Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrainStorm @ iREL at SMM4H 2024: Leveraging Translation and Topical Embeddings for Annotation Detection in Tweets
Paper and Code
May 18, 2024
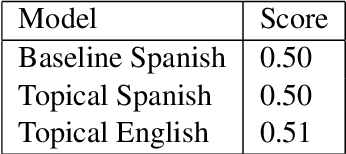
The proliferation of LLMs in various NLP tasks has sparked debates regarding their reliability, particularly in annotation tasks where biases and hallucinations may arise. In this shared task, we address the challenge of distinguishing annotations made by LLMs from those made by human domain experts in the context of COVID-19 symptom detection from tweets in Latin American Spanish. This paper presents BrainStorm @ iREL's approach to the SMM4H 2024 Shared Task, leveraging the inherent topical information in tweets, we propose a novel approach to identify and classify annotations, aiming to enhance the trustworthiness of annotated data.
* Submitted to SMM4H, colocated at ACL 2024
View paper on