 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarizing Indian Languages using Multilingual Transformers based Models
Mar 29, 2023

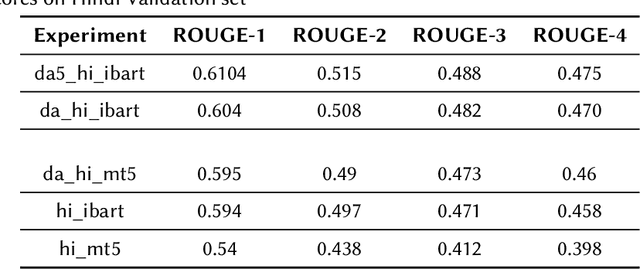

With the advent of multilingual models like mBART, mT5, IndicBART etc., summarization in low resource Indian languages is getting a lot of attention now a days. But still the number of datasets is low in number. In this work, we (Team HakunaMatata) study how these multilingual models perform on the datasets which have Indian languages as source and target text while performing summarization. We experimented with IndicBART and mT5 models to perform the experiments and report the ROUGE-1, ROUGE-2, ROUGE-3 and ROUGE-4 scores as a performance metric.
GrapeQA: GRaph Augmentation and Pruning to Enhance Question-Answering
Mar 22, 2023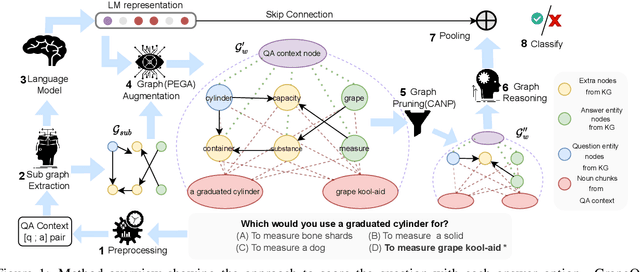
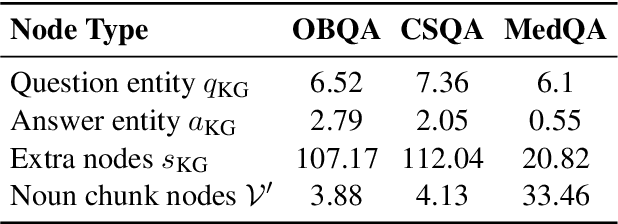
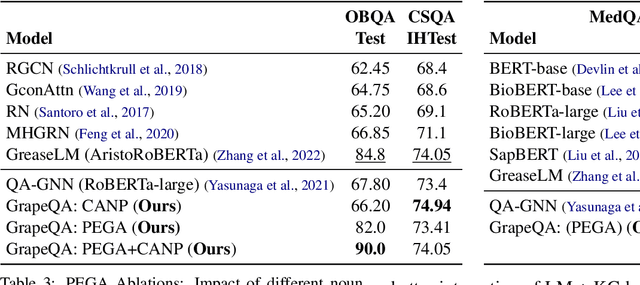

Commonsense question-answering (QA) methods combine the power of pre-trained Language Models (LM) with the reasoning provided by Knowledge Graphs (KG). A typical approach collects nodes relevant to the QA pair from a KG to form a Working Graph (WG) followed by reasoning using Graph Neural Networks(GNNs). This faces two major challenges: (i) it is difficult to capture all the information from the QA in the WG, and (ii) the WG contains some irrelevant nodes from the KG. To address these, we propose GrapeQA with two simple improvements on the WG: (i) Prominent Entities for Graph Augmentation identifies relevant text chunks from the QA pair and augments the WG with corresponding latent representations from the LM, and (ii) Context-Aware Node Pruning removes nodes that are less relevant to the QA pair. We evaluate our results on OpenBookQA, CommonsenseQA and MedQA-USMLE and see that GrapeQA shows consistent improvements over its LM + KG predecessor (QA-GNN in particular) and large improvements on OpenBookQA.
XWikiGen: Cross-lingual Summarization for Encyclopedic Text Generation in Low Resource Languages
Mar 22, 2023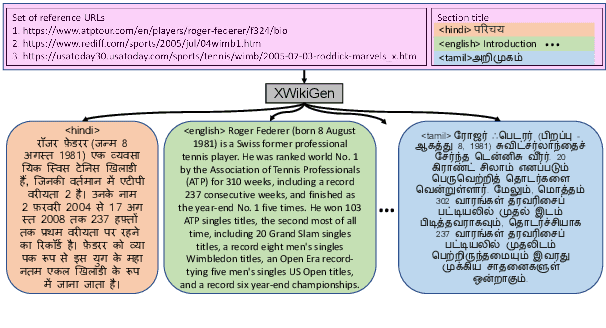

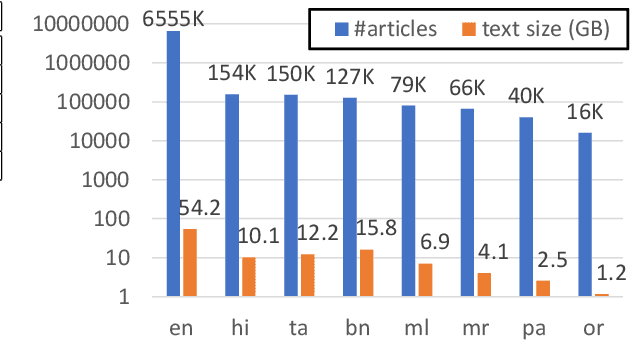

Lack of encyclopedic text contributors, especially on Wikipedia, makes automated text generation for \emph{low resource (LR) languages} a critical problem. Existing work on Wikipedia text generation has focused on \emph{English only} where English reference articles are summarized to generate English Wikipedia pages. But, for low-resource languages, the scarcity of reference articles makes monolingual summarization ineffective in solving this problem. Hence, in this work, we propose \task{}, which is the task of cross-lingual multi-document summarization of text from multiple reference articles, written in various languages, to generate Wikipedia-style text. Accordingly, we contribute a benchmark dataset, \data{}, spanning $\sim$69K Wikipedia articles covering five domains and eight languages. We harness this dataset to train a two-stage system where the input is a set of citations and a section title and the output is a section-specific LR summary. The proposed system is based on a novel idea of neural unsupervised extractive summarization to coarsely identify salient information followed by a neural abstractive model to generate the section-specific text. Extensive experiments show that multi-domain training is better than the multi-lingual setup on average.