 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-visual training for improved grounding in video-text LLMs
Jul 21, 2024



Recent advances in multimodal LLMs, have led to several video-text models being proposed for critical video-related tasks. However, most of the previous works support visual input only, essentially muting the audio signal in the video. Few models that support both audio and visual input, are not explicitly trained on audio data. Hence, the effect of audio towards video understanding is largely unexplored. To this end, we propose a model architecture that handles audio-visual inputs explicitly. We train our model with both audio and visual data from a video instruction-tuning dataset. Comparison with vision-only baselines, and other audio-visual models showcase that training on audio data indeed leads to improved grounding of responses. For better evaluation of audio-visual models, we also release a human-annotated benchmark dataset, with audio-aware question-answer pairs.
XWikiGen: Cross-lingual Summarization for Encyclopedic Text Generation in Low Resource Languages
Mar 22, 2023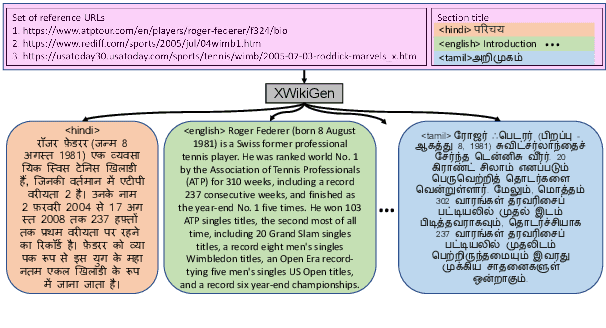

