several software development-related tasks such as program repair, documentation, code refactoring, debugging, and testing. Adapters are specialized, small modules designed for parameter efficient fine-tuning of LLMs for specific tasks, domains, or applications without requiring extensive retraining of the entire model. These adapters offer a more efficient way to customize LLMs for particular needs, leveraging the pre-existing capabilities of the large model. Merging LLMs and adapters has shown promising results for various natural language domains and tasks, enabling the use of the learned models and adapters without additional training for a new task. [Objective] This research proposes continual merging and empirically studies the capabilities of merged adapters in Code LLMs, specially for the Automated Program Repair (APR) task. The goal is to gain insights into whether and how merging task-specific adapters can affect the performance of APR. [Method] In our framework, MergeRepair, we plan to merge multiple task-specific adapters using three different merging methods and evaluate the performance of the merged adapter for the APR task. Particularly, we will employ two main merging scenarios for all three techniques, (i) merging using equal-weight averaging applied on parameters of different adapters, where all adapters are of equal importance; and (ii) our proposed approach, continual merging, in which we sequentially merge the task-specific adapters and the order and weight of merged adapters matter. By exploratory study of merging techniques, we will investigate the improvement and generalizability of merged adapters for APR. Through continual merging, we will explore the capability of merged adapters and the effect of task order, as it occurs in real-world software projects.
Investigating the Efficacy of Large Language Models for Code Clone Detection
Jan 30, 2024



Large Language Models (LLMs) have demonstrated remarkable success in various natural language processing and software engineering tasks, such as code generation. The LLMs are mainly utilized in the prompt-based zero/few-shot paradigm to guide the model in accomplishing the task. GPT-based models are one of the popular ones studied for tasks such as code comment generation or test generation. These tasks are `generative' tasks. However, there is limited research on the usage of LLMs for `non-generative' tasks such as classification using the prompt-based paradigm. In this preliminary exploratory study, we investigated the applicability of LLMs for Code Clone Detection (CCD), a non-generative task. By building a mono-lingual and cross-lingual CCD dataset derived from CodeNet, we first investigated two different prompts using ChatGPT to detect Type-4 code clones in Java-Java and Java-Ruby pairs in a zero-shot setting. We then conducted an analysis to understand the strengths and weaknesses of ChatGPT in CCD. ChatGPT surpasses the baselines in cross-language CCD attaining an F1-score of 0.877 and achieves comparable performance to fully fine-tuned models for mono-lingual CCD, with an F1-score of 0.878. Also, the prompt and the difficulty level of the problems has an impact on the performance of ChatGPT. Finally we provide insights and future directions based on our initial analysis
Does Asking Clarifying Questions Increases Confidence in Generated Code? On the Communication Skills of Large Language Models
Aug 25, 2023Large language models (LLMs) have significantly improved the ability to perform tasks in the field of code generation. However, there is still a gap between LLMs being capable coders and being top-tier software engineers. Based on the observation that top-level software engineers often ask clarifying questions to reduce ambiguity in both requirements and coding solutions, we argue that the same should be applied to LLMs for code generation tasks. By asking probing questions in various topics before generating the final code, the challenges of programming with LLMs, such as unclear intent specification, lack of computational thinking, and undesired code quality, may be alleviated. This, in turn, increases confidence in the generated code. In this work, we explore how to leverage better communication skills to achieve greater confidence in generated code. We propose a communication-centered process that uses an LLM-generated communicator to identify issues with high ambiguity or low confidence in problem descriptions and generated code. We then ask clarifying questions to obtain responses from users for refining the code.