 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoRev: Automatic Peer Review System for Academic Research Papers
May 20, 2025Generating a review for an academic research paper is a complex task that requires a deep understanding of the document's content and the interdependencies between its sections. It demands not only insight into technical details but also an appreciation of the paper's overall coherence and structure. Recent methods have predominantly focused on fine-tuning large language models (LLMs) to address this challenge. However, they often overlook the computational and performance limitations imposed by long input token lengths. To address this, we introduce AutoRev, an Automatic Peer Review System for Academic Research Papers. Our novel framework represents an academic document as a graph, enabling the extraction of the most critical passages that contribute significantly to the review. This graph-based approach demonstrates effectiveness for review generation and is potentially adaptable to various downstream tasks, such as question answering, summarization, and document representation. When applied to review generation, our method outperforms SOTA baselines by an average of 58.72% across all evaluation metrics. We hope that our work will stimulate further research in applying graph-based extraction techniques to other downstream tasks in NLP. We plan to make our code public upon acceptance.
ClarifyCoder: Clarification-Aware Fine-Tuning for Programmatic Problem Solving
Apr 23, 2025Large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, a significant gap remains between their current performance and that of expert software engineers. A key differentiator is that human engineers actively seek clarification when faced with ambiguous requirements, while LLMs typically generate code regardless of uncertainties in the problem description. We present ClarifyCoder, a novel framework with synthetic data generation and instruction-tuning that enables LLMs to identify ambiguities and request clarification before proceeding with code generation. While recent work has focused on LLM-based agents for iterative code generation, we argue that the fundamental ability to recognize and query ambiguous requirements should be intrinsic to the models themselves. Our approach consists of two main components: (1) a data synthesis technique that augments existing programming datasets with scenarios requiring clarification to generate clarification-aware training data, and (2) a fine-tuning strategy that teaches models to prioritize seeking clarification over immediate code generation when faced with incomplete or ambiguous requirements. We further provide an empirical analysis of integrating ClarifyCoder with standard fine-tuning for a joint optimization of both clarify-awareness and coding ability. Experimental results demonstrate that ClarifyCoder significantly improves the communication capabilities of Code LLMs through meaningful clarification dialogues while maintaining code generation capabilities.
Towards Understanding the Robustness of LLM-based Evaluations under Perturbations
Dec 12, 2024
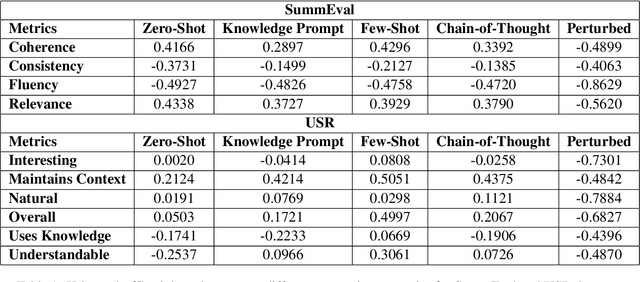
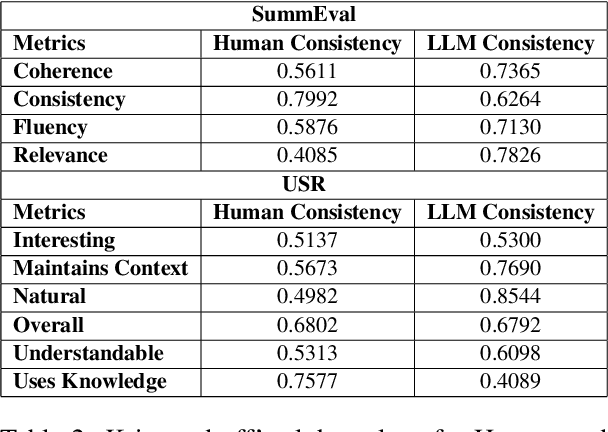
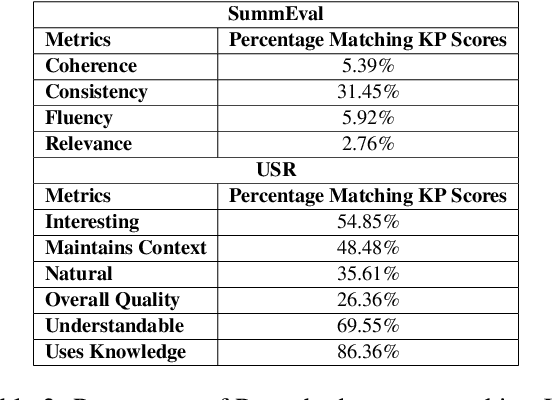
Traditional evaluation metrics like BLEU and ROUGE fall short when capturing the nuanced qualities of generated text, particularly when there is no single ground truth. In this paper, we explore the potential of Large Language Models (LLMs), specifically Google Gemini 1, to serve as automatic evaluators for non-standardized metrics in summarization and dialog-based tasks. We conduct experiments across multiple prompting strategies to examine how LLMs fare as quality evaluators when compared with human judgments on the SummEval and USR datasets, asking the model to generate both a score as well as a justification for the score. Furthermore, we explore the robustness of the LLM evaluator by using perturbed inputs. Our findings suggest that while LLMs show promise, their alignment with human evaluators is limited, they are not robust against perturbations and significant improvements are required for their standalone use as reliable evaluators for subjective metrics.
