 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Agents for Automated Program Repair in Ruby
Nov 06, 2025Automated Program Repair (APR) has advanced rapidly with Large Language Models (LLMs), but most existing methods remain computationally expensive, and focused on a small set of languages. Ruby, despite its widespread use in web development and the persistent challenges faced by its developers, has received little attention in APR research. In this paper, we introduce RAMP, a novel lightweight framework that formulates program repair as a feedback-driven, iterative process for Ruby. RAMP employs a team of collaborative agents that generate targeted tests, reflect on errors, and refine candidate fixes until a correct solution is found. Unlike prior approaches, RAMP is designed to avoid reliance on large multilingual repair databases or costly fine-tuning, instead operating directly on Ruby through lightweight prompting and test-driven feedback. Evaluation on the XCodeEval benchmark shows that RAMP achieves a pass@1 of 67% on Ruby, outper-forming prior approaches. RAMP converges quickly within five iterations, and ablation studies confirm that test generation and self-reflection are key drivers of its performance. Further analysis shows that RAMP is particularly effective at repairing wrong answers, compilation errors, and runtime errors. Our approach provides new insights into multi-agent repair strategies, and establishes a foundation for extending LLM-based debugging tools to under-studied languages.
MergeRepair: An Exploratory Study on Merging Task-Specific Adapters in Code LLMs for Automated Program Repair
Aug 18, 2024

[Context] Large Language Models (LLMs) have shown good performance in several software development-related tasks such as program repair, documentation, code refactoring, debugging, and testing. Adapters are specialized, small modules designed for parameter efficient fine-tuning of LLMs for specific tasks, domains, or applications without requiring extensive retraining of the entire model. These adapters offer a more efficient way to customize LLMs for particular needs, leveraging the pre-existing capabilities of the large model. Merging LLMs and adapters has shown promising results for various natural language domains and tasks, enabling the use of the learned models and adapters without additional training for a new task. [Objective] This research proposes continual merging and empirically studies the capabilities of merged adapters in Code LLMs, specially for the Automated Program Repair (APR) task. The goal is to gain insights into whether and how merging task-specific adapters can affect the performance of APR. [Method] In our framework, MergeRepair, we plan to merge multiple task-specific adapters using three different merging methods and evaluate the performance of the merged adapter for the APR task. Particularly, we will employ two main merging scenarios for all three techniques, (i) merging using equal-weight averaging applied on parameters of different adapters, where all adapters are of equal importance; and (ii) our proposed approach, continual merging, in which we sequentially merge the task-specific adapters and the order and weight of merged adapters matter. By exploratory study of merging techniques, we will investigate the improvement and generalizability of merged adapters for APR. Through continual merging, we will explore the capability of merged adapters and the effect of task order, as it occurs in real-world software projects.
Predicting Code Review Completion Time in Modern Code Review
Sep 30, 2021


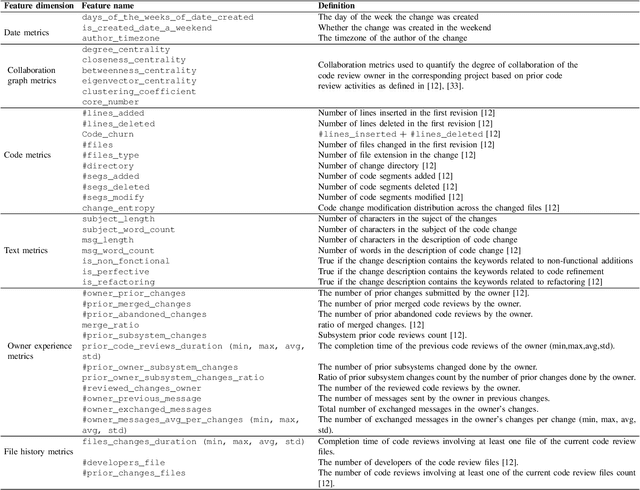
Context. Modern Code Review (MCR) is being adopted in both open source and commercial projects as a common practice. MCR is a widely acknowledged quality assurance practice that allows early detection of defects as well as poor coding practices. It also brings several other benefits such as knowledge sharing, team awareness, and collaboration. Problem. In practice, code reviews can experience significant delays to be completed due to various socio-technical factors which can affect the project quality and cost. For a successful review process, peer reviewers should perform their review tasks in a timely manner while providing relevant feedback about the code change being reviewed. However, there is a lack of tool support to help developers estimating the time required to complete a code review prior to accepting or declining a review request. Objective. Our objective is to build and validate an effective approach to predict the code review completion time in the context of MCR and help developers better manage and prioritize their code review tasks. Method. We formulate the prediction of the code review completion time as a learning problem. In particular, we propose a framework based on regression models to (i) effectively estimate the code review completion time, and (ii) understand the main factors influencing code review completion time.
