 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLyrically Speaking: Exploring the Link Between Lyrical Emotions, Themes and Depression Risk
Aug 28, 2024



Lyrics play a crucial role in affecting and reinforcing emotional states by providing meaning and emotional connotations that interact with the acoustic properties of the music. Specific lyrical themes and emotions may intensify existing negative states in listeners and may lead to undesirable outcomes, especially in listeners with mood disorders such as depression. Hence, it is important for such individuals to be mindful of their listening strategies. In this study, we examine online music consumption of individuals at risk of depression in light of lyrical themes and emotions. Lyrics obtained from the listening histories of 541 Last.fm users, divided into At-Risk and No-Risk based on their mental well-being scores, were analyzed using natural language processing techniques. Statistical analyses of the results revealed that individuals at risk for depression prefer songs with lyrics associated with low valence and low arousal. Additionally, lyrics associated with themes of denial, self-reference, and ambivalence were preferred. In contrast, themes such as liberation, familiarity, and activity are not as favored. This study opens up the possibility of an approach to assessing depression risk from the digital footprint of individuals and potentially developing personalized recommendation systems.
Massively Multilingual Language Models for Cross Lingual Fact Extraction from Low Resource Indian Languages
Feb 09, 2023Massive knowledge graphs like Wikidata attempt to capture world knowledge about multiple entities. Recent approaches concentrate on automatically enriching these KGs from text. However a lot of information present in the form of natural text in low resource languages is often missed out. Cross Lingual Information Extraction aims at extracting factual information in the form of English triples from low resource Indian Language text. Despite its massive potential, progress made on this task is lagging when compared to Monolingual Information Extraction. In this paper, we propose the task of Cross Lingual Fact Extraction(CLFE) from text and devise an end-to-end generative approach for the same which achieves an overall F1 score of 77.46.
XF2T: Cross-lingual Fact-to-Text Generation for Low-Resource Languages
Sep 22, 2022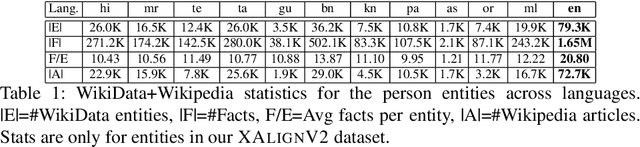
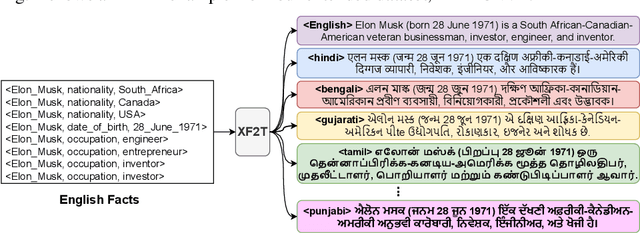
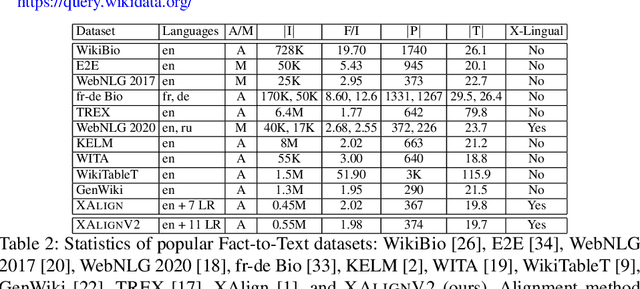
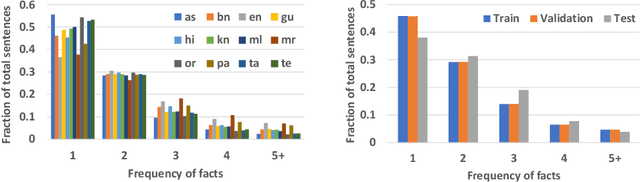
Multiple business scenarios require an automated generation of descriptive human-readable text from structured input data. Hence, fact-to-text generation systems have been developed for various downstream tasks like generating soccer reports, weather and financial reports, medical reports, person biographies, etc. Unfortunately, previous work on fact-to-text (F2T) generation has focused primarily on English mainly due to the high availability of relevant datasets. Only recently, the problem of cross-lingual fact-to-text (XF2T) was proposed for generation across multiple languages alongwith a dataset, XALIGN for eight languages. However, there has been no rigorous work on the actual XF2T generation problem. We extend XALIGN dataset with annotated data for four more languages: Punjabi, Malayalam, Assamese and Oriya. We conduct an extensive study using popular Transformer-based text generation models on our extended multi-lingual dataset, which we call XALIGNV2. Further, we investigate the performance of different text generation strategies: multiple variations of pretraining, fact-aware embeddings and structure-aware input encoding. Our extensive experiments show that a multi-lingual mT5 model which uses fact-aware embeddings with structure-aware input encoding leads to best results on average across the twelve languages. We make our code, dataset and model publicly available, and hope that this will help advance further research in this critical area.
