 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiREL at SemEval-2024 Task 9: Improving Conventional Prompting Methods for Brain Teasers
May 25, 2024
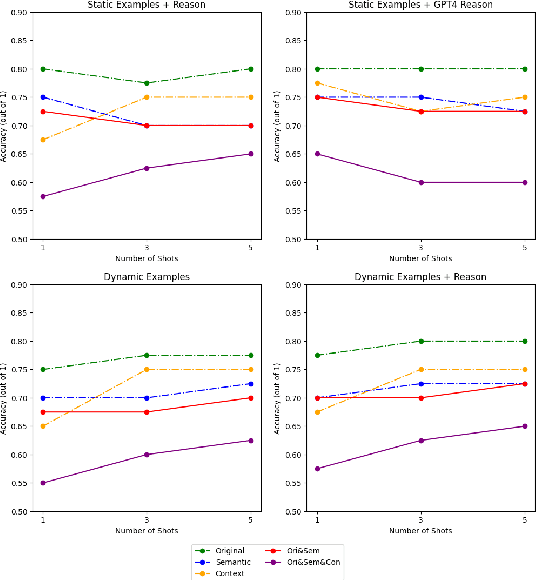
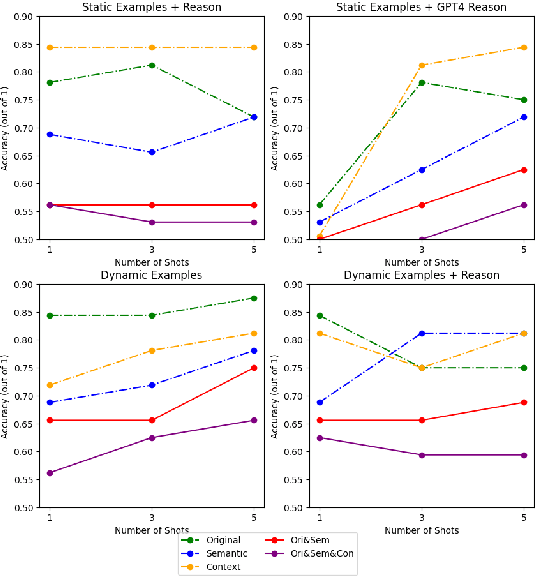
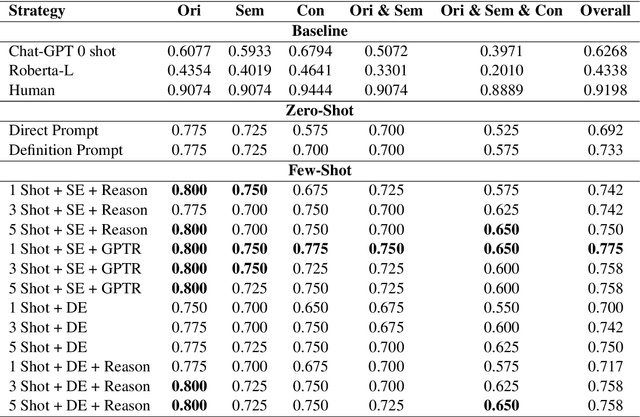
This paper describes our approach for SemEval-2024 Task 9: BRAINTEASER: A Novel Task Defying Common Sense. The BRAINTEASER task comprises multiple-choice Question Answering designed to evaluate the models' lateral thinking capabilities. It consists of Sentence Puzzle and Word Puzzle subtasks that require models to defy default common-sense associations and exhibit unconventional thinking. We propose a unique strategy to improve the performance of pre-trained language models, notably the Gemini 1.0 Pro Model, in both subtasks. We employ static and dynamic few-shot prompting techniques and introduce a model-generated reasoning strategy that utilizes the LLM's reasoning capabilities to improve performance. Our approach demonstrated significant improvements, showing that it performed better than the baseline models by a considerable margin but fell short of performing as well as the human annotators, thus highlighting the efficacy of the proposed strategies.
XWikiGen: Cross-lingual Summarization for Encyclopedic Text Generation in Low Resource Languages
Mar 22, 2023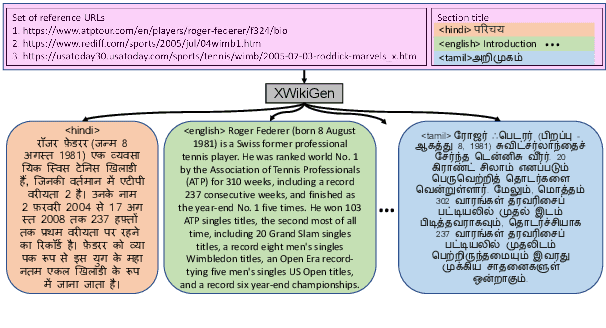

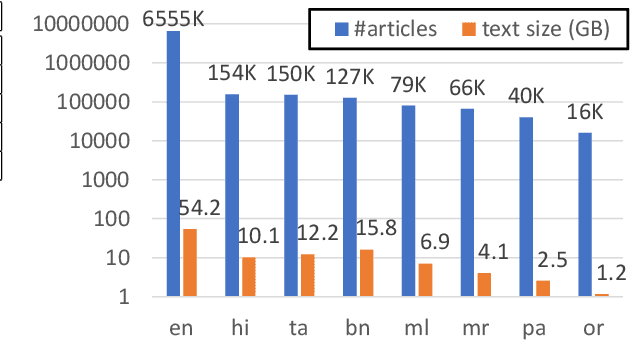

Lack of encyclopedic text contributors, especially on Wikipedia, makes automated text generation for \emph{low resource (LR) languages} a critical problem. Existing work on Wikipedia text generation has focused on \emph{English only} where English reference articles are summarized to generate English Wikipedia pages. But, for low-resource languages, the scarcity of reference articles makes monolingual summarization ineffective in solving this problem. Hence, in this work, we propose \task{}, which is the task of cross-lingual multi-document summarization of text from multiple reference articles, written in various languages, to generate Wikipedia-style text. Accordingly, we contribute a benchmark dataset, \data{}, spanning $\sim$69K Wikipedia articles covering five domains and eight languages. We harness this dataset to train a two-stage system where the input is a set of citations and a section title and the output is a section-specific LR summary. The proposed system is based on a novel idea of neural unsupervised extractive summarization to coarsely identify salient information followed by a neural abstractive model to generate the section-specific text. Extensive experiments show that multi-domain training is better than the multi-lingual setup on average.
Nostradamus: Weathering Worth
Dec 08, 2022Nostradamus, inspired by the French astrologer and reputed seer, is a detailed study exploring relations between environmental factors and changes in the stock market. In this paper, we analyze associative correlation and causation between environmental elements and stock prices based on the US financial market, global climate trends, and daily weather records to demonstrate significant relationships between climate and stock price fluctuation. Our analysis covers short and long-term rises and dips in company stock performances. Lastly, we take four natural disasters as a case study to observe their effect on the emotional state of people and their influence on the stock market.