How We Refactor and How We Document it? On the Use of Supervised Machine Learning Algorithms to Classify Refactoring Documentation
Oct 26, 2020



Refactoring is the art of improving the design of a system without altering its external behavior. Refactoring has become a well established and disciplined software engineering practice that has attracted a significant amount of research presuming that refactoring is primarily motivated by the need to improve system structures. However, recent studies have shown that developers may incorporate refactorings in other development activities that go beyond improving the design. Unfortunately, these studies are limited to developer interviews and a reduced set of projects. To cope with the above-mentioned limitations, we aim to better understand what motivates developers to apply refactoring by mining and classifying a large set of 111,884 commits containing refactorings, extracted from 800 Java projects. We trained a multi-class classifier to categorize these commits into 3 categories, namely, Internal QA, External QA, and Code Smell Resolution, along with the traditional BugFix and Functional categories. This classification challenges the original definition of refactoring, being exclusive to improving the design and fixing code smells. Further, to better understand our classification results, we analyzed commit messages to extract textual patterns that developers regularly use to describe their refactorings. The results show that (1) fixing code smells is not the main driver for developers to refactoring their codebases. Refactoring is solicited for a wide variety of reasons, going beyond its traditional definition; (2) the distribution of refactorings differs between production and test files; (3) developers use several patterns to purposefully target refactoring; (4) the textual patterns, extracted from commit messages, provide better coverage for how developers document their refactorings.