XAlign: Cross-lingual Fact-to-Text Alignment and Generation for Low-Resource Languages
Feb 01, 2022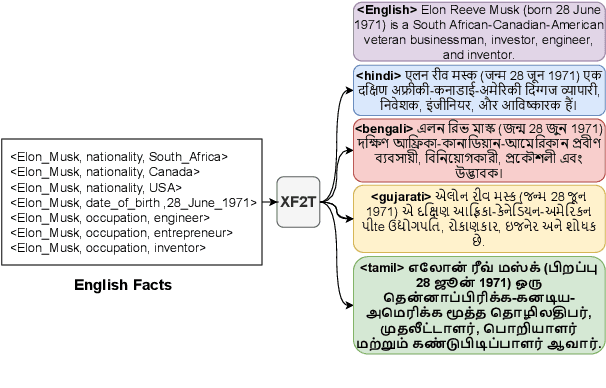
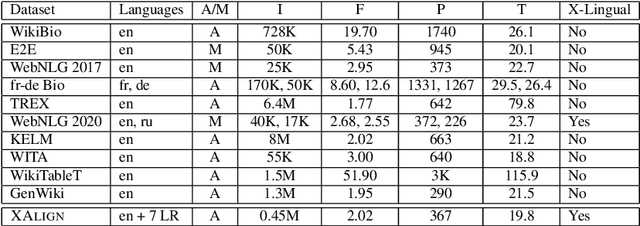
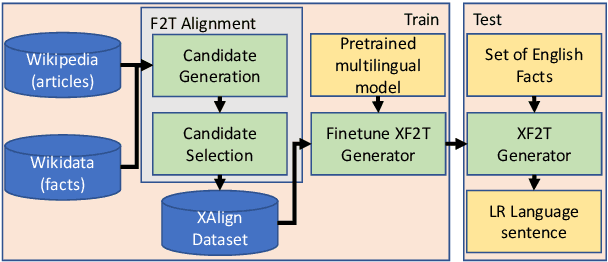
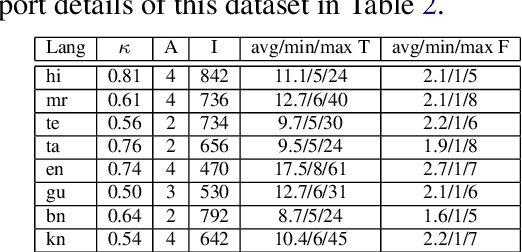
Multiple critical scenarios (like Wikipedia text generation given English Infoboxes) need automated generation of descriptive text in low resource (LR) languages from English fact triples. Previous work has focused on English fact-to-text (F2T) generation. To the best of our knowledge, there has been no previous attempt on cross-lingual alignment or generation for LR languages. Building an effective cross-lingual F2T (XF2T) system requires alignment between English structured facts and LR sentences. We propose two unsupervised methods for cross-lingual alignment. We contribute XALIGN, an XF2T dataset with 0.45M pairs across 8 languages, of which 5402 pairs have been manually annotated. We also train strong baseline XF2T generation models on the XAlign dataset.