 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding the Robustness of LLM-based Evaluations under Perturbations
Paper and Code
Dec 12, 2024
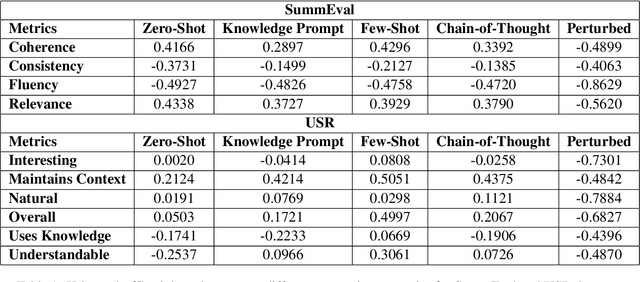
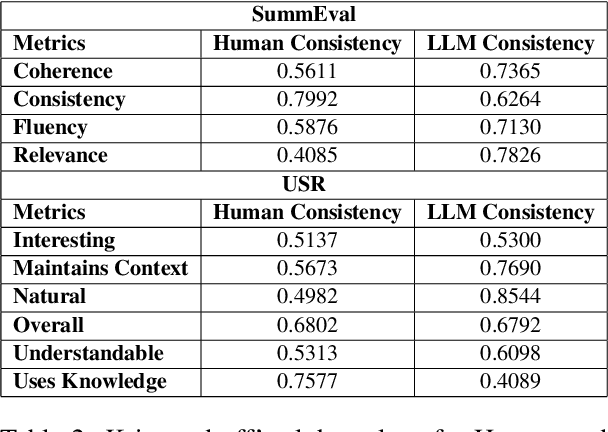
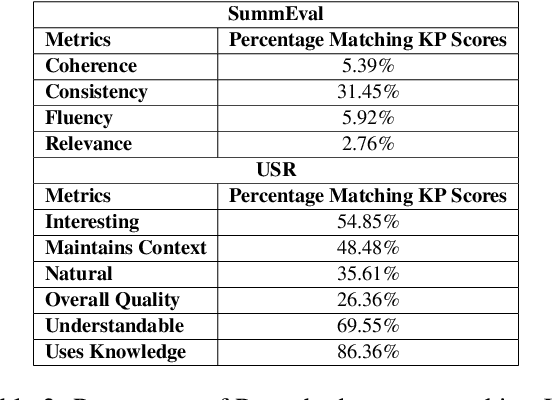
Traditional evaluation metrics like BLEU and ROUGE fall short when capturing the nuanced qualities of generated text, particularly when there is no single ground truth. In this paper, we explore the potential of Large Language Models (LLMs), specifically Google Gemini 1, to serve as automatic evaluators for non-standardized metrics in summarization and dialog-based tasks. We conduct experiments across multiple prompting strategies to examine how LLMs fare as quality evaluators when compared with human judgments on the SummEval and USR datasets, asking the model to generate both a score as well as a justification for the score. Furthermore, we explore the robustness of the LLM evaluator by using perturbed inputs. Our findings suggest that while LLMs show promise, their alignment with human evaluators is limited, they are not robust against perturbations and significant improvements are required for their standalone use as reliable evaluators for subjective metrics.