Toward the Automatic Classification of Self-Affirmed Refactoring
Sep 19, 2020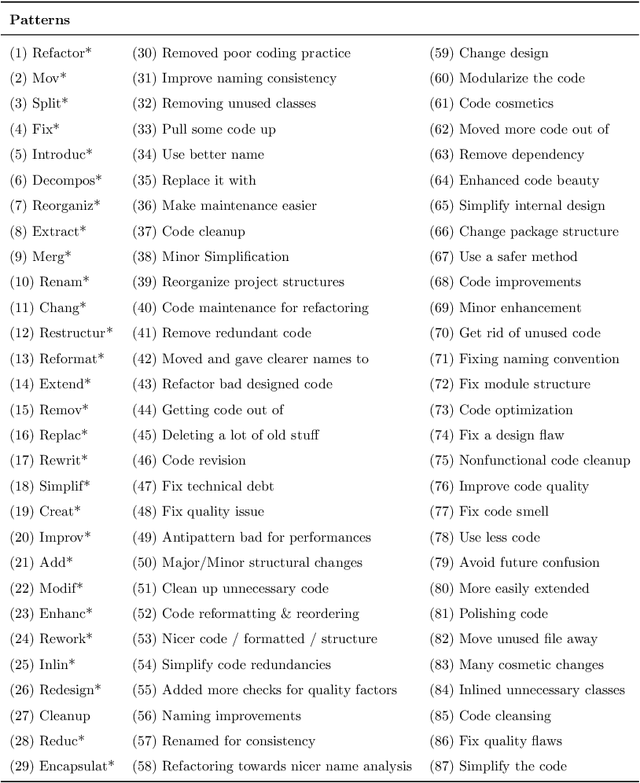

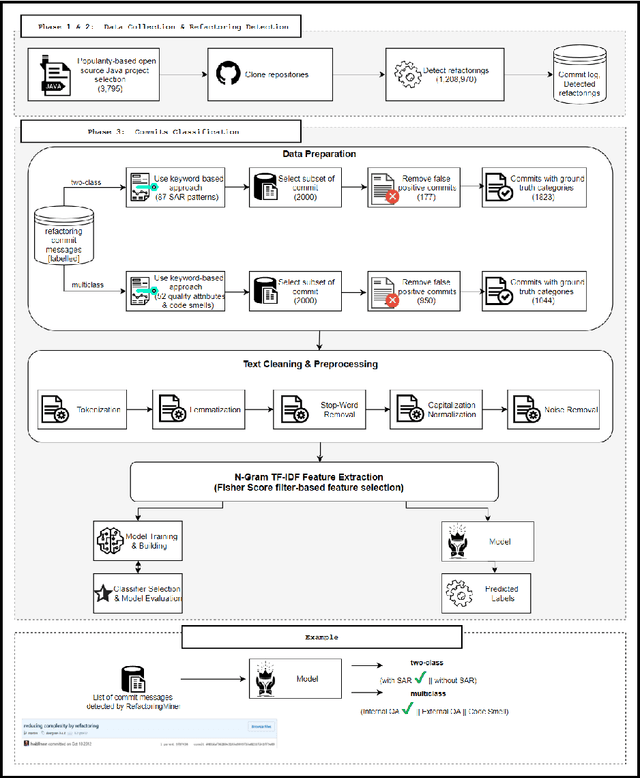
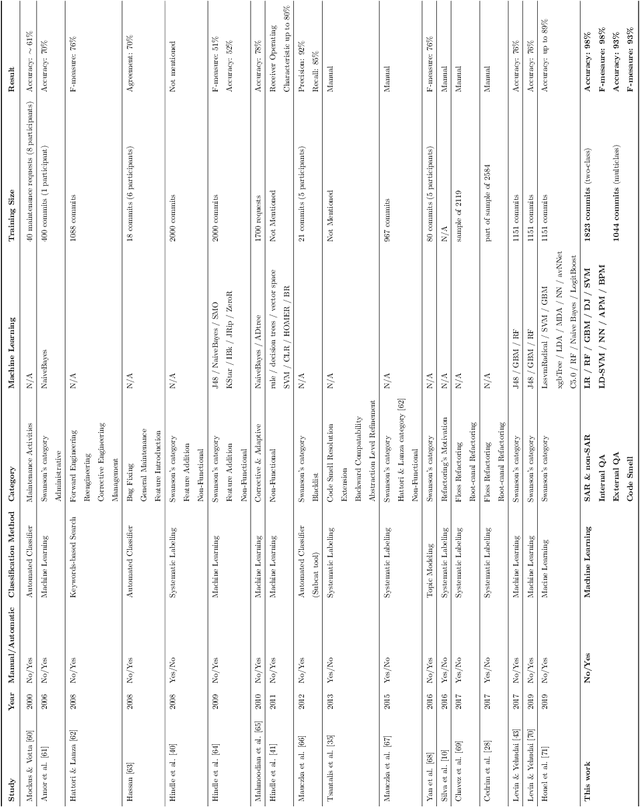
The concept of Self-Affirmed Refactoring (SAR) was introduced to explore how developers document their refactoring activities in commit messages, i.e., developers' explicit documentation of refactoring operations intentionally introduced during a code change. In our previous study, we have manually identified refactoring patterns and defined three main common quality improvement categories, including internal quality attributes, external quality attributes, and code smells, by only considering refactoring-related commits. However, this approach heavily depends on the manual inspection of commit messages. In this paper, we propose a two-step approach to first identify whether a commit describes developer-related refactoring events, then to classify it according to the refactoring common quality improvement categories. Specifically, we combine the N-Gram TF-IDF feature selection with binary and multiclass classifiers to build a new model to automate the classification of refactorings based on their quality improvement categories. We challenge our model using a total of 2,867 commit messages extracted from well-engineered open-source Java projects. Our findings show that (1) our model is able to accurately classify SAR commits, outperforming the pattern-based and random classifier approaches, and allowing the discovery of 40 more relevant SAR patterns, and (2) our model reaches an F-measure of up to 90% even with a relatively small training dataset.