iREL at SemEval-2024 Task 9: Improving Conventional Prompting Methods for Brain Teasers
May 25, 2024
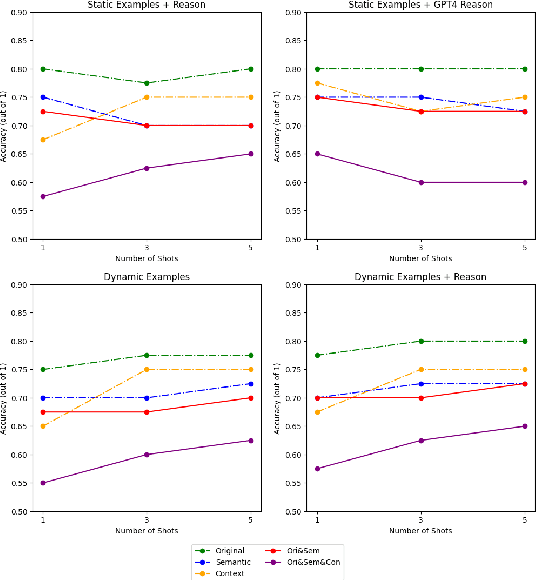
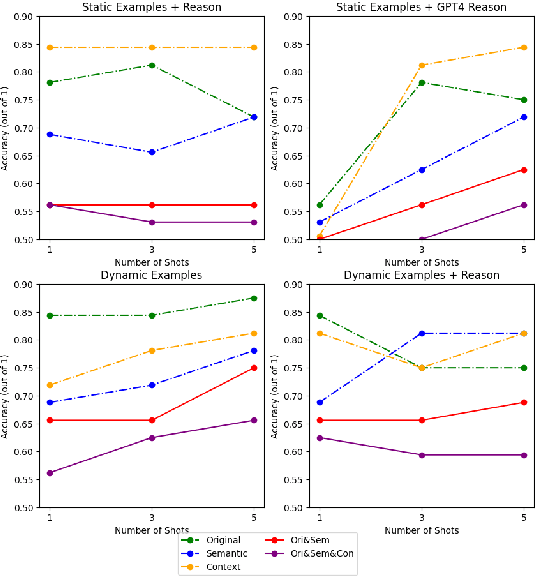
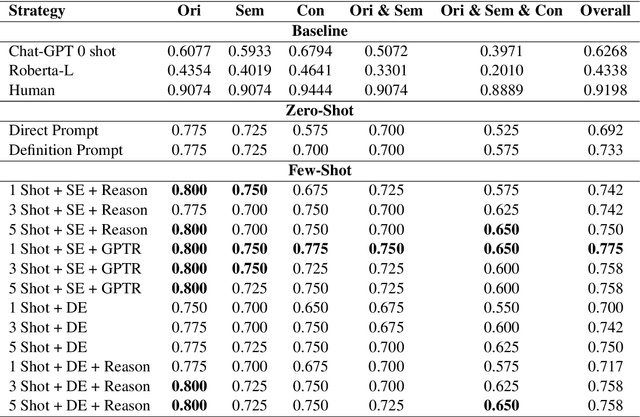
This paper describes our approach for SemEval-2024 Task 9: BRAINTEASER: A Novel Task Defying Common Sense. The BRAINTEASER task comprises multiple-choice Question Answering designed to evaluate the models' lateral thinking capabilities. It consists of Sentence Puzzle and Word Puzzle subtasks that require models to defy default common-sense associations and exhibit unconventional thinking. We propose a unique strategy to improve the performance of pre-trained language models, notably the Gemini 1.0 Pro Model, in both subtasks. We employ static and dynamic few-shot prompting techniques and introduce a model-generated reasoning strategy that utilizes the LLM's reasoning capabilities to improve performance. Our approach demonstrated significant improvements, showing that it performed better than the baseline models by a considerable margin but fell short of performing as well as the human annotators, thus highlighting the efficacy of the proposed strategies.
BrainStorm @ iREL at SMM4H 2024: Leveraging Translation and Topical Embeddings for Annotation Detection in Tweets
May 18, 2024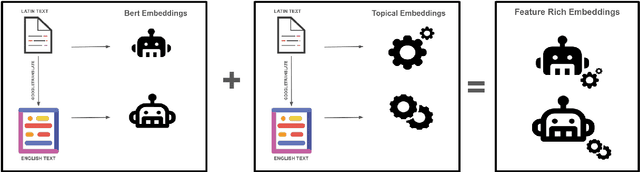
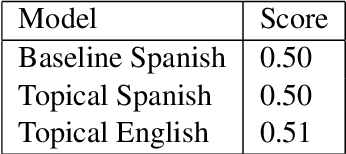
The proliferation of LLMs in various NLP tasks has sparked debates regarding their reliability, particularly in annotation tasks where biases and hallucinations may arise. In this shared task, we address the challenge of distinguishing annotations made by LLMs from those made by human domain experts in the context of COVID-19 symptom detection from tweets in Latin American Spanish. This paper presents BrainStorm @ iREL's approach to the SMM4H 2024 Shared Task, leveraging the inherent topical information in tweets, we propose a novel approach to identify and classify annotations, aiming to enhance the trustworthiness of annotated data.
iMETRE: Incorporating Markers of Entity Types for Relation Extraction
Jun 30, 2023Sentence-level relation extraction (RE) aims to identify the relationship between 2 entities given a contextual sentence. While there have been many attempts to solve this problem, the current solutions have a lot of room to improve. In this paper, we approach the task of relationship extraction in the financial dataset REFinD. Our approach incorporates typed entity markers representations and various models finetuned on the dataset, which has allowed us to achieve an F1 score of 69.65% on the validation set. Through this paper, we discuss various approaches and possible limitations.