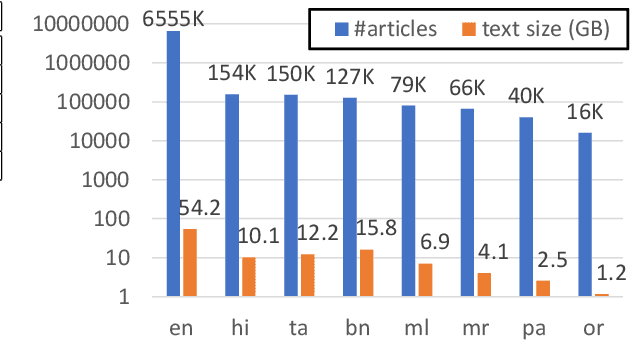

Lack of encyclopedic text contributors, especially on Wikipedia, makes automated text generation for \emph{low resource (LR) languages} a critical problem. Existing work on Wikipedia text generation has focused on \emph{English only} where English reference articles are summarized to generate English Wikipedia pages. But, for low-resource languages, the scarcity of reference articles makes monolingual summarization ineffective in solving this problem. Hence, in this work, we propose \task{}, which is the task of cross-lingual multi-document summarization of text from multiple reference articles, written in various languages, to generate Wikipedia-style text. Accordingly, we contribute a benchmark dataset, \data{}, spanning $\sim$69K Wikipedia articles covering five domains and eight languages. We harness this dataset to train a two-stage system where the input is a set of citations and a section title and the output is a section-specific LR summary. The proposed system is based on a novel idea of neural unsupervised extractive summarization to coarsely identify salient information followed by a neural abstractive model to generate the section-specific text. Extensive experiments show that multi-domain training is better than the multi-lingual setup on average.
XF2T: Cross-lingual Fact-to-Text Generation for Low-Resource Languages
Sep 22, 2022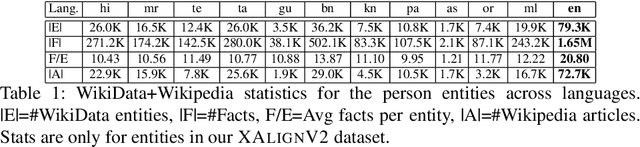
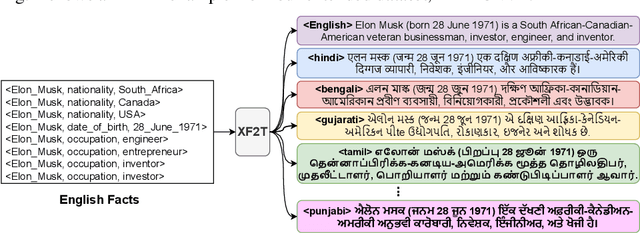
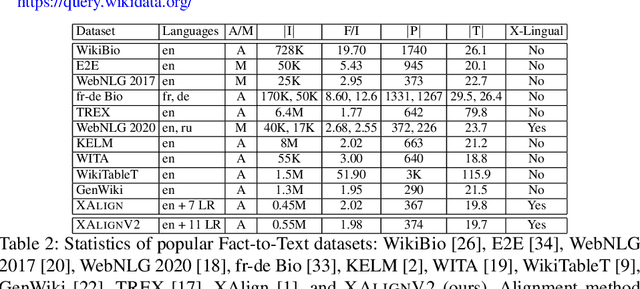
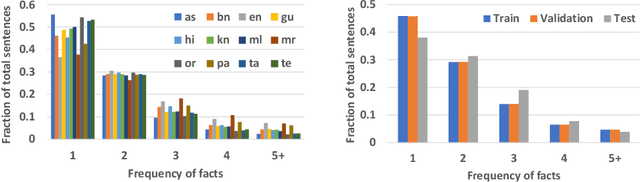
Multiple business scenarios require an automated generation of descriptive human-readable text from structured input data. Hence, fact-to-text generation systems have been developed for various downstream tasks like generating soccer reports, weather and financial reports, medical reports, person biographies, etc. Unfortunately, previous work on fact-to-text (F2T) generation has focused primarily on English mainly due to the high availability of relevant datasets. Only recently, the problem of cross-lingual fact-to-text (XF2T) was proposed for generation across multiple languages alongwith a dataset, XALIGN for eight languages. However, there has been no rigorous work on the actual XF2T generation problem. We extend XALIGN dataset with annotated data for four more languages: Punjabi, Malayalam, Assamese and Oriya. We conduct an extensive study using popular Transformer-based text generation models on our extended multi-lingual dataset, which we call XALIGNV2. Further, we investigate the performance of different text generation strategies: multiple variations of pretraining, fact-aware embeddings and structure-aware input encoding. Our extensive experiments show that a multi-lingual mT5 model which uses fact-aware embeddings with structure-aware input encoding leads to best results on average across the twelve languages. We make our code, dataset and model publicly available, and hope that this will help advance further research in this critical area.
XAlign: Cross-lingual Fact-to-Text Alignment and Generation for Low-Resource Languages
Feb 01, 2022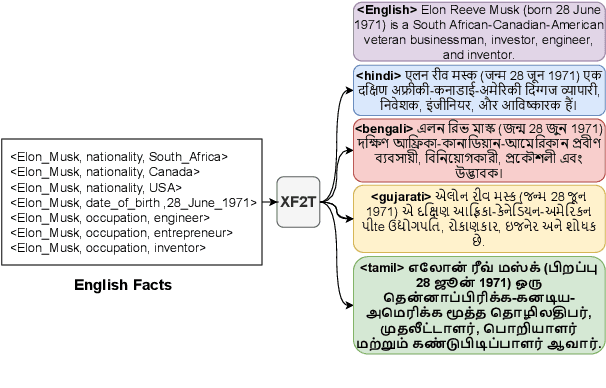
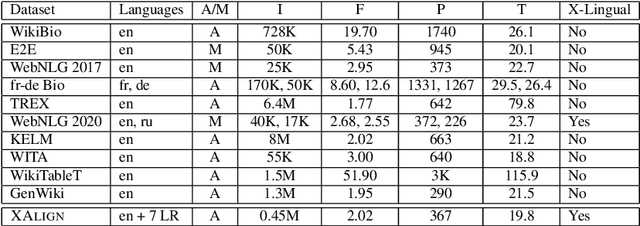
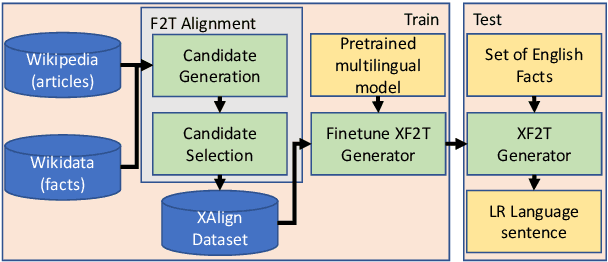
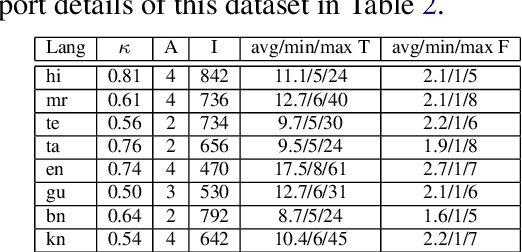
Multiple critical scenarios (like Wikipedia text generation given English Infoboxes) need automated generation of descriptive text in low resource (LR) languages from English fact triples. Previous work has focused on English fact-to-text (F2T) generation. To the best of our knowledge, there has been no previous attempt on cross-lingual alignment or generation for LR languages. Building an effective cross-lingual F2T (XF2T) system requires alignment between English structured facts and LR sentences. We propose two unsupervised methods for cross-lingual alignment. We contribute XALIGN, an XF2T dataset with 0.45M pairs across 8 languages, of which 5402 pairs have been manually annotated. We also train strong baseline XF2T generation models on the XAlign dataset.