Many-Objective Software Remodularization using NSGA-III
May 13, 2020



Software systems nowadays are complex and difficult to maintain due to continuous changes and bad design choices. To handle the complexity of systems, software products are, in general, decomposed in terms of packages/modules containing classes that are dependent. However, it is challenging to automatically remodularize systems to improve their maintainability. The majority of existing remodularization work mainly satisfy one objective which is improving the structure of packages by optimizing coupling and cohesion. In addition, most of existing studies are limited to only few operation types such as move class and split packages. Many other objectives, such as the design semantics, reducing the number of changes and maximizing the consistency with development change history, are important to improve the quality of the software by remodularizing it. In this paper, we propose a novel many-objective search-based approach using NSGA-III. The process aims at finding the optimal remodularization solutions that improve the structure of packages, minimize the number of changes, preserve semantics coherence, and re-use the history of changes. We evaluate the efficiency of our approach using four different open-source systems and one automotive industry project, provided by our industrial partner, through a quantitative and qualitative study conducted with software engineers.
* Mkaouer, Wiem, et al. "Many-objective software remodularization using NSGA-III." ACM Transactions on Software Engineering and Methodology (TOSEM) 24.3 (2015): 1-45
MigrationMiner: An Automated Detection Tool of Third-Party Java Library Migration at the Method Level
Jul 13, 2019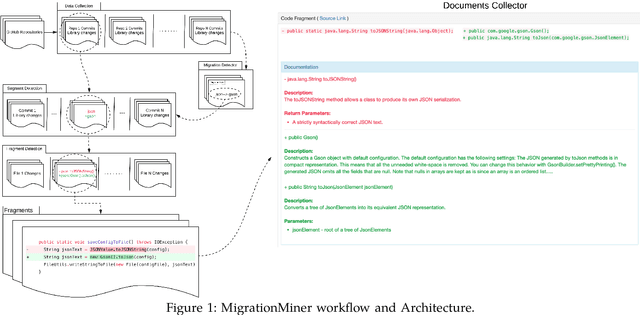
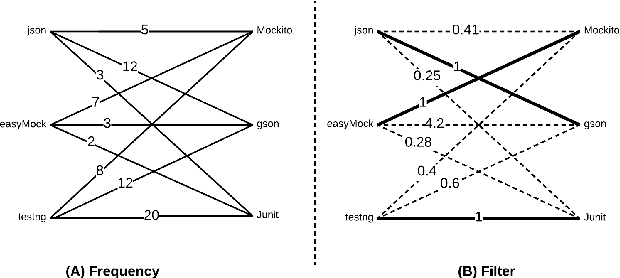


In this paper we introduce, MigrationMiner, an automated tool that detects code migrations performed between Java third-party library. Given a list of open source projects, the tool detects potential library migration code changes and collects the specific code fragments in which the developer replaces methods from the retired library with methods from the new library. To support the migration process, MigrationMiner collects the library documentation that is associated with every method involved in the migration. We evaluate our tool on a benchmark of manually validated library migrations. Results show that MigrationMiner achieves an accuracy of 100%. A demo video of MigrationMiner is available at https://youtu.be/sAlR1HNetXc.
Learning to Recommend Third-Party Library Migration Opportunities at the API Level
Jun 07, 2019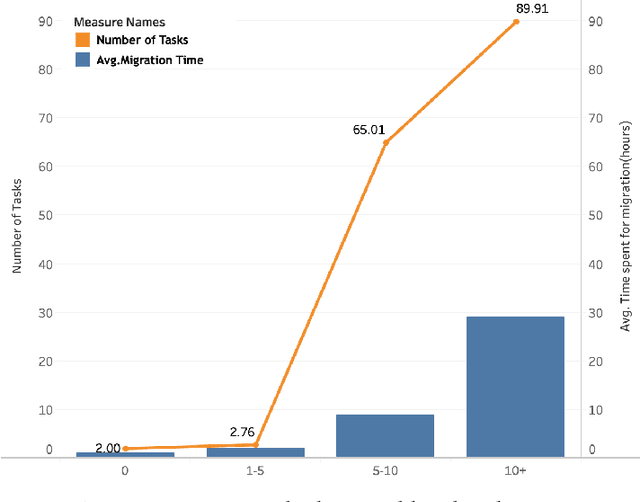
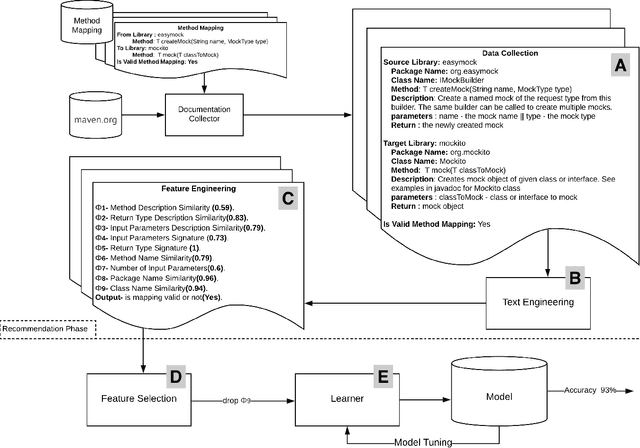
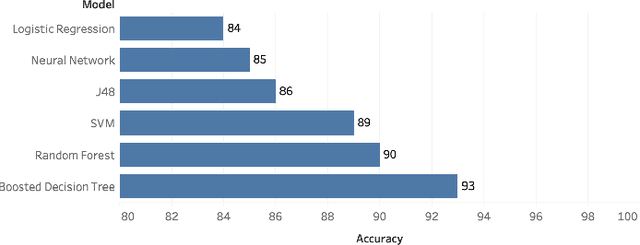
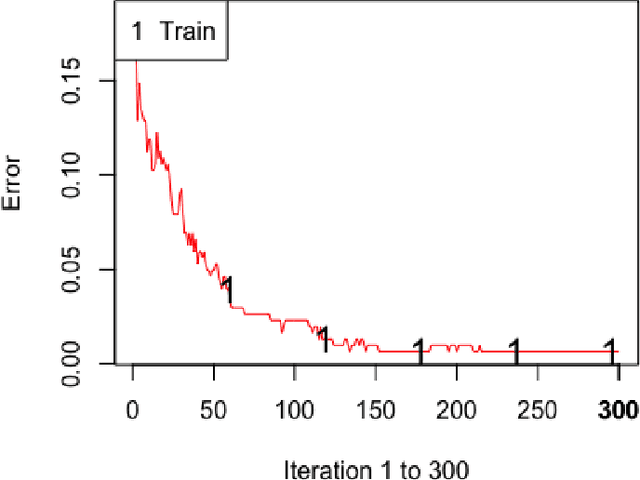
The manual migration between different third-party libraries represents a challenge for software developers. Developers typically need to explore both libraries Application Programming Interfaces, along with reading their documentation, in order to locate the suitable mappings between replacing and replaced methods. In this paper, we introduce RAPIM, a novel machine learning approach that recommends mappings between methods from two different libraries. Our model learns from previous migrations, manually performed in mined software systems, and extracts a set of features related to the similarity between method signatures and method textual documentation. We evaluate our model using 8 popular migrations, collected from 57,447 open-source Java projects. Results show that RAPIM is able to recommend relevant library API mappings with an average accuracy score of 87%. Finally, we provide the community with an API recommendation web service that could be used to support the